 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-Real Grasp Detection with Global-to-Local RGB-D Adaptation
Mar 18, 2024



This paper focuses on the sim-to-real issue of RGB-D grasp detection and formulates it as a domain adaptation problem. In this case, we present a global-to-local method to address hybrid domain gaps in RGB and depth data and insufficient multi-modal feature alignment. First, a self-supervised rotation pre-training strategy is adopted to deliver robust initialization for RGB and depth networks. We then propose a global-to-local alignment pipeline with individual global domain classifiers for scene features of RGB and depth images as well as a local one specifically working for grasp features in the two modalities. In particular, we propose a grasp prototype adaptation module, which aims to facilitate fine-grained local feature alignment by dynamically updating and matching the grasp prototypes from the simulation and real-world scenarios throughout the training process. Due to such designs, the proposed method substantially reduces the domain shift and thus leads to consistent performance improvements. Extensive experiments are conducted on the GraspNet-Planar benchmark and physical environment, and superior results are achieved which demonstrate the effectiveness of our method.
RGB-D Grasp Detection via Depth Guided Learning with Cross-modal Attention
Feb 28, 2023



Planar grasp detection is one of the most fundamental tasks to robotic manipulation, and the recent progress of consumer-grade RGB-D sensors enables delivering more comprehensive features from both the texture and shape modalities. However, depth maps are generally of a relatively lower quality with much stronger noise compared to RGB images, making it challenging to acquire grasp depth and fuse multi-modal clues. To address the two issues, this paper proposes a novel learning based approach to RGB-D grasp detection, namely Depth Guided Cross-modal Attention Network (DGCAN). To better leverage the geometry information recorded in the depth channel, a complete 6-dimensional rectangle representation is adopted with the grasp depth dedicatedly considered in addition to those defined in the common 5-dimensional one. The prediction of the extra grasp depth substantially strengthens feature learning, thereby leading to more accurate results. Moreover, to reduce the negative impact caused by the discrepancy of data quality in two modalities, a Local Cross-modal Attention (LCA) module is designed, where the depth features are refined according to cross-modal relations and concatenated to the RGB ones for more sufficient fusion. Extensive simulation and physical evaluations are conducted and the experimental results highlight the superiority of the proposed approach.
A Chinese Multi-type Complex Questions Answering Dataset over Wikidata
Nov 11, 2021
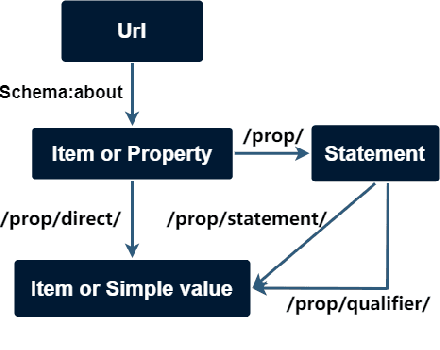
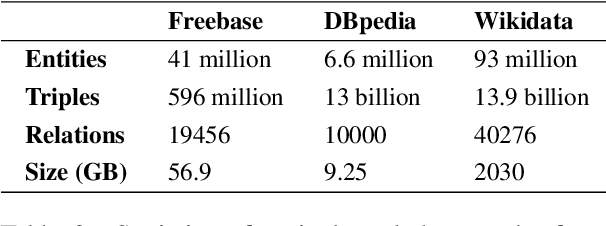
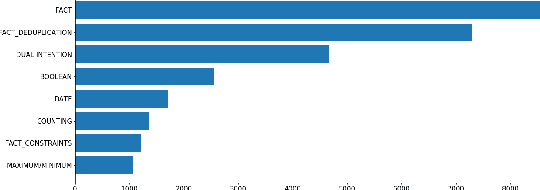
Complex Knowledge Base Question Answering is a popular area of research in the past decade. Recent public datasets have led to encouraging results in this field, but are mostly limited to English and only involve a small number of question types and relations, hindering research in more realistic settings and in languages other than English. In addition, few state-of-the-art KBQA models are trained on Wikidata, one of the most popular real-world knowledge bases. We propose CLC-QuAD, the first large scale complex Chinese semantic parsing dataset over Wikidata to address these challenges. Together with the dataset, we present a text-to-SPARQL baseline model, which can effectively answer multi-type complex questions, such as factual questions, dual intent questions, boolean questions, and counting questions, with Wikidata as the background knowledge. We finally analyze the performance of SOTA KBQA models on this dataset and identify the challenges facing Chinese KBQA.
