 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus-Based Approaches to Igbo Diacritic Restoration
Jan 26, 2026With natural language processing (NLP), researchers aim to enable computers to identify and understand patterns in human languages. This is often difficult because a language embeds many dynamic and varied properties in its syntax, pragmatics and phonology, which need to be captured and processed. The capacity of computers to process natural languages is increasing because NLP researchers are pushing its boundaries. But these research works focus more on well-resourced languages such as English, Japanese, German, French, Russian, Mandarin Chinese, etc. Over 95% of the world's 7000 languages are low-resourced for NLP, i.e. they have little or no data, tools, and techniques for NLP work. In this thesis, we present an overview of diacritic ambiguity and a review of previous diacritic disambiguation approaches on other languages. Focusing on the Igbo language, we report the steps taken to develop a flexible framework for generating datasets for diacritic restoration. Three main approaches, the standard n-gram model, the classification models and the embedding models were proposed. The standard n-gram models use a sequence of previous words to the target stripped word as key predictors of the correct variants. For the classification models, a window of words on both sides of the target stripped word was used. The embedding models compare the similarity scores of the combined context word embeddings and the embeddings of each of the candidate variant vectors.
* 270 page. Ph.D. Thesis. The University of Sheffield
Reasoning Beyond Labels: Measuring LLM Sentiment in Low-Resource, Culturally Nuanced Contexts
Aug 06, 2025Sentiment analysis in low-resource, culturally nuanced contexts challenges conventional NLP approaches that assume fixed labels and universal affective expressions. We present a diagnostic framework that treats sentiment as a context-dependent, culturally embedded construct, and evaluate how large language models (LLMs) reason about sentiment in informal, code-mixed WhatsApp messages from Nairobi youth health groups. Using a combination of human-annotated data, sentiment-flipped counterfactuals, and rubric-based explanation evaluation, we probe LLM interpretability, robustness, and