 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLSP-Emo: Towards Empathetic Large Speech-Language Models
Jun 06, 2024The recent release of GPT-4o showcased the potential of end-to-end multimodal models, not just in terms of low latency but also in their ability to understand and generate expressive speech with rich emotions. While the details are unknown to the open research community, it likely involves significant amounts of curated data and compute, neither of which is readily accessible. In this paper, we present BLSP-Emo (Bootstrapped Language-Speech Pretraining with Emotion support), a novel approach to developing an end-to-end speech-language model capable of understanding both semantics and emotions in speech and generate empathetic responses. BLSP-Emo utilizes existing speech recognition (ASR) and speech emotion recognition (SER) datasets through a two-stage process. The first stage focuses on semantic alignment, following recent work on pretraining speech-language models using ASR data. The second stage performs emotion alignment with the pretrained speech-language model on an emotion-aware continuation task constructed from SER data. Our experiments demonstrate that the BLSP-Emo model excels in comprehending speech and delivering empathetic responses, both in instruction-following tasks and conversations.
BLSP-KD: Bootstrapping Language-Speech Pre-training via Knowledge Distillation
May 29, 2024Recent end-to-end approaches have shown promise in extending large language models (LLMs) to speech inputs, but face limitations in directly assessing and optimizing alignment quality and fail to achieve fine-grained alignment due to speech-text length mismatch. We introduce BLSP-KD, a novel approach for Bootstrapping Language-Speech Pretraining via Knowledge Distillation, which addresses these limitations through two key techniques. First, it optimizes speech-text alignment by minimizing the divergence between the LLM's next-token prediction distributions for speech and text inputs using knowledge distillation. Second, it employs a continuous-integrate-andfire strategy to segment speech into tokens that correspond one-to-one with text tokens, enabling fine-grained alignment. We also introduce Partial LoRA (PLoRA), a new adaptation method supporting LLM finetuning for speech inputs under knowledge distillation. Quantitative evaluation shows that BLSP-KD outperforms previous end-to-end baselines and cascaded systems with comparable scale of parameters, facilitating general instruction-following capabilities for LLMs with speech inputs. This approach provides new possibilities for extending LLMs to spoken language interactions.
Adaptive Policy with Wait-$k$ Model for Simultaneous Translation
Oct 23, 2023



Simultaneous machine translation (SiMT) requires a robust read/write policy in conjunction with a high-quality translation model. Traditional methods rely on either a fixed wait-$k$ policy coupled with a standalone wait-$k$ translation model, or an adaptive policy jointly trained with the translation model. In this study, we propose a more flexible approach by decoupling the adaptive policy model from the translation model. Our motivation stems from the observation that a standalone multi-path wait-$k$ model performs competitively with adaptive policies utilized in state-of-the-art SiMT approaches. Specifically, we introduce DaP, a divergence-based adaptive policy, that makes read/write decisions for any translation model based on the potential divergence in translation distributions resulting from future information. DaP extends a frozen wait-$k$ model with lightweight parameters, and is both memory and computation efficient. Experimental results across various benchmarks demonstrate that our approach offers an improved trade-off between translation accuracy and latency, outperforming strong baselines.
