 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations of Religious Data and the Importance of the Target Domain: Towards Machine Translation for Guinea-Bissau Creole
Apr 03, 2025We introduce a new dataset for machine translation of Guinea-Bissau Creole (Kiriol), comprising around 40 thousand parallel sentences to English and Portuguese. This dataset is made up of predominantly religious data (from the Bible and texts from the Jehovah's Witnesses), but also a small amount of general domain data (from a dictionary). This mirrors the typical resource availability of many low resource languages. We train a number of transformer-based models to investigate how to improve domain transfer from religious data to a more general domain. We find that adding even 300 sentences from the target domain when training substantially improves the translation performance, highlighting the importance and need for data collection for low-resource languages, even on a small-scale. We additionally find that Portuguese-to-Kiriol translation models perform better on average than other source and target language pairs, and investigate how this relates to the morphological complexity of the languages involved and the degree of lexical overlap between creoles and lexifiers. Overall, we hope our work will stimulate research into Kiriol and into how machine translation might better support creole languages in general.
Igbo-English Machine Translation: An Evaluation Benchmark
Apr 01, 2020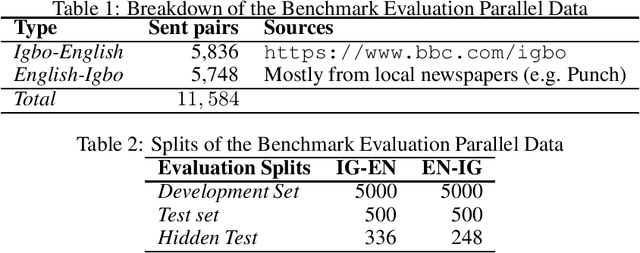

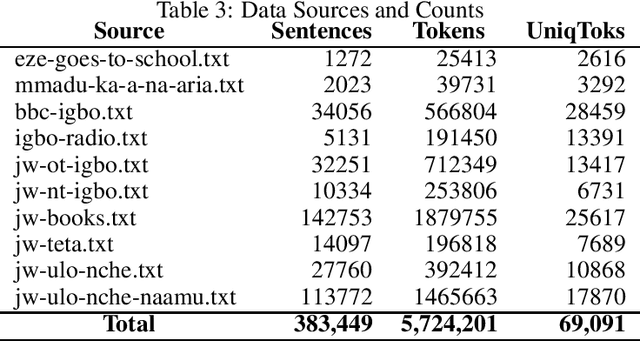
Although researchers and practitioners are pushing the boundaries and enhancing the capacities of NLP tools and methods, works on African languages are lagging. A lot of focus on well resourced languages such as English, Japanese, German, French, Russian, Mandarin Chinese etc. Over 97% of the world's 7000 languages, including African languages, are low resourced for NLP i.e. they have little or no data, tools, and techniques for NLP research. For instance, only 5 out of 2965, 0.19% authors of full text papers in the ACL Anthology extracted from the 5 major conferences in 2018 ACL, NAACL, EMNLP, COLING and CoNLL, are affiliated to African institutions. In this work, we discuss our effort toward building a standard machine translation benchmark dataset for Igbo, one of the 3 major Nigerian languages. Igbo is spoken by more than 50 million people globally with over 50% of the speakers are in southeastern Nigeria. Igbo is low resourced although there have been some efforts toward developing IgboNLP such as part of speech tagging and diacritic restoration
Compacting the Penn Treebank Grammar
Jan 31, 1999
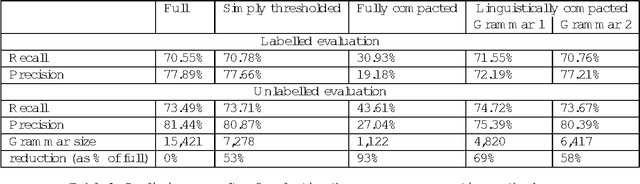
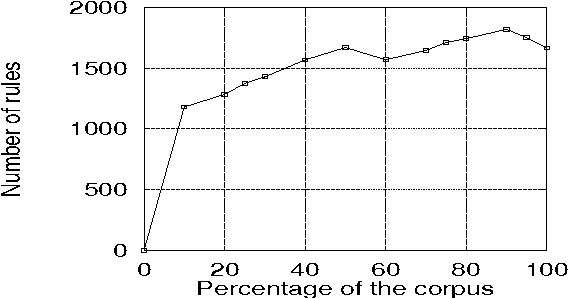
Treebanks, such as the Penn Treebank (PTB), offer a simple approach to obtaining a broad coverage grammar: one can simply read the grammar off the parse trees in the treebank. While such a grammar is easy to obtain, a square-root rate of growth of the rule set with corpus size suggests that the derived grammar is far from complete and that much more treebanked text would be required to obtain a complete grammar, if one exists at some limit. However, we offer an alternative explanation in terms of the underspecification of structures within the treebank. This hypothesis is explored by applying an algorithm to compact the derived grammar by eliminating redundant rules -- rules whose right hand sides can be parsed by other rules. The size of the resulting compacted grammar, which is significantly less than that of the full treebank grammar, is shown to approach a limit. However, such a compacted grammar does not yield very good performance figures. A version of the compaction algorithm taking rule probabilities into account is proposed, which is argued to be more linguistically motivated. Combined with simple thresholding, this method can be used to give a 58% reduction in grammar size without significant change in parsing performance, and can produce a 69% reduction with some gain in recall, but a loss in precision.
* 5 pages, 2 figures