 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Generation for Contradiction Reconciliation with LLMs
Mar 24, 2026Existing NLP work commonly treats contradictions as errors to be resolved by choosing which statements to accept or discard. Yet a key aspect of human reasoning in social interactions and professional domains is the ability to hypothesize explanations that reconcile contradictions. For example, "Cassie hates coffee" and "She buys coffee everyday" may appear contradictory, yet both are compatible if Cassie has the unenviable daily chore of buying coffee for all her coworkers. Despite the growing reasoning capabilities of large language models (LLMs), their ability to hypothesize such reconciliatory explanations remains largely unexplored. To address this gap, we introduce the task of reconciliatory explanation generation, where models must generate explanations that effectively render contradictory statements compatible. We propose a novel method of repurposing existing natural language inference (NLI) datasets, and introduce quality metrics that enable scalable automatic evaluation. Experiments with 18 LLMs show that most models achieve limited success in this task, and that the benefit of extending test-time compute by "thinking" plateaus as model size increases. Our results highlight an under-explored dimension of LLM reasoning and the need to address this limitation in enhancing LLMs' downstream applications such as chatbots and scientific aids.
Position: On the Methodological Pitfalls of Evaluating Base LLMs for Reasoning
Nov 13, 2025Existing work investigates the reasoning capabilities of large language models (LLMs) to uncover their limitations, human-like biases and underlying processes. Such studies include evaluations of base LLMs (pre-trained on unlabeled corpora only) for this purpose. Our position paper argues that evaluating base LLMs' reasoning capabilities raises inherent methodological concerns that are overlooked in such existing studies. We highlight the fundamental mismatch between base LLMs' pretraining objective and normative qualities, such as correctness, by which reasoning is assessed. In particular, we show how base LLMs generate logically valid or invalid conclusions as coincidental byproducts of conforming to purely linguistic patterns of statistical plausibility. This fundamental mismatch challenges the assumptions that (a) base LLMs' outputs can be assessed as their bona fide attempts at correct answers or conclusions; and (b) conclusions about base LLMs' reasoning can generalize to post-trained LLMs optimized for successful instruction-following. We call for a critical re-examination of existing work that relies implicitly on these assumptions, and for future work to account for these methodological pitfalls.
Rulebreakers Challenge: Revealing a Blind Spot in Large Language Models' Reasoning with Formal Logic
Oct 21, 2024



Formal logic has long been applied to natural language reasoning, but this approach can sometimes lead to conclusions that, while logically entailed, are factually inconsistent with the premises or are not typically inferred by humans. This study introduces the concept of "rulebreakers", which refers to instances where logical entailment diverges from factually acceptable inference. We present RULEBREAKERS, a novel dataset for evaluating Large Language Models' (LLMs) ability to distinguish between rulebreakers and non-rulebreakers. Focusing on modus tollens and disjunctive syllogism, we assess six state-of-the-art LLMs using RULEBREAKERS, measuring their performance in terms of token-level exact accuracy and model confidence. Our findings reveal that while most models perform poorly to moderately in recognizing rulebreakers, they demonstrate a latent ability to distinguish rulebreakers when assessed by their confidence levels. Further analysis suggests that the failure to recognize rulebreakers is potentially associated with the models' world knowledge and their attention distribution patterns. This research highlights the limitation of LLMs' reasoning capabilities, and contributes to the ongoing discussion on reasoning in LLMs.
