 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-Grained Code-Switch Speech Translation with Semantic Space Alignment
Nov 09, 2025Code-switching (CS) speech translation (ST) refers to translating speech that alternates between two or more languages into a target language text, which poses significant challenges due to the complexity of semantic modeling and the scarcity of CS data. Previous studies tend to rely on the model itself to implicitly learn semantic modeling during training, and resort to inefficient and costly manual annotations for these two challenges. To mitigate these limitations, we propose enhancing Large Language Models (LLMs) with a Mixture of Experts (MoE) speech projector, where each expert specializes in the semantic subspace of a specific language, enabling fine-grained modeling of speech features. Additionally, we introduce a multi-stage training paradigm that utilizes readily available monolingual automatic speech recognition (ASR) and monolingual ST data, facilitating speech-text alignment and improving translation capabilities. During training, we leverage a combination of language-specific loss and intra-group load balancing loss to guide the MoE speech projector in efficiently allocating tokens to the appropriate experts, across expert groups and within each group, respectively. To bridge the data gap across different training stages and improve adaptation to the CS scenario, we further employ a transition loss, enabling smooth transitions of data between stages, to effectively address the scarcity of high-quality CS speech translation data. Extensive experiments on widely used datasets demonstrate the effectiveness and generality of our approach.
How Well Do Large Reasoning Models Translate? A Comprehensive Evaluation for Multi-Domain Machine Translation
May 26, 2025Large language models (LLMs) have demonstrated strong performance in general-purpose machine translation, but their effectiveness in complex, domain-sensitive translation tasks remains underexplored. Recent advancements in Large Reasoning Models (LRMs), raise the question of whether structured reasoning can enhance translation quality across diverse domains. In this work, we compare the performance of LRMs with traditional LLMs across 15 representative domains and four translation directions. Our evaluation considers various factors, including task difficulty, input length, and terminology density. We use a combination of automatic metrics and an enhanced MQM-based evaluation hierarchy to assess translation quality. Our findings show that LRMs consistently outperform traditional LLMs in semantically complex domains, especially in long-text and high-difficulty translation scenarios. Moreover, domain-adaptive prompting strategies further improve performance by better leveraging the reasoning capabilities of LRMs. These results highlight the potential of structured reasoning in MDMT tasks and provide valuable insights for optimizing translation systems in domain-sensitive contexts.
Efficient and Adaptive Simultaneous Speech Translation with Fully Unidirectional Architecture
Apr 16, 2025



Simultaneous speech translation (SimulST) produces translations incrementally while processing partial speech input. Although large language models (LLMs) have showcased strong capabilities in offline translation tasks, applying them to SimulST poses notable challenges. Existing LLM-based SimulST approaches either incur significant computational overhead due to repeated encoding of bidirectional speech encoder, or they depend on a fixed read/write policy, limiting the efficiency and performance. In this work, we introduce Efficient and Adaptive Simultaneous Speech Translation (EASiST) with fully unidirectional architecture, including both speech encoder and LLM. EASiST includes a multi-latency data curation strategy to generate semantically aligned SimulST training samples and redefines SimulST as an interleaved generation task with explicit read/write tokens. To facilitate adaptive inference, we incorporate a lightweight policy head that dynamically predicts read/write actions. Additionally, we employ a multi-stage training strategy to align speech-text modalities and optimize both translation and policy behavior. Experiments on the MuST-C En$\rightarrow$De and En$\rightarrow$Es datasets demonstrate that EASiST offers superior latency-quality trade-offs compared to several strong baselines.
LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline
Apr 13, 2025
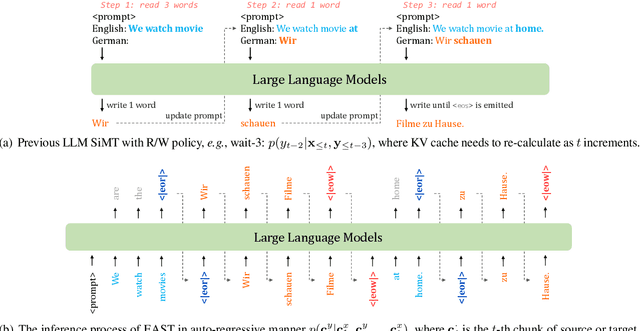
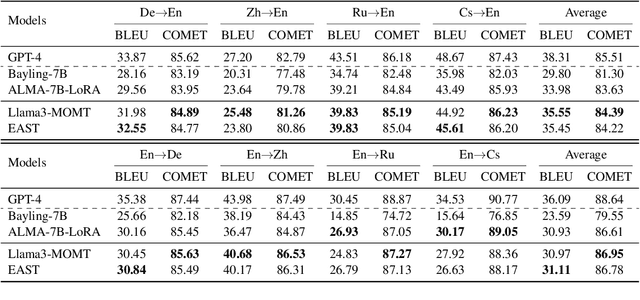
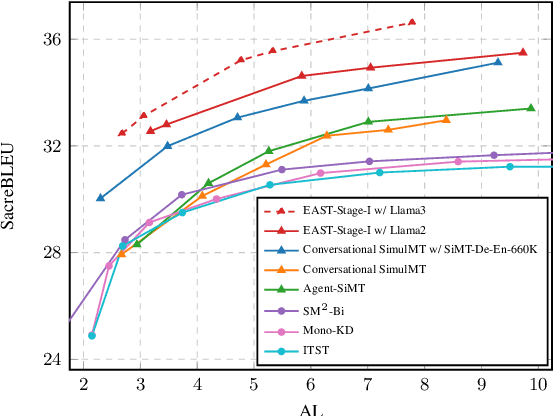
When the complete source sentence is provided, Large Language Models (LLMs) perform excellently in offline machine translation even with a simple prompt "Translate the following sentence from [src lang] into [tgt lang]:". However, in many real scenarios, the source tokens arrive in a streaming manner and simultaneous machine translation (SiMT) is required, then the efficiency and performance of decoder-only LLMs are significantly limited by their auto-regressive nature. To enable LLMs to achieve high-quality SiMT as efficiently as offline translation, we propose a novel paradigm that includes constructing supervised fine-tuning (SFT) data for SiMT, along with new training and inference strategies. To replicate the token input/output stream in SiMT, the source and target tokens are rearranged into an interleaved sequence, separated by special tokens according to varying latency requirements. This enables powerful LLMs to learn read and write operations adaptively, based on varying latency prompts, while still maintaining efficient auto-regressive decoding. Experimental results show that, even with limited SFT data, our approach achieves state-of-the-art performance across various SiMT benchmarks, and preserves the original abilities of offline translation. Moreover, our approach generalizes well to document-level SiMT setting without requiring specific fine-tuning, even beyond the offline translation model.
Representation Purification for End-to-End Speech Translation
Dec 05, 2024



