 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Lie or Not to Lie? Investigating The Biased Spread of Global Lies by LLMs
Apr 08, 2026Misinformation is on the rise, and the strong writing capabilities of LLMs lower the barrier for malicious actors to produce and disseminate false information. We study how LLMs behave when prompted to spread misinformation across languages and target countries, and introduce GlobalLies, a multilingual parallel dataset of 440 misinformation generation prompt templates and 6,867 entities, spanning 8 languages and 195 countries. Using both human annotations and large-scale LLM-as-a-judge evaluations across hundreds of thousands of generations from state-of-the-art models, we show that misinformation generation varies systematically based on the country being discussed. Propagation of lies by LLMs is substantially higher in many lower-resource languages and for countries with a lower Human Development Index (HDI). We find that existing mitigation strategies provide uneven protection: input safety classifiers exhibit cross-lingual gaps, and retrieval-augmented fact-checking remains inconsistent across regions due to unequal information availability. We release GlobalLies for research purposes, aiming to support the development of mitigation strategies to reduce the spread of global misinformation: https://github.com/zohaib-khan5040/globallies
MGSM-Pro: A Simple Strategy for Robust Multilingual Mathematical Reasoning Evaluation
Jan 29, 2026Large language models have made substantial progress in mathematical reasoning. However, benchmark development for multilingual evaluation has lagged behind English in both difficulty and recency. Recently, GSM-Symbolic showed a strong evidence of high variance when models are evaluated on different instantiations of the same question; however, the evaluation was conducted only in English. In this paper, we introduce MGSM-Pro, an extension of MGSM dataset with GSM-Symbolic approach. Our dataset provides five instantiations per MGSM question by varying names, digits and irrelevant context. Evaluations across nine languages reveal that many low-resource languages suffer large performance drops when tested on digit instantiations different from those in the original test set. We further find that some proprietary models, notably Gemini 2.5 Flash and GPT-4.1, are less robust to digit instantiation, whereas Claude 4.0 Sonnet is more robust. Among open models, GPT-OSS 120B and DeepSeek V3 show stronger robustness. Based on these findings, we recommend evaluating each problem using at least five digit-varying instantiations to obtain a more robust and realistic assessment of math reasoning.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

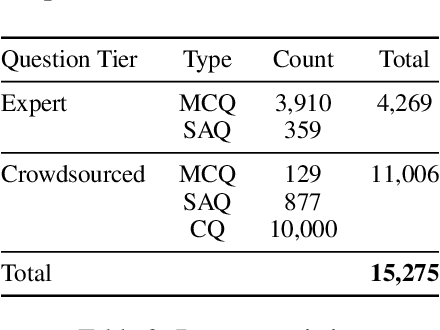

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
The IgboAPI Dataset: Empowering Igbo Language Technologies through Multi-dialectal Enrichment
May 02, 2024

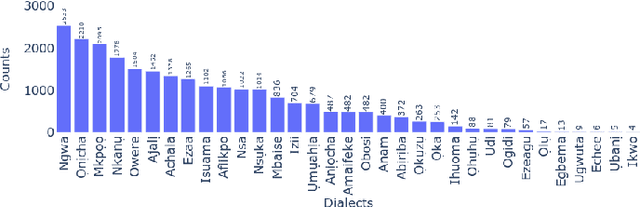
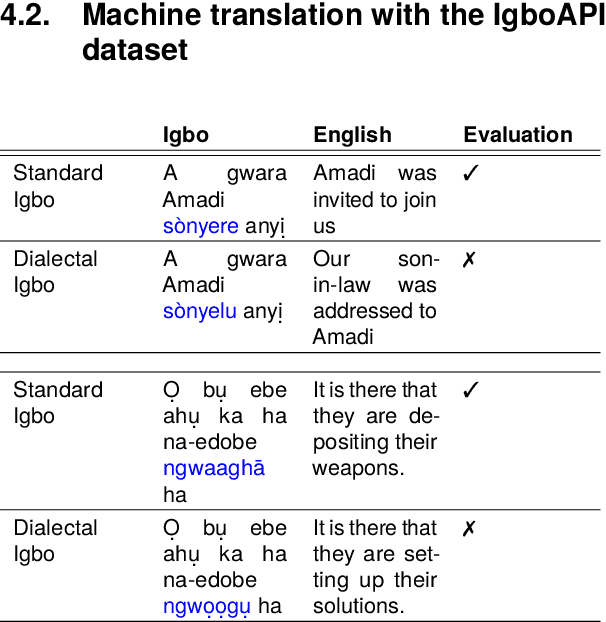
The Igbo language is facing a risk of becoming endangered, as indicated by a 2025 UNESCO study. This highlights the need to develop language technologies for Igbo to foster communication, learning and preservation. To create robust, impactful, and widely adopted language technologies for Igbo, it is essential to incorporate the multi-dialectal nature of the language. The primary obstacle in achieving dialectal-aware language technologies is the lack of comprehensive dialectal datasets. In response, we present the IgboAPI dataset, a multi-dialectal Igbo-English dictionary dataset, developed with the aim of enhancing the representation of Igbo dialects. Furthermore, we illustrate the practicality of the IgboAPI dataset through two distinct studies: one focusing on Igbo semantic lexicon and the other on machine translation. In the semantic lexicon project, we successfully establish an initial Igbo semantic lexicon for the Igbo semantic tagger, while in the machine translation study, we demonstrate that by finetuning existing machine translation systems using the IgboAPI dataset, we significantly improve their ability to handle dialectal variations in sentences.
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024
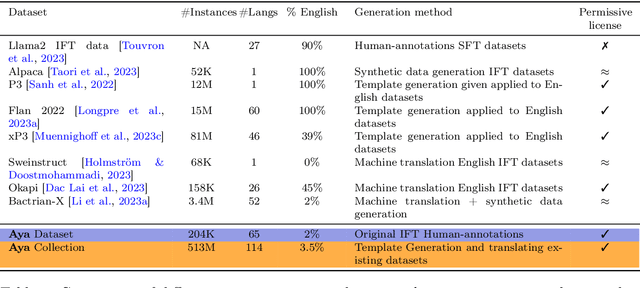
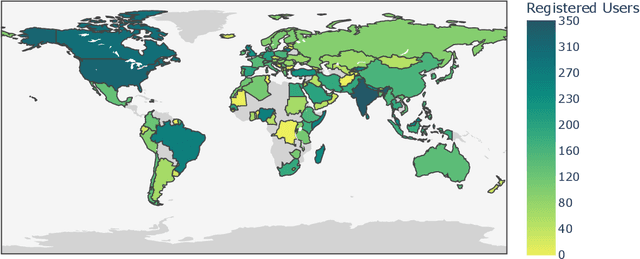
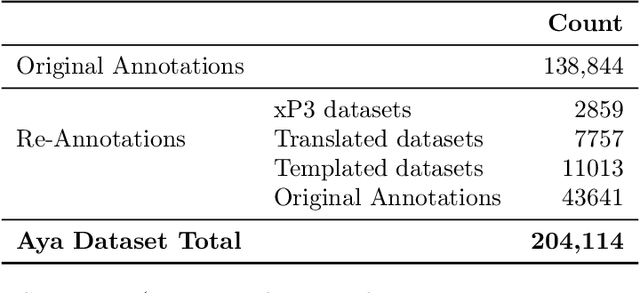
Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.