 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

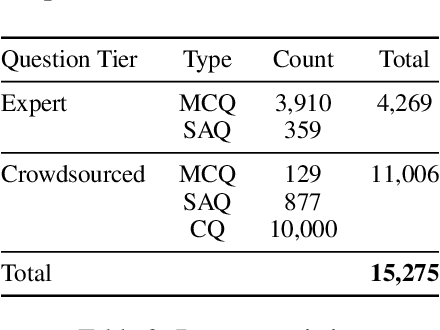

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024

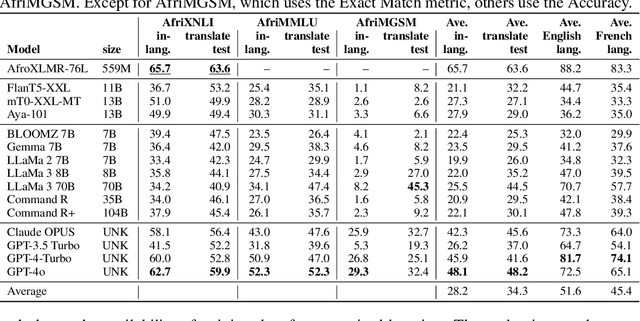
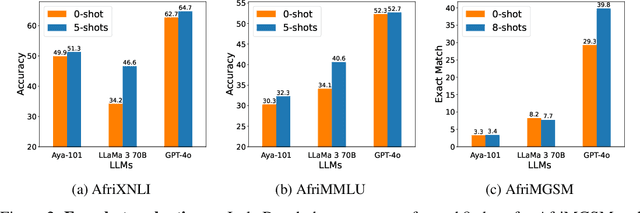
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023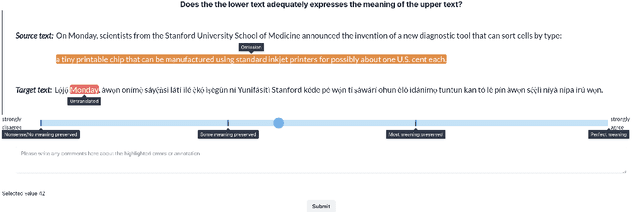
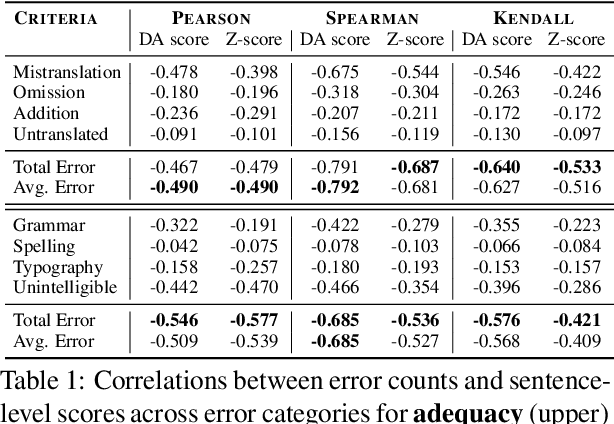
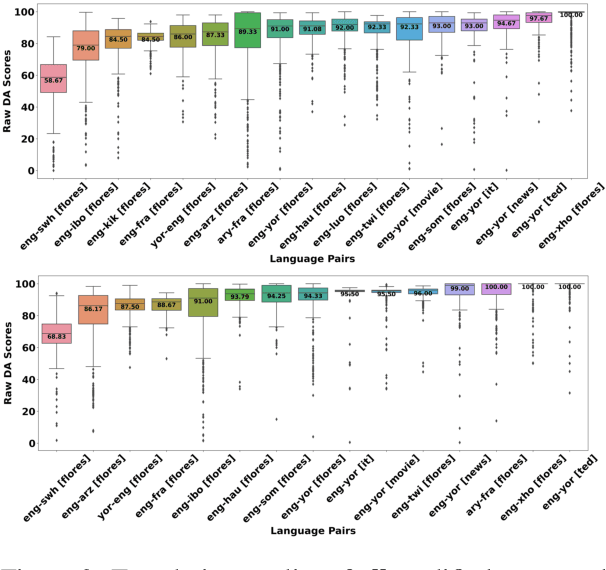
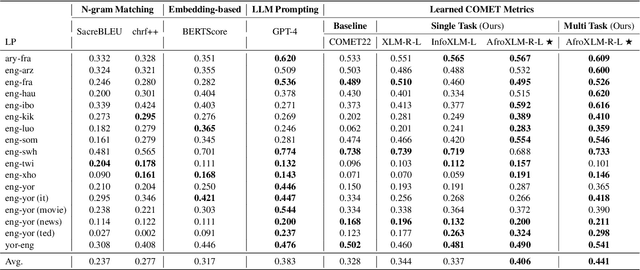
Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).