Visual and Semantic Knowledge Transfer for Large Scale Semi-supervised Object Detection
Mar 13, 2018
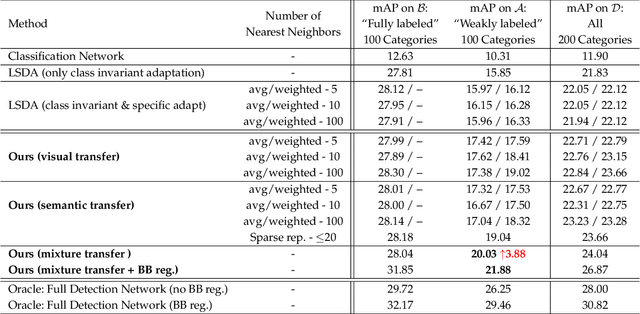


Deep CNN-based object detection systems have achieved remarkable success on several large-scale object detection benchmarks. However, training such detectors requires a large number of labeled bounding boxes, which are more difficult to obtain than image-level annotations. Previous work addresses this issue by transforming image-level classifiers into object detectors. This is done by modeling the differences between the two on categories with both image-level and bounding box annotations, and transferring this information to convert classifiers to detectors for categories without bounding box annotations. We improve this previous work by incorporating knowledge about object similarities from visual and semantic domains during the transfer process. The intuition behind our proposed method is that visually and semantically similar categories should exhibit more common transferable properties than dissimilar categories, e.g. a better detector would result by transforming the differences between a dog classifier and a dog detector onto the cat class, than would by transforming from the violin class. Experimental results on the challenging ILSVRC2013 detection dataset demonstrate that each of our proposed object similarity based knowledge transfer methods outperforms the baseline methods. We found strong evidence that visual similarity and semantic relatedness are complementary for the task, and when combined notably improve detection, achieving state-of-the-art detection performance in a semi-supervised setting.
* TPAMI. correct some typos
A Data Driven Approach to Query Expansion in Question Answering
Mar 22, 2012
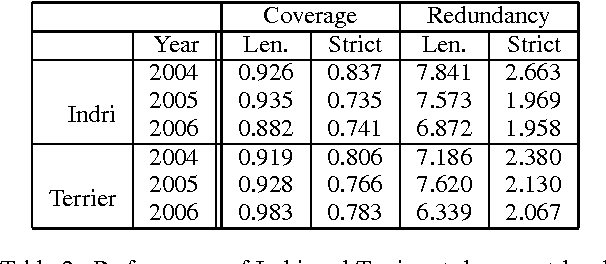


Automated answering of natural language questions is an interesting and useful problem to solve. Question answering (QA) systems often perform information retrieval at an initial stage. Information retrieval (IR) performance, provided by engines such as Lucene, places a bound on overall system performance. For example, no answer bearing documents are retrieved at low ranks for almost 40% of questions. In this paper, answer texts from previous QA evaluations held as part of the Text REtrieval Conferences (TREC) are paired with queries and analysed in an attempt to identify performance-enhancing words. These words are then used to evaluate the performance of a query expansion method. Data driven extension words were found to help in over 70% of difficult questions. These words can be used to improve and evaluate query expansion methods. Simple blind relevance feedback (RF) was correctly predicted as unlikely to help overall performance, and an possible explanation is provided for its low value in IR for QA.
USFD at KBP 2011: Entity Linking, Slot Filling and Temporal Bounding
Mar 22, 2012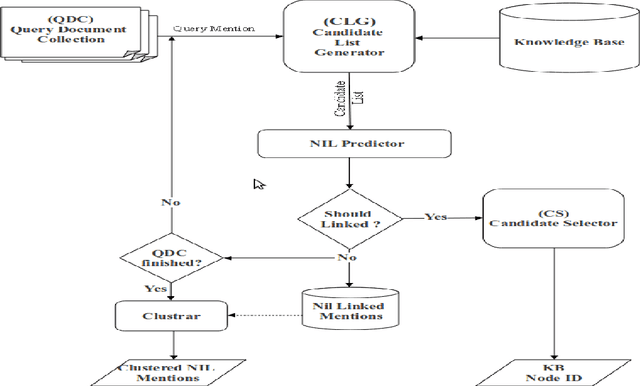
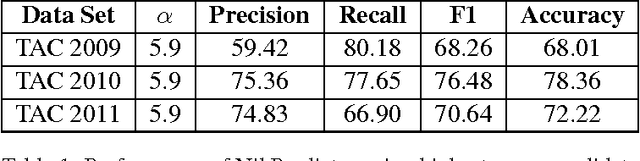
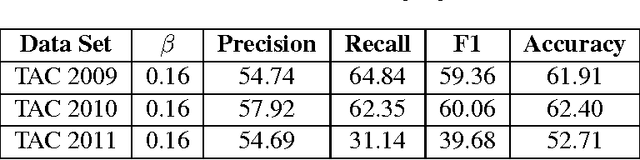

This paper describes the University of Sheffield's entry in the 2011 TAC KBP entity linking and slot filling tasks. We chose to participate in the monolingual entity linking task, the monolingual slot filling task and the temporal slot filling tasks. We set out to build a framework for experimentation with knowledge base population. This framework was created, and applied to multiple KBP tasks. We demonstrated that our proposed framework is effective and suitable for collaborative development efforts, as well as useful in a teaching environment. Finally we present results that, while very modest, provide improvements an order of magnitude greater than our 2010 attempt.