MRDet: A Multi-Head Network for Accurate Oriented Object Detection in Aerial Images
Dec 24, 2020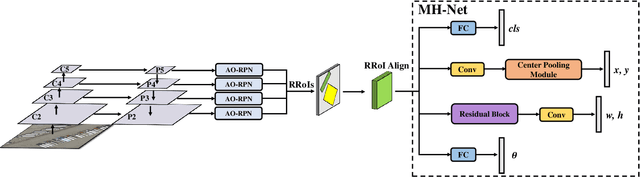
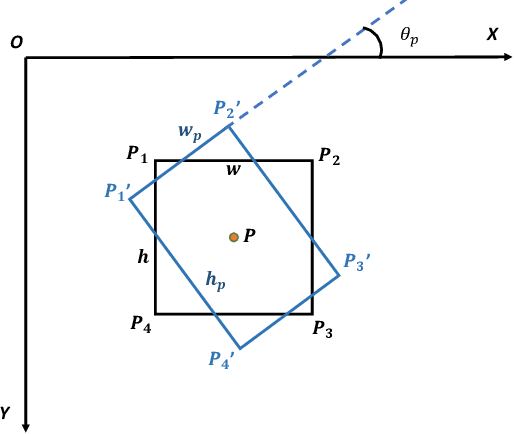
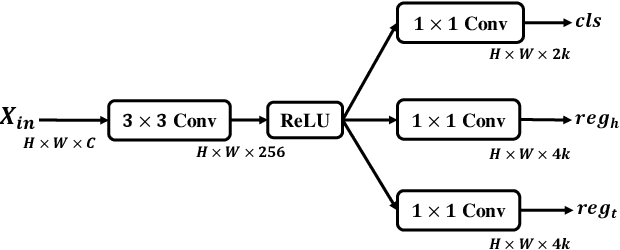
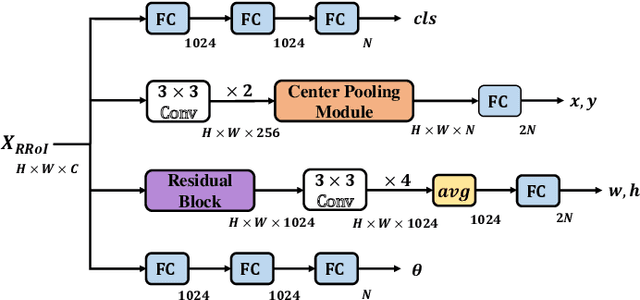
Objects in aerial images usually have arbitrary orientations and are densely located over the ground, making them extremely challenge to be detected. Many recently developed methods attempt to solve these issues by estimating an extra orientation parameter and placing dense anchors, which will result in high model complexity and computational costs. In this paper, we propose an arbitrary-oriented region proposal network (AO-RPN) to generate oriented proposals transformed from horizontal anchors. The AO-RPN is very efficient with only a few amounts of parameters increase than the original RPN. Furthermore, to obtain accurate bounding boxes, we decouple the detection task into multiple subtasks and propose a multi-head network to accomplish them. Each head is specially designed to learn the features optimal for the corresponding task, which allows our network to detect objects accurately. We name it MRDet short for Multi-head Rotated object Detector for convenience. We test the proposed MRDet on two challenging benchmarks, i.e., DOTA and HRSC2016, and compare it with several state-of-the-art methods. Our method achieves very promising results which clearly demonstrate its effectiveness.