 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Approach for Mitigating Entity Bias in Relation Extraction
Jun 13, 2025Mitigating entity bias is a critical challenge in Relation Extraction (RE), where models often rely excessively on entities, resulting in poor generalization. This paper presents a novel approach to address this issue by adapting a Variational Information Bottleneck (VIB) framework. Our method compresses entity-specific information while preserving task-relevant features. It achieves state-of-the-art performance on relation extraction datasets across general, financial, and biomedical domains, in both indomain (original test sets) and out-of-domain (modified test sets with type-constrained entity replacements) settings. Our approach offers a robust, interpretable, and theoretically grounded methodology.
FinNLI: Novel Dataset for Multi-Genre Financial Natural Language Inference Benchmarking
Apr 22, 2025We introduce FinNLI, a benchmark dataset for Financial Natural Language Inference (FinNLI) across diverse financial texts like SEC Filings, Annual Reports, and Earnings Call transcripts. Our dataset framework ensures diverse premise-hypothesis pairs while minimizing spurious correlations. FinNLI comprises 21,304 pairs, including a high-quality test set of 3,304 instances annotated by finance experts. Evaluations show that domain shift significantly degrades general-domain NLI performance. The highest Macro F1 scores for pre-trained (PLMs) and large language models (LLMs) baselines are 74.57% and 78.62%, respectively, highlighting the dataset's difficulty. Surprisingly, instruction-tuned financial LLMs perform poorly, suggesting limited generalizability. FinNLI exposes weaknesses in current LLMs for financial reasoning, indicating room for improvement.
Scaling Crowdsourced Election Monitoring: Construction and Evaluation of Classification Models for Multilingual and Cross-Domain Classification Settings
Mar 05, 2025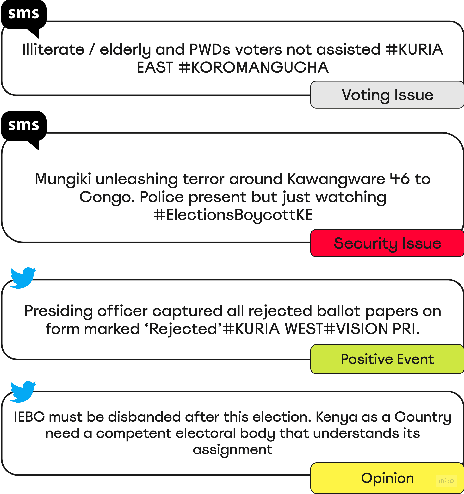
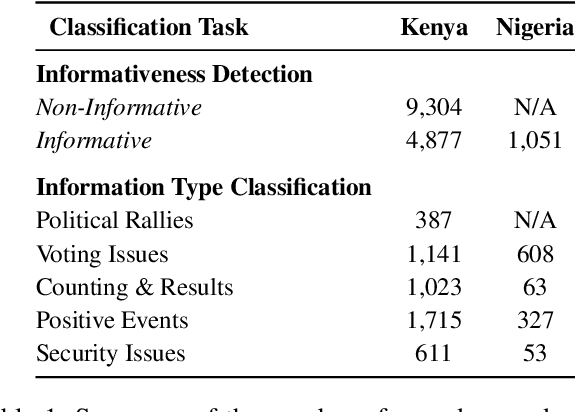
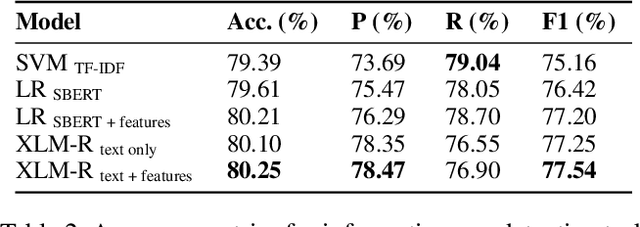
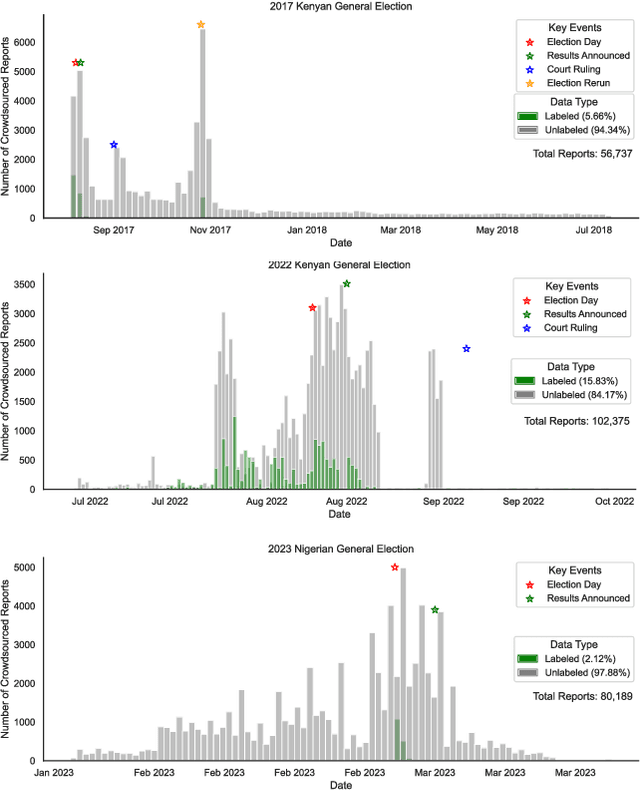
The adoption of crowdsourced election monitoring as a complementary alternative to traditional election monitoring is on the rise. Yet, its reliance on digital response volunteers to manually process incoming election reports poses a significant scaling bottleneck. In this paper, we address the challenge of scaling crowdsourced election monitoring by advancing the task of automated classification of crowdsourced election reports to multilingual and cross-domain classification settings. We propose a two-step classification approach of first identifying informative reports and then categorising them into distinct information types. We conduct classification experiments using multilingual transformer models such as XLM-RoBERTa and multilingual embeddings such as SBERT, augmented with linguistically motivated features. Our approach achieves F1-Scores of 77\% for informativeness detection and 75\% for information type classification. We conduct cross-domain experiments, applying models trained in a source electoral domain to a new target electoral domain in zero-shot and few-shot classification settings. Our results show promising potential for model transfer across electoral domains, with F1-Scores of 59\% in zero-shot and 63\% in few-shot settings. However, our analysis also reveals a performance bias in detecting informative English reports over Swahili, likely due to imbalances in the training data, indicating a need for caution when deploying classification models in real-world election scenarios.