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Sep 02, 2023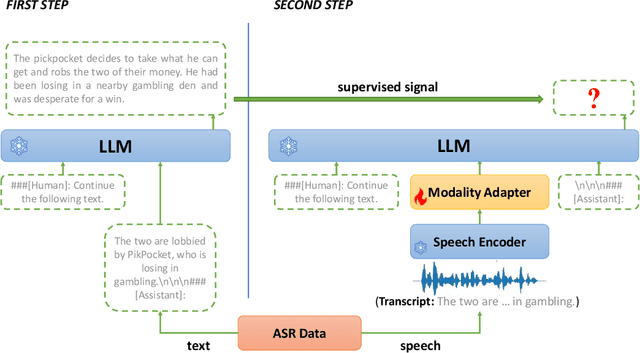


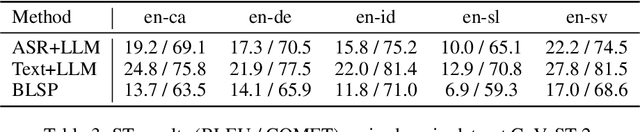
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
Improving Text Matching in E-Commerce Search with A Rationalizable, Intervenable and Fast Entity-Based Relevance Model
Jul 01, 2023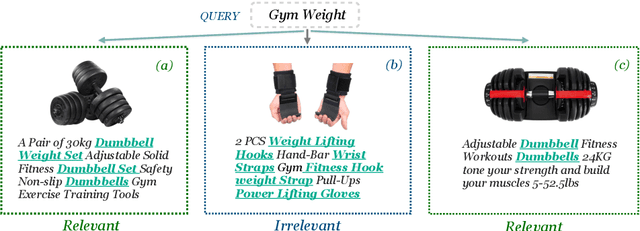

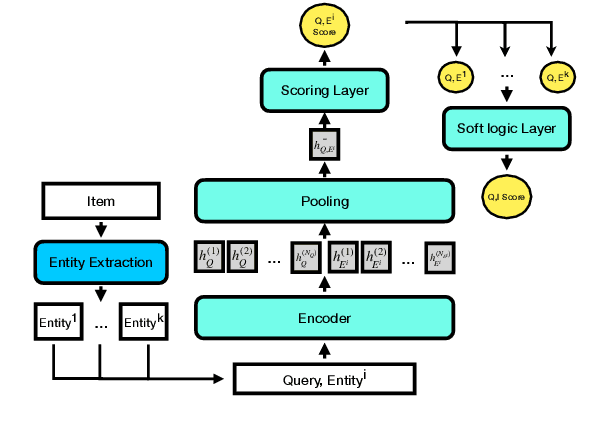
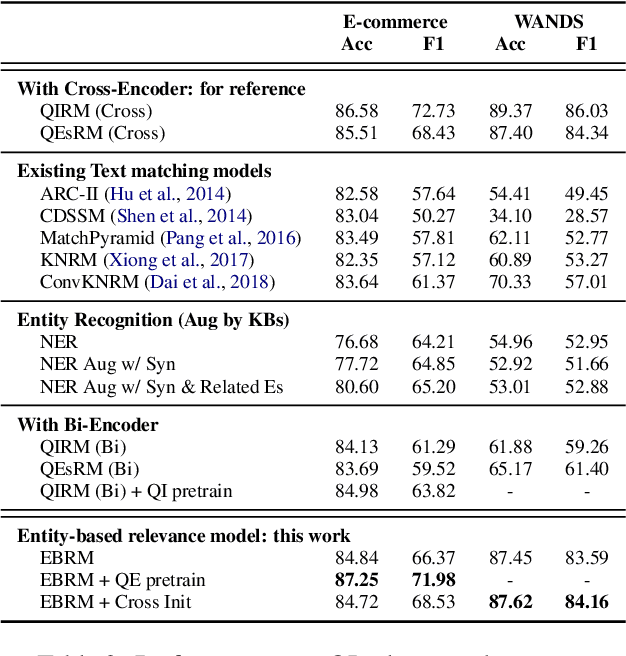
Discovering the intended items of user queries from a massive repository of items is one of the main goals of an e-commerce search system. Relevance prediction is essential to the search system since it helps improve performance. When online serving a relevance model, the model is required to perform fast and accurate inference. Currently, the widely used models such as Bi-encoder and Cross-encoder have their limitations in accuracy or inference speed respectively. In this work, we propose a novel model called the Entity-Based Relevance Model (EBRM). We identify the entities contained in an item and decompose the QI (query-item) relevance problem into multiple QE (query-entity) relevance problems; we then aggregate their results to form the QI prediction using a soft logic formulation. The decomposition allows us to use a Cross-encoder QE relevance module for high accuracy as well as cache QE predictions for fast online inference. Utilizing soft logic makes the prediction procedure interpretable and intervenable. We also show that pretraining the QE module with auto-generated QE data from user logs can further improve the overall performance. The proposed method is evaluated on labeled data from e-commerce websites. Empirical results show that it achieves promising improvements with computation efficiency.
