 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirSimAG: A High-Fidelity Simulation Platform for Air-Ground Collaborative Robotics
Mar 24, 2026As spatial intelligence continues to evolve, heterogeneous multi-agent systems-particularly the collaboration between Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs), have demonstrated strong potential in complex applications such as search and rescue, urban surveillance, and environmental monitoring. However, existing simulation platforms are primarily designed for single-agent dynamics and lack dedicated frameworks for interactive air-ground collaborative simulation. In this paper, we present AirsimAG, a high-fidelity air-ground collaborative simulation platform built upon an extensively customized AirSim framework. The platform enables synchronized multi-agent simulation and supports heterogeneous sensing and control interfaces for UAV-UGV systems. To demonstrate its capabilities, we design a set of representative air-ground collaborative tasks, including mapping, planning, tracking, formation, and exploration. We further provide quantitative analyses based on these tasks to illustrate the platform effectiveness in supporting multi-agent coordination and cross-modal data consistency. The AirsimAG simulation platform is publicly available at https://github.com/BIULab-BUAA/AirSimAG.
WD-DETR: Wavelet Denoising-Enhanced Real-Time Object Detection Transformer for Robot Perception with Event Cameras
Jun 10, 2025Previous studies on event camera sensing have demonstrated certain detection performance using dense event representations. However, the accumulated noise in such dense representations has received insufficient attention, which degrades the representation quality and increases the likelihood of missed detections. To address this challenge, we propose the Wavelet Denoising-enhanced DEtection TRansformer, i.e., WD-DETR network, for event cameras. In particular, a dense event representation is presented first, which enables real-time reconstruction of events as tensors. Then, a wavelet transform method is designed to filter noise in the event representations. Such a method is integrated into the backbone for feature extraction. The extracted features are subsequently fed into a transformer-based network for object prediction. To further reduce inference time, we incorporate the Dynamic Reorganization Convolution Block (DRCB) as a fusion module within the hybrid encoder. The proposed method has been evaluated on three event-based object detection datasets, i.e., DSEC, Gen1, and 1Mpx. The results demonstrate that WD-DETR outperforms tested state-of-the-art methods. Additionally, we implement our approach on a common onboard computer for robots, the NVIDIA Jetson Orin NX, achieving a high frame rate of approximately 35 FPS using TensorRT FP16, which is exceptionally well-suited for real-time perception of onboard robotic systems.
Generalizing 6-DoF Grasp Detection via Domain Prior Knowledge
Apr 02, 2024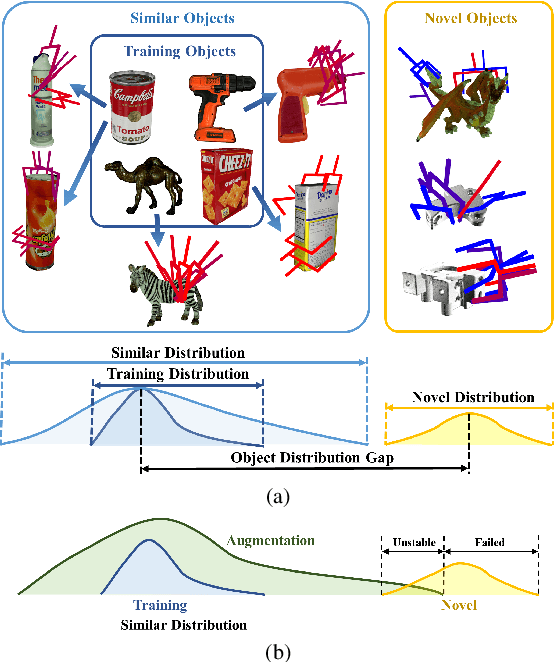
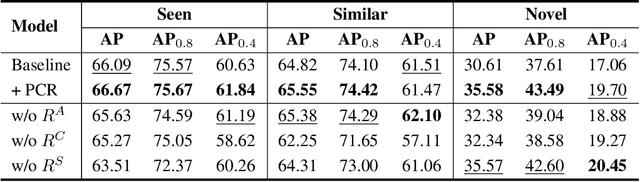
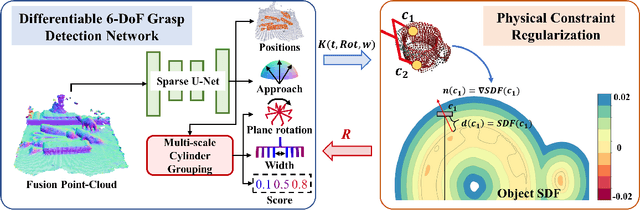

We focus on the generalization ability of the 6-DoF grasp detection method in this paper. While learning-based grasp detection methods can predict grasp poses for unseen objects using the grasp distribution learned from the training set, they often exhibit a significant performance drop when encountering objects with diverse shapes and structures. To enhance the grasp detection methods' generalization ability, we incorporate domain prior knowledge of robotic grasping, enabling better adaptation to objects with significant shape and structure differences. More specifically, we employ the physical constraint regularization during the training phase to guide the model towards predicting grasps that comply with the physical rule on grasping. For the unstable grasp poses predicted on novel objects, we design a contact-score joint optimization using the projection contact map to refine these poses in cluttered scenarios. Extensive experiments conducted on the GraspNet-1billion benchmark demonstrate a substantial performance gain on the novel object set and the real-world grasping experiments also demonstrate the effectiveness of our generalizing 6-DoF grasp detection method.
Sim-to-Real Grasp Detection with Global-to-Local RGB-D Adaptation
Mar 18, 2024