A Corpus-based Study of Temporal Signals
Mar 22, 2012
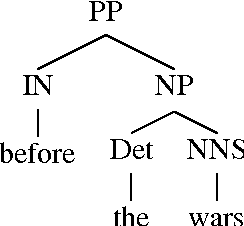
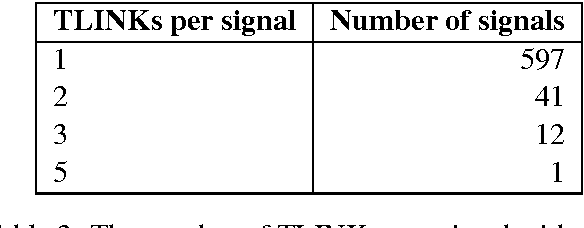
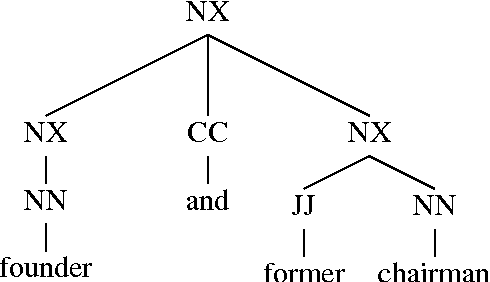
Automatic temporal ordering of events described in discourse has been of great interest in recent years. Event orderings are conveyed in text via va rious linguistic mechanisms including the use of expressions such as "before", "after" or "during" that explicitly assert a temporal relation -- temporal signals. In this paper, we investigate the role of temporal signals in temporal relation extraction and provide a quantitative analysis of these expres sions in the TimeBank annotated corpus.
* Proc. Corpus Linguistics (2011)
An Annotation Scheme for Reichenbach's Verbal Tense Structure
Mar 22, 2012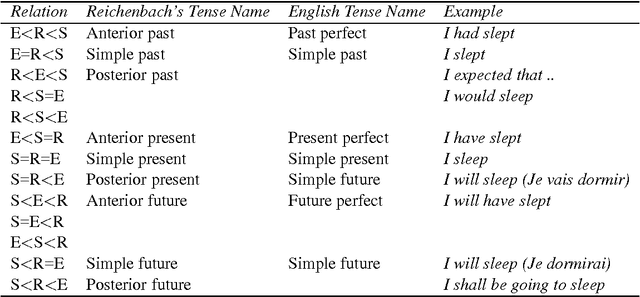

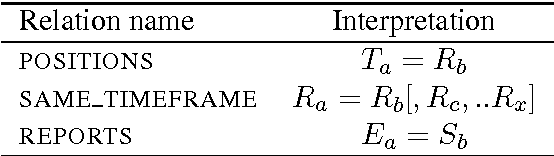
In this paper we present RTMML, a markup language for the tenses of verbs and temporal relations between verbs. There is a richness to tense in language that is not fully captured by existing temporal annotation schemata. Following Reichenbach we present an analysis of tense in terms of abstract time points, with the aim of supporting automated processing of tense and temporal relations in language. This allows for precise reasoning about tense in documents, and the deduction of temporal relations between the times and verbal events in a discourse. We define the syntax of RTMML, and demonstrate the markup in a range of situations.