Translate the Beauty in Songs: Jointly Learning to Align Melody and Translate Lyrics
Mar 28, 2023Song translation requires both translation of lyrics and alignment of music notes so that the resulting verse can be sung to the accompanying melody, which is a challenging problem that has attracted some interests in different aspects of the translation process. In this paper, we propose Lyrics-Melody Translation with Adaptive Grouping (LTAG), a holistic solution to automatic song translation by jointly modeling lyrics translation and lyrics-melody alignment. It is a novel encoder-decoder framework that can simultaneously translate the source lyrics and determine the number of aligned notes at each decoding step through an adaptive note grouping module. To address data scarcity, we commissioned a small amount of training data annotated specifically for this task and used large amounts of augmented data through back-translation. Experiments conducted on an English-Chinese song translation data set show the effectiveness of our model in both automatic and human evaluation.
Adapting Offline Speech Translation Models for Streaming with Future-Aware Distillation and Inference
Mar 14, 2023A popular approach to streaming speech translation is to employ a single offline model with a \textit{wait-$k$} policy to support different latency requirements, which is simpler than training multiple online models with different latency constraints. However, there is a mismatch problem in using a model trained with complete utterances for streaming inference with partial input. We demonstrate that speech representations extracted at the end of a streaming input are significantly different from those extracted from a complete utterance. To address this issue, we propose a new approach called Future-Aware Streaming Translation (FAST) that adapts an offline ST model for streaming input. FAST includes a Future-Aware Inference (FAI) strategy that incorporates future context through a trainable masked embedding, and a Future-Aware Distillation (FAD) framework that transfers future context from an approximation of full speech to streaming input. Our experiments on the MuST-C EnDe, EnEs, and EnFr benchmarks show that FAST achieves better trade-offs between translation quality and latency than strong baselines. Extensive analyses suggest that our methods effectively alleviate the aforementioned mismatch problem between offline training and online inference.
EnTDA: Entity-to-Text based Data Augmentation Approach for Named Entity Recognition Tasks
Oct 19, 2022
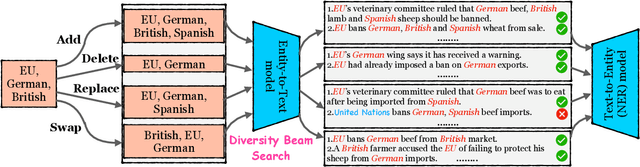
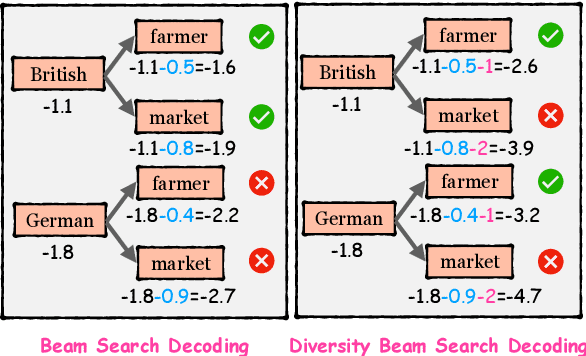
Data augmentation techniques have been used to improve the generalization capability of models in the named entity recognition (NER) tasks. Existing augmentation methods either manipulate the words in the original text that require hand-crafted in-domain knowledge, or leverage generative models which solicit dependency order among entities. To alleviate the excessive reliance on the dependency order among entities in existing augmentation paradigms, we develop an entity-to-text instead of text-to-entity based data augmentation method named: EnTDA to decouple the dependencies between entities by adding, deleting, replacing and swapping entities, and adopt these augmented data to bootstrap the generalization ability of the NER model. Furthermore, we introduce a diversity beam search to increase the diversity of the augmented data. Experiments on thirteen NER datasets across three tasks (flat NER, nested NER, and discontinuous NER) and two settings (full data NER and low resource NER) show that EnTDA could consistently outperform the baselines.