This paper focuses on the sim-to-real issue of RGB-D grasp detection and formulates it as a domain adaptation problem. In this case, we present a global-to-local method to address hybrid domain gaps in RGB and depth data and insufficient multi-modal feature alignment. First, a self-supervised rotation pre-training strategy is adopted to deliver robust initialization for RGB and depth networks. We then propose a global-to-local alignment pipeline with individual global domain classifiers for scene features of RGB and depth images as well as a local one specifically working for grasp features in the two modalities. In particular, we propose a grasp prototype adaptation module, which aims to facilitate fine-grained local feature alignment by dynamically updating and matching the grasp prototypes from the simulation and real-world scenarios throughout the training process. Due to such designs, the proposed method substantially reduces the domain shift and thus leads to consistent performance improvements. Extensive experiments are conducted on the GraspNet-Planar benchmark and physical environment, and superior results are achieved which demonstrate the effectiveness of our method.
RGB-D Grasp Detection via Depth Guided Learning with Cross-modal Attention
Feb 28, 2023



Planar grasp detection is one of the most fundamental tasks to robotic manipulation, and the recent progress of consumer-grade RGB-D sensors enables delivering more comprehensive features from both the texture and shape modalities. However, depth maps are generally of a relatively lower quality with much stronger noise compared to RGB images, making it challenging to acquire grasp depth and fuse multi-modal clues. To address the two issues, this paper proposes a novel learning based approach to RGB-D grasp detection, namely Depth Guided Cross-modal Attention Network (DGCAN). To better leverage the geometry information recorded in the depth channel, a complete 6-dimensional rectangle representation is adopted with the grasp depth dedicatedly considered in addition to those defined in the common 5-dimensional one. The prediction of the extra grasp depth substantially strengthens feature learning, thereby leading to more accurate results. Moreover, to reduce the negative impact caused by the discrepancy of data quality in two modalities, a Local Cross-modal Attention (LCA) module is designed, where the depth features are refined according to cross-modal relations and concatenated to the RGB ones for more sufficient fusion. Extensive simulation and physical evaluations are conducted and the experimental results highlight the superiority of the proposed approach.
Double-Dot Network for Antipodal Grasp Detection
Aug 03, 2021

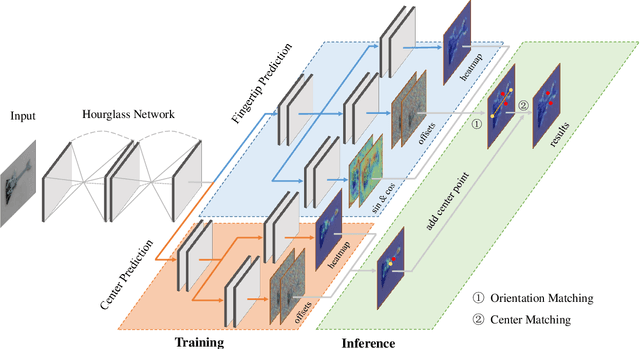

This paper proposes a new deep learning approach to antipodal grasp detection, named Double-Dot Network (DD-Net). It follows the recent anchor-free object detection framework, which does not depend on empirically pre-set anchors and thus allows more generalized and flexible prediction on unseen objects. Specifically, unlike the widely used 5-dimensional rectangle, the gripper configuration is defined as a pair of fingertips. An effective CNN architecture is introduced to localize such fingertips, and with the help of auxiliary centers for refinement, it accurately and robustly infers grasp candidates. Additionally, we design a specialized loss function to measure the quality of grasps, and in contrast to the IoU scores of bounding boxes adopted in object detection, it is more consistent to the grasp detection task. Both the simulation and robotic experiments are executed and state of the art accuracies are achieved, showing that DD-Net is superior to the counterparts in handling unseen objects.
Visual and Semantic Knowledge Transfer for Large Scale Semi-supervised Object Detection
Mar 13, 2018
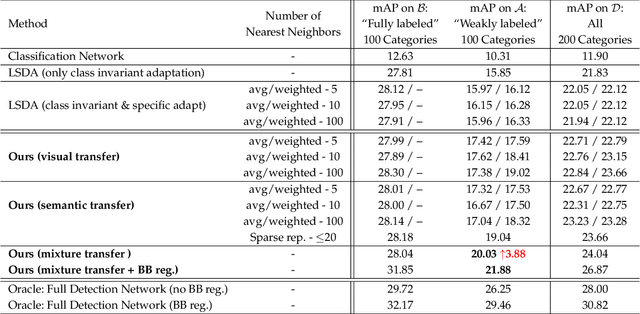


Deep CNN-based object detection systems have achieved remarkable success on several large-scale object detection benchmarks. However, training such detectors requires a large number of labeled bounding boxes, which are more difficult to obtain than image-level annotations. Previous work addresses this issue by transforming image-level classifiers into object detectors. This is done by modeling the differences between the two on categories with both image-level and bounding box annotations, and transferring this information to convert classifiers to detectors for categories without bounding box annotations. We improve this previous work by incorporating knowledge about object similarities from visual and semantic domains during the transfer process. The intuition behind our proposed method is that visually and semantically similar categories should exhibit more common transferable properties than dissimilar categories, e.g. a better detector would result by transforming the differences between a dog classifier and a dog detector onto the cat class, than would by transforming from the violin class. Experimental results on the challenging ILSVRC2013 detection dataset demonstrate that each of our proposed object similarity based knowledge transfer methods outperforms the baseline methods. We found strong evidence that visual similarity and semantic relatedness are complementary for the task, and when combined notably improve detection, achieving state-of-the-art detection performance in a semi-supervised setting.
* TPAMI. correct some typos