Speech-to-text translation (ST) is a cross-modal task that involves converting spoken language into text in a different language. Previous research primarily focused on enhancing speech translation by facilitating knowledge transfer from machine translation, exploring various methods to bridge the gap between speech and text modalities. Despite substantial progress made, factors in speech that are not relevant to translation content, such as timbre and rhythm, often limit the efficiency of knowledge transfer. In this paper, we conceptualize speech representation as a combination of content-agnostic and content-relevant factors. We examine the impact of content-agnostic factors on translation performance through preliminary experiments and observe a significant performance deterioration when content-agnostic perturbations are introduced to speech signals. To address this issue, we propose a \textbf{S}peech \textbf{R}epresentation \textbf{P}urification with \textbf{S}upervision \textbf{E}nhancement (SRPSE) framework, which excludes the content-agnostic components within speech representations to mitigate their negative impact on ST. Experiments on MuST-C and CoVoST-2 datasets demonstrate that SRPSE significantly improves translation performance across all translation directions in three settings and achieves preeminent performance under a \textit{transcript-free} setting.
Application Research On Real-Time Perception Of Device Performance Status
Sep 05, 2024


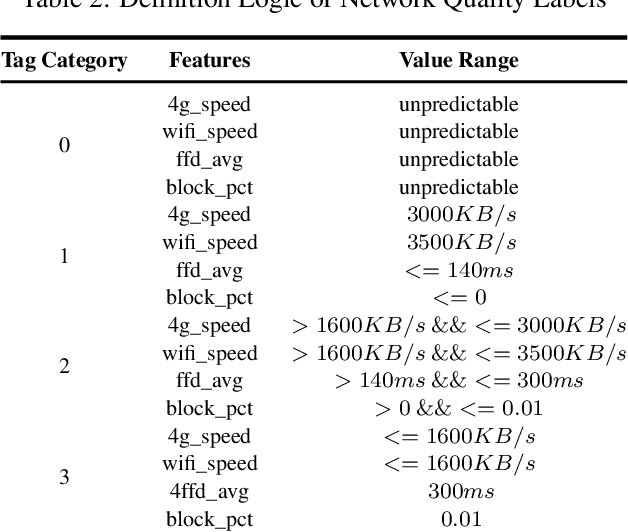
In order to accurately identify the performance status of mobile devices and finely adjust the user experience, a real-time performance perception evaluation method based on TOPSIS (Technique for Order Preference by Similarity to Ideal Solution) combined with entropy weighting method and time series model construction was studied. After collecting the performance characteristics of various mobile devices, the device performance profile was fitted by using PCA (principal component analysis) dimensionality reduction and feature engineering methods such as descriptive time series analysis. The ability of performance features and profiles to describe the real-time performance status of devices was understood and studied by applying the TOPSIS method and multi-level weighting processing. A time series model was constructed for the feature set under objective weighting, and multiple sensitivity (real-time, short-term, long-term) performance status perception results were provided to obtain real-time performance evaluation data and long-term stable performance prediction data. Finally, by configuring dynamic AB experiments and overlaying fine-grained power reduction strategies, the usability of the method was verified, and the accuracy of device performance status identification and prediction was compared with the performance of the profile features including dimensionality reduction time series modeling, TOPSIS method and entropy weighting method, subjective weighting, HMA method. The results show that accurate real-time performance perception results can greatly enhance business value, and this research has application effectiveness and certain forward-looking significance.
Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment
Dec 25, 2023