When Claims Evolve: Evaluating and Enhancing the Robustness of Embedding Models Against Misinformation Edits
Mar 05, 2025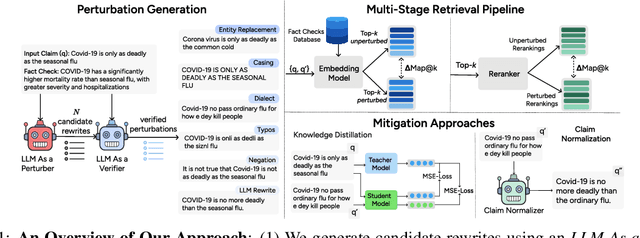
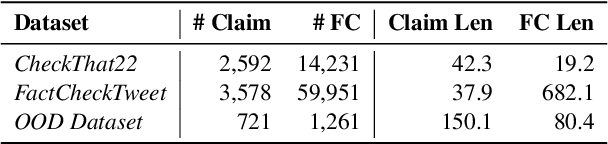
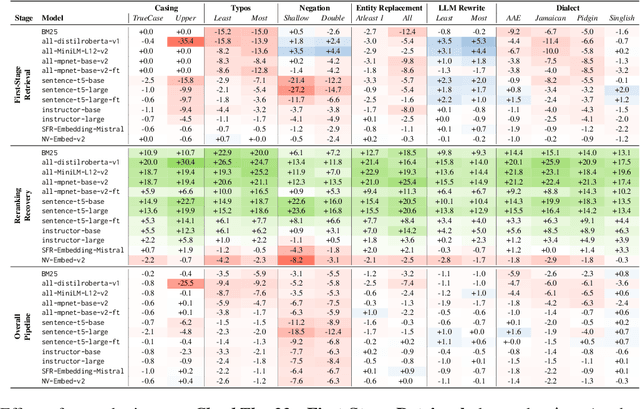
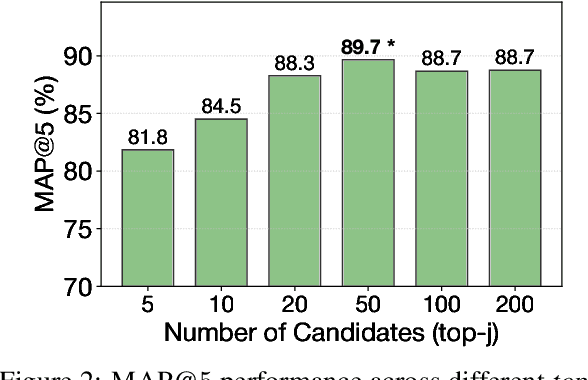
Online misinformation remains a critical challenge, and fact-checkers increasingly rely on embedding-based methods to retrieve relevant fact-checks. Yet, when debunked claims reappear in edited forms, the performance of these methods is unclear. In this work, we introduce a taxonomy of six common real-world misinformation edits and propose a perturbation framework that generates valid, natural claim variations. Our multi-stage retrieval evaluation reveals that standard embedding models struggle with user-introduced edits, while LLM-distilled embeddings offer improved robustness at a higher computational cost. Although a strong reranker helps mitigate some issues, it cannot fully compensate for first-stage retrieval gaps. Addressing these retrieval gaps, our train- and inference-time mitigation approaches enhance in-domain robustness by up to 17 percentage points and boost out-of-domain generalization by 10 percentage points over baseline models. Overall, our findings provide practical improvements to claim-matching systems, enabling more reliable fact-checking of evolving misinformation.
You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low-Resource and Extinct Languages
Jun 11, 2024



In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.