 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Policy with Wait-$k$ Model for Simultaneous Translation
Oct 23, 2023



Simultaneous machine translation (SiMT) requires a robust read/write policy in conjunction with a high-quality translation model. Traditional methods rely on either a fixed wait-$k$ policy coupled with a standalone wait-$k$ translation model, or an adaptive policy jointly trained with the translation model. In this study, we propose a more flexible approach by decoupling the adaptive policy model from the translation model. Our motivation stems from the observation that a standalone multi-path wait-$k$ model performs competitively with adaptive policies utilized in state-of-the-art SiMT approaches. Specifically, we introduce DaP, a divergence-based adaptive policy, that makes read/write decisions for any translation model based on the potential divergence in translation distributions resulting from future information. DaP extends a frozen wait-$k$ model with lightweight parameters, and is both memory and computation efficient. Experimental results across various benchmarks demonstrate that our approach offers an improved trade-off between translation accuracy and latency, outperforming strong baselines.
A Chinese Multi-type Complex Questions Answering Dataset over Wikidata
Nov 11, 2021
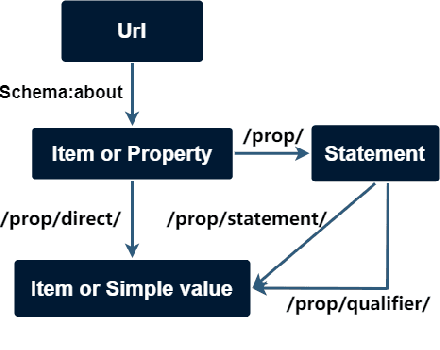
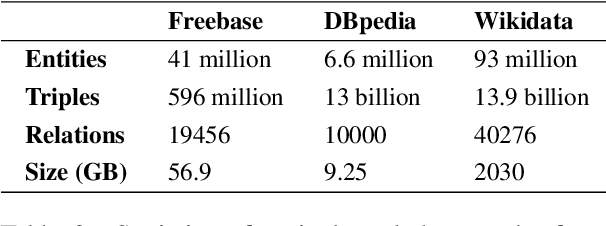
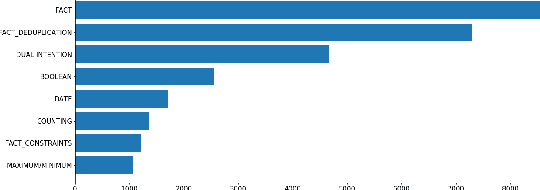
Complex Knowledge Base Question Answering is a popular area of research in the past decade. Recent public datasets have led to encouraging results in this field, but are mostly limited to English and only involve a small number of question types and relations, hindering research in more realistic settings and in languages other than English. In addition, few state-of-the-art KBQA models are trained on Wikidata, one of the most popular real-world knowledge bases. We propose CLC-QuAD, the first large scale complex Chinese semantic parsing dataset over Wikidata to address these challenges. Together with the dataset, we present a text-to-SPARQL baseline model, which can effectively answer multi-type complex questions, such as factual questions, dual intent questions, boolean questions, and counting questions, with Wikidata as the background knowledge. We finally analyze the performance of SOTA KBQA models on this dataset and identify the challenges facing Chinese KBQA.