alignment with human reasoning. Framing our evaluation through a social-science measurement lens, we operationalize and interrogate LLMs outputs as an instrument for measuring the abstract concept of sentiment. Our findings reveal significant variation in model reasoning quality, with top-tier LLMs demonstrating interpretive stability, while open models often falter under ambiguity or sentiment shifts. This work highlights the need for culturally sensitive, reasoning-aware AI evaluation in complex, real-world communication.
The IgboAPI Dataset: Empowering Igbo Language Technologies through Multi-dialectal Enrichment
May 02, 2024

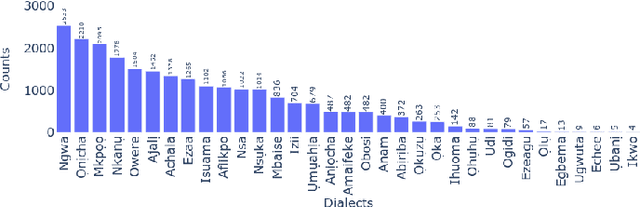
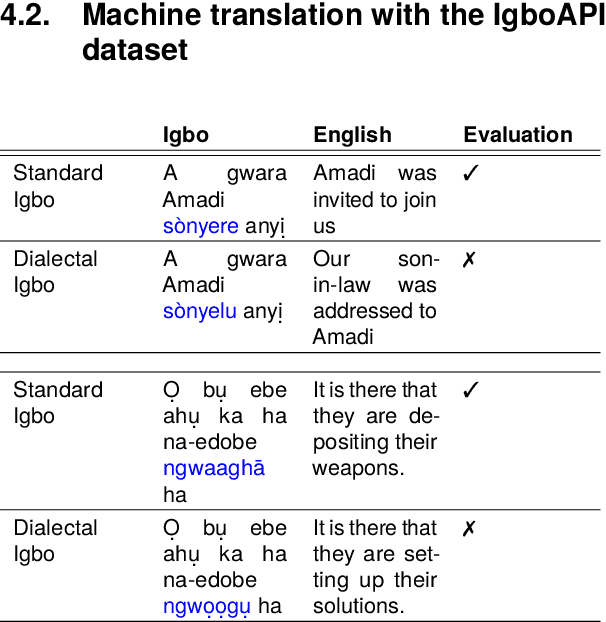
The Igbo language is facing a risk of becoming endangered, as indicated by a 2025 UNESCO study. This highlights the need to develop language technologies for Igbo to foster communication, learning and preservation. To create robust, impactful, and widely adopted language technologies for Igbo, it is essential to incorporate the multi-dialectal nature of the language. The primary obstacle in achieving dialectal-aware language technologies is the lack of comprehensive dialectal datasets. In response, we present the IgboAPI dataset, a multi-dialectal Igbo-English dictionary dataset, developed with the aim of enhancing the representation of Igbo dialects. Furthermore, we illustrate the practicality of the IgboAPI dataset through two distinct studies: one focusing on Igbo semantic lexicon and the other on machine translation. In the semantic lexicon project, we successfully establish an initial Igbo semantic lexicon for the Igbo semantic tagger, while in the machine translation study, we demonstrate that by finetuning existing machine translation systems using the IgboAPI dataset, we significantly improve their ability to handle dialectal variations in sentences.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
Introducing the Welsh Text Summarisation Dataset and Baseline Systems
May 05, 2022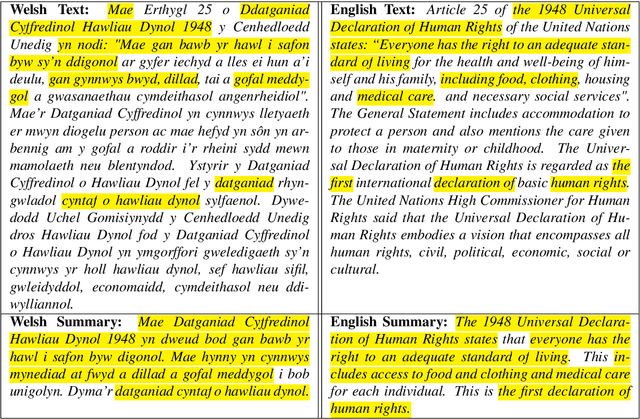
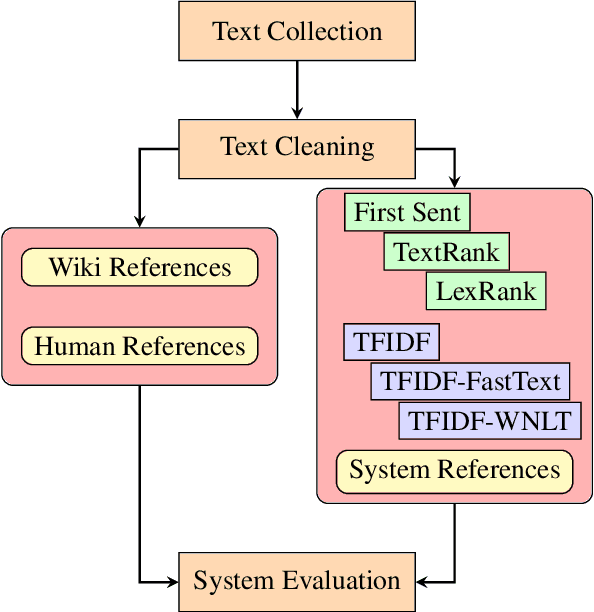