Discrete Cross-Modal Alignment Enables Zero-Shot Speech Translation
Oct 18, 2022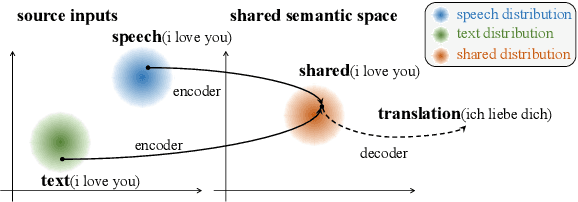
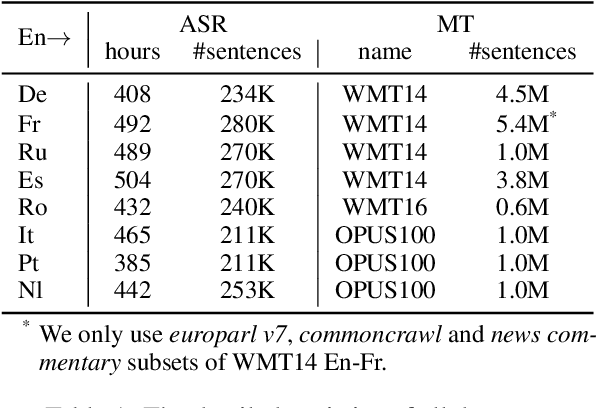
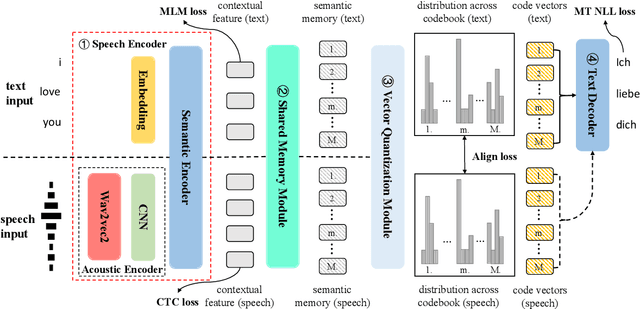
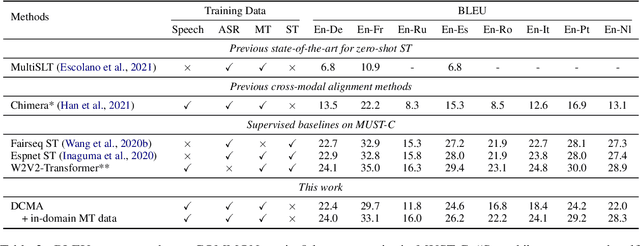
End-to-end Speech Translation (ST) aims at translating the source language speech into target language text without generating the intermediate transcriptions. However, the training of end-to-end methods relies on parallel ST data, which are difficult and expensive to obtain. Fortunately, the supervised data for automatic speech recognition (ASR) and machine translation (MT) are usually more accessible, making zero-shot speech translation a potential direction. Existing zero-shot methods fail to align the two modalities of speech and text into a shared semantic space, resulting in much worse performance compared to the supervised ST methods. In order to enable zero-shot ST, we propose a novel Discrete Cross-Modal Alignment (DCMA) method that employs a shared discrete vocabulary space to accommodate and match both modalities of speech and text. Specifically, we introduce a vector quantization module to discretize the continuous representations of speech and text into a finite set of virtual tokens, and use ASR data to map corresponding speech and text to the same virtual token in a shared codebook. This way, source language speech can be embedded in the same semantic space as the source language text, which can be then transformed into target language text with an MT module. Experiments on multiple language pairs demonstrate that our zero-shot ST method significantly improves the SOTA, and even performers on par with the strong supervised ST baselines.