Sign language translation (SLT) aims to convert continuous sign language videos into textual sentences. As a typical multi-modal task, there exists an inherent modality gap between sign language videos and spoken language text, which makes the cross-modal alignment between visual and textual modalities crucial. However, previous studies tend to rely on an intermediate sign gloss representation to help alleviate the cross-modal problem thereby neglecting the alignment across modalities that may lead to compromised results. To address this issue, we propose a novel framework based on Conditional Variational autoencoder for SLT (CV-SLT) that facilitates direct and sufficient cross-modal alignment between sign language videos and spoken language text. Specifically, our CV-SLT consists of two paths with two Kullback-Leibler (KL) divergences to regularize the outputs of the encoder and decoder, respectively. In the prior path, the model solely relies on visual information to predict the target text; whereas in the posterior path, it simultaneously encodes visual information and textual knowledge to reconstruct the target text. The first KL divergence optimizes the conditional variational autoencoder and regularizes the encoder outputs, while the second KL divergence performs a self-distillation from the posterior path to the prior path, ensuring the consistency of decoder outputs. We further enhance the integration of textual information to the posterior path by employing a shared Attention Residual Gaussian Distribution (ARGD), which considers the textual information in the posterior path as a residual component relative to the prior path. Extensive experiments conducted on public datasets (PHOENIX14T and CSL-daily) demonstrate the effectiveness of our framework, achieving new state-of-the-art results while significantly alleviating the cross-modal representation discrepancy.
Layer-wise Representation Fusion for Compositional Generalization
Jul 20, 2023



Despite successes across a broad range of applications, sequence-to-sequence models' construct of solutions are argued to be less compositional than human-like generalization. There is mounting evidence that one of the reasons hindering compositional generalization is representations of the encoder and decoder uppermost layer are entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing token-level semantic information to alleviate the representations entanglement problem, rather than composing and using the syntactic and semantic representations of sequences appropriately as humans do. In addition, we explain why the entanglement problem exists from the perspective of recent studies about training deeper Transformer, mainly owing to the ``shallow'' residual connections and its simple, one-step operations, which fails to fuse previous layers' information effectively. Starting from this finding and inspired by humans' strategies, we propose \textsc{FuSion} (\textbf{Fu}sing \textbf{S}yntactic and Semant\textbf{i}c Representati\textbf{on}s), an extension to sequence-to-sequence models to learn to fuse previous layers' information back into the encoding and decoding process appropriately through introducing a \emph{fuse-attention module} at each encoder and decoder layer. \textsc{FuSion} achieves competitive and even \textbf{state-of-the-art} results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.
Learn to Compose Syntactic and Semantic Representations Appropriately for Compositional Generalization
May 20, 2023Recent studies have shown that sequence-to-sequence (Seq2Seq) models are limited in solving the compositional generalization (CG) tasks, failing to systematically generalize to unseen compositions of seen components. There is mounting evidence that one of the reasons hindering CG is the representation of the encoder uppermost layer is entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing semantic information at token-level, rather than composing the syntactic and semantic representations of sequences appropriately as humans do. In addition, we consider the representation entanglement problem they found is not comprehensive, and further hypothesize that source keys and values representations passing into different decoder layers are also entangled. Staring from this intuition and inspired by humans' strategies for CG, we propose COMPSITION (Compose Syntactic and Semantic Representations), an extension to Seq2Seq models to learn to compose representations of different encoder layers appropriately for generating different keys and values passing into different decoder layers through introducing a composed layer between the encoder and decoder. COMPSITION achieves competitive and even state-of-the-art results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.
CVT-SLR: Contrastive Visual-Textual Transformation for Sign Language Recognition with Variational Alignment
Mar 23, 2023



Sign language recognition (SLR) is a weakly supervised task that annotates sign videos as textual glosses. Recent studies show that insufficient training caused by the lack of large-scale available sign datasets becomes the main bottleneck for SLR. Most SLR works thereby adopt pretrained visual modules and develop two mainstream solutions. The multi-stream architectures extend multi-cue visual features, yielding the current SOTA performances but requiring complex designs and might introduce potential noise. Alternatively, the advanced single-cue SLR frameworks using explicit cross-modal alignment between visual and textual modalities are simple and effective, potentially competitive with the multi-cue framework. In this work, we propose a novel contrastive visual-textual transformation for SLR, CVT-SLR, to fully explore the pretrained knowledge of both the visual and language modalities. Based on the single-cue cross-modal alignment framework, we propose a variational autoencoder (VAE) for pretrained contextual knowledge while introducing the complete pretrained language module. The VAE implicitly aligns visual and textual modalities while benefiting from pretrained contextual knowledge as the traditional contextual module. Meanwhile, a contrastive cross-modal alignment algorithm is designed to explicitly enhance the consistency constraints. Extensive experiments on public datasets (PHOENIX-2014 and PHOENIX-2014T) demonstrate that our proposed CVT-SLR consistently outperforms existing single-cue methods and even outperforms SOTA multi-cue methods.