Welsh is an official language in Wales and is spoken by an estimated 884,300 people (29.2% of the population of Wales). Despite this status and estimated increase in speaker numbers since the last (2011) census, Welsh remains a minority language undergoing revitalization and promotion by Welsh Government and relevant stakeholders. As part of the effort to increase the availability of Welsh digital technology, this paper introduces the first Welsh summarisation dataset, which we provide freely for research purposes to help advance the work on Welsh text summarization. The dataset was created by Welsh speakers by manually summarising Welsh Wikipedia articles. In addition, the paper discusses the implementation and evaluation of different summarisation systems for Welsh. The summarization systems and results will serve as benchmarks for the development of summarises in other minority language contexts.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021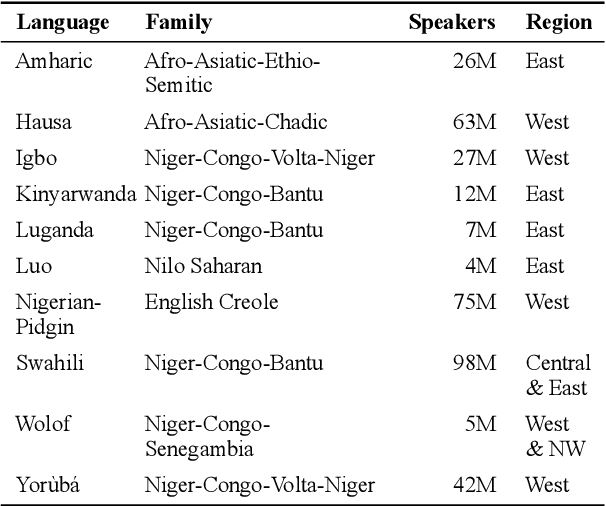

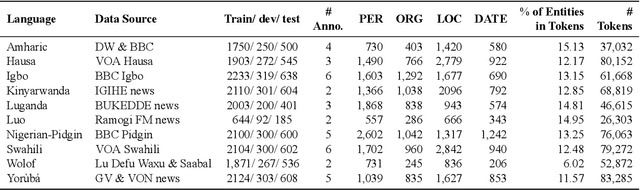
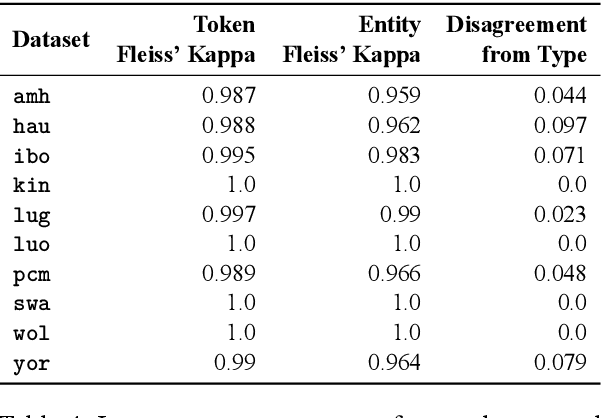
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020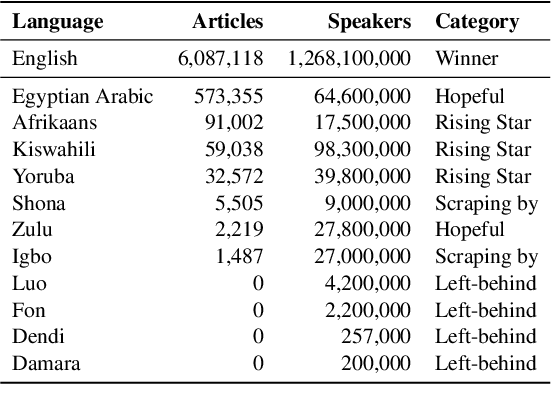
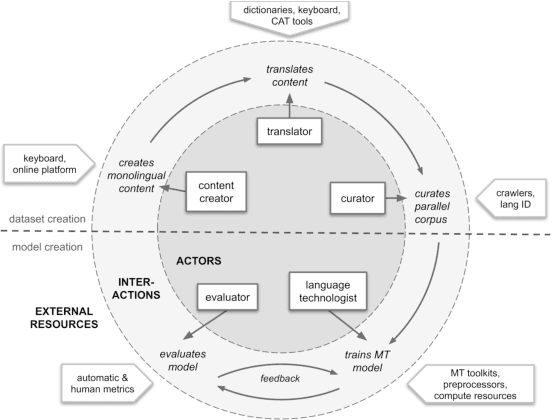
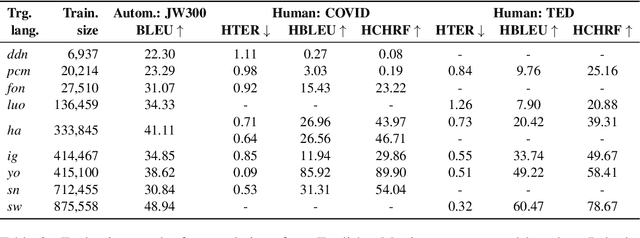
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
Igbo-English Machine Translation: An Evaluation Benchmark
Apr 01, 2020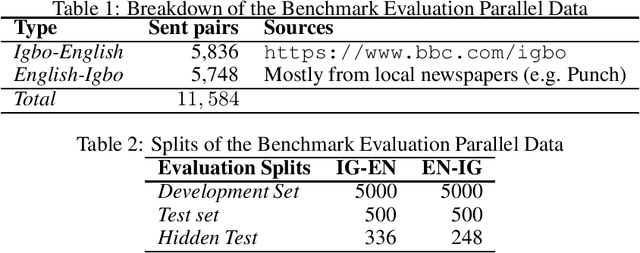

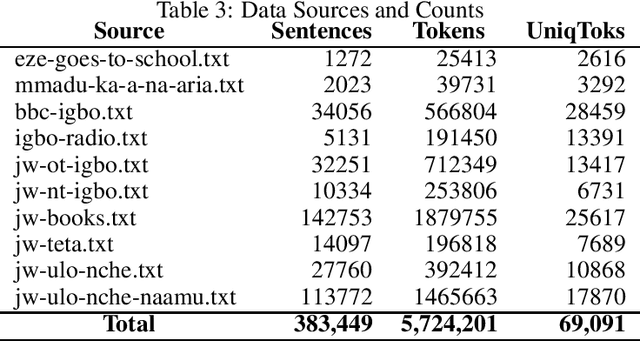
Although researchers and practitioners are pushing the boundaries and enhancing the capacities of NLP tools and methods, works on African languages are lagging. A lot of focus on well resourced languages such as English, Japanese, German, French, Russian, Mandarin Chinese etc. Over 97% of the world's 7000 languages, including African languages, are low resourced for NLP i.e. they have little or no data, tools, and techniques for NLP research. For instance, only 5 out of 2965, 0.19% authors of full text papers in the ACL Anthology extracted from the 5 major conferences in 2018 ACL, NAACL, EMNLP, COLING and CoNLL, are affiliated to African institutions. In this work, we discuss our effort toward building a standard machine translation benchmark dataset for Igbo, one of the 3 major Nigerian languages. Igbo is spoken by more than 50 million people globally with over 50% of the speakers are in southeastern Nigeria. Igbo is low resourced although there have been some efforts toward developing IgboNLP such as part of speech tagging and diacritic restoration