USFD2: Annotating Temporal Expresions and TLINKs for TempEval-2
Mar 22, 2012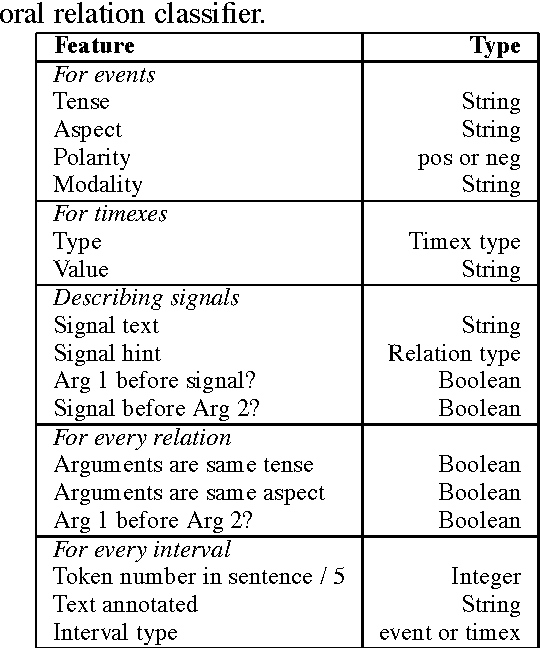
We describe the University of Sheffield system used in the TempEval-2 challenge, USFD2. The challenge requires the automatic identification of temporal entities and relations in text. USFD2 identifies and anchors temporal expressions, and also attempts two of the four temporal relation assignment tasks. A rule-based system picks out and anchors temporal expressions, and a maximum entropy classifier assigns temporal link labels, based on features that include descriptions of associated temporal signal words. USFD2 identified temporal expressions successfully, and correctly classified their type in 90% of cases. Determining the relation between an event and time expression in the same sentence was performed at 63% accuracy, the second highest score in this part of the challenge.
* Part of TempEval-2
Using Signals to Improve Automatic Classification of Temporal Relations
Mar 22, 2012
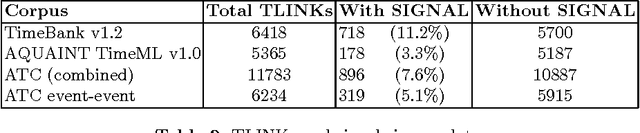


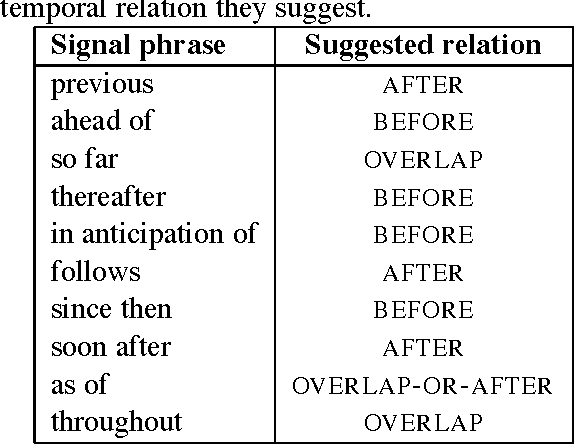
Temporal information conveyed by language describes how the world around us changes through time. Events, durations and times are all temporal elements that can be viewed as intervals. These intervals are sometimes temporally related in text. Automatically determining the nature of such relations is a complex and unsolved problem. Some words can act as "signals" which suggest a temporal ordering between intervals. In this paper, we use these signal words to improve the accuracy of a recent approach to classification of temporal links.