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
Dec 13, 2021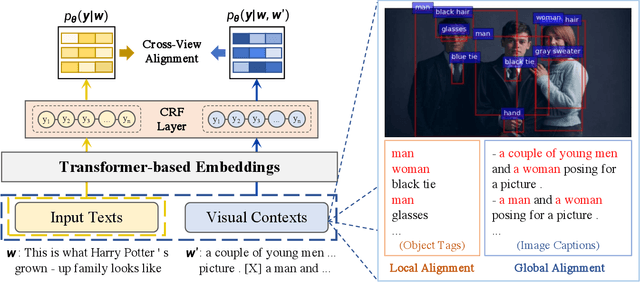
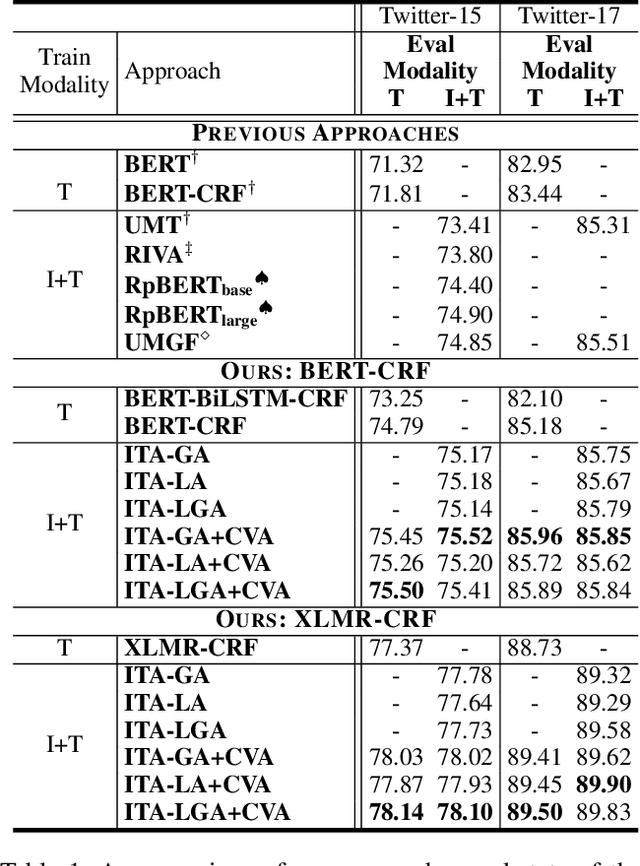
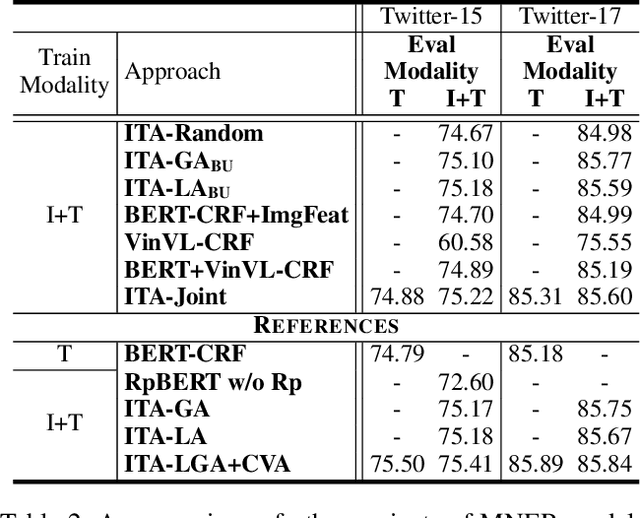
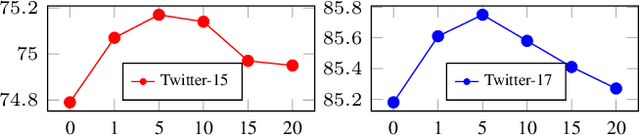
Recently, Multi-modal Named Entity Recognition (MNER) has attracted a lot of attention. Most of the work utilizes image information through region-level visual representations obtained from a pretrained object detector and relies on an attention mechanism to model the interactions between image and text representations. However, it is difficult to model such interactions as image and text representations are trained separately on the data of their respective modality and are not aligned in the same space. As text representations take the most important role in MNER, in this paper, we propose {\bf I}mage-{\bf t}ext {\bf A}lignments (ITA) to align image features into the textual space, so that the attention mechanism in transformer-based pretrained textual embeddings can be better utilized. ITA first locally and globally aligns regional object tags and image-level captions as visual contexts, concatenates them with the input texts as a new cross-modal input, and then feeds it into a pretrained textual embedding model. This makes it easier for the attention module of a pretrained textual embedding model to model the interaction between the two modalities since they are both represented in the textual space. ITA further aligns the output distributions predicted from the cross-modal input and textual input views so that the MNER model can be more practical and robust to noises from images. In our experiments, we show that ITA models can achieve state-of-the-art accuracy on multi-modal Named Entity Recognition datasets, even without image information.