 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Tabular Language Models via Iterative Group Alignment
Apr 21, 2026While language models have been adapted for tabular data generation, two fundamental limitations remain: (1) static fine-tuning produces models that cannot learn from their own generated samples and adapt to self-correct, and (2) autoregressive objectives preserve local token coherence but neglect global statistical properties, degrading tabular quality. Reinforcement learning offers a potential solution but requires designing reward functions that balance competing objectives -- impractical for tabular data. To fill the gap, we introduce TabGRAA (Tabular Group-Relative Advantage Alignment), the first self-improving framework for tabular data generation via automated feedback. At each iteration, TabGRAA uses an \emph{automated quality signal} -- such as a two-sample distinguishability classifier or a distance-based reward -- to partition newly generated samples into high- and low-quality groups, then optimizes a group-relative advantage objective that reinforces realistic patterns while penalizing artifacts. The specific signal is a modular choice rather than a fixed component of the framework. This establishes a virtuous feedback cycle, where the quality signal is re-computed against newly \emph{generated synthetic} samples at each round; the language model is only fine-tuned on these self-generated signals, so no additional real record is exposed during alignment, mitigating data-leakage risk beyond the initial supervised fine-tuning. Experiments show TabGRAA outperforms existing methods in fidelity, utility, and privacy, while matching or exceeding diffusion-based synthesizers, advancing tabular synthesis from static statistical replication to dynamic, self-improving generation.
Accept or Deny? Evaluating LLM Fairness and Performance in Loan Approval across Table-to-Text Serialization Approaches
Aug 29, 2025



Large Language Models (LLMs) are increasingly employed in high-stakes decision-making tasks, such as loan approvals. While their applications expand across domains, LLMs struggle to process tabular data, ensuring fairness and delivering reliable predictions. In this work, we assess the performance and fairness of LLMs on serialized loan approval datasets from three geographically distinct regions: Ghana, Germany, and the United States. Our evaluation focuses on the model's zero-shot and in-context learning (ICL) capabilities. Our results reveal that the choice of serialization (Serialization refers to the process of converting tabular data into text formats suitable for processing by LLMs.) format significantly affects both performance and fairness in LLMs, with certain formats such as GReat and LIFT yielding higher F1 scores but exacerbating fairness disparities. Notably, while ICL improved model performance by 4.9-59.6% relative to zero-shot baselines, its effect on fairness varied considerably across datasets. Our work underscores the importance of effective tabular data representation methods and fairness-aware models to improve the reliability of LLMs in financial decision-making.
DP-2Stage: Adapting Language Models as Differentially Private Tabular Data Generators
Dec 03, 2024



Generating tabular data under differential privacy (DP) protection ensures theoretical privacy guarantees but poses challenges for training machine learning models, primarily due to the need to capture complex structures under noisy supervision signals. Recently, pre-trained Large Language Models (LLMs) -- even those at the scale of GPT-2 -- have demonstrated great potential in synthesizing tabular data. However, their applications under DP constraints remain largely unexplored. In this work, we address this gap by applying DP techniques to the generation of synthetic tabular data. Our findings shows that LLMs face difficulties in generating coherent text when fine-tuned with DP, as privacy budgets are inefficiently allocated to non-private elements like table structures. To overcome this, we propose \ours, a two-stage fine-tuning framework for differentially private tabular data generation. The first stage involves non-private fine-tuning on a pseudo dataset, followed by DP fine-tuning on a private dataset. Our empirical results show that this approach improves performance across various settings and metrics compared to directly fine-tuned LLMs in DP contexts. We release our code and setup at https://github.com/tejuafonja/DP-2Stage.
LLM4GRN: Discovering Causal Gene Regulatory Networks with LLMs -- Evaluation through Synthetic Data Generation
Oct 21, 2024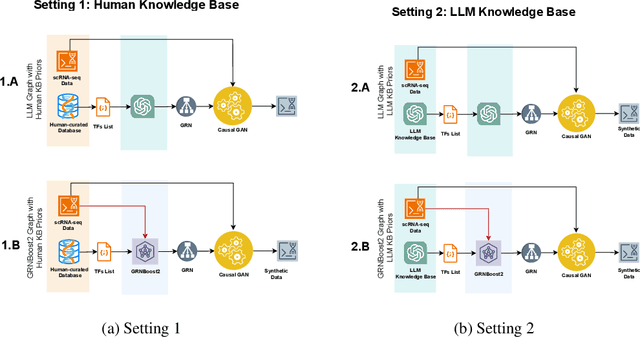



Gene regulatory networks (GRNs) represent the causal relationships between transcription factors (TFs) and target genes in single-cell RNA sequencing (scRNA-seq) data. Understanding these networks is crucial for uncovering disease mechanisms and identifying therapeutic targets. In this work, we investigate the potential of large language models (LLMs) for GRN discovery, leveraging their learned biological knowledge alone or in combination with traditional statistical methods. We develop a task-based evaluation strategy to address the challenge of unavailable ground truth causal graphs. Specifically, we use the GRNs suggested by LLMs to guide causal synthetic data generation and compare the resulting data against the original dataset. Our statistical and biological assessments show that LLMs can support statistical modeling and data synthesis for biological research.
Performant ASR Models for Medical Entities in Accented Speech
Jun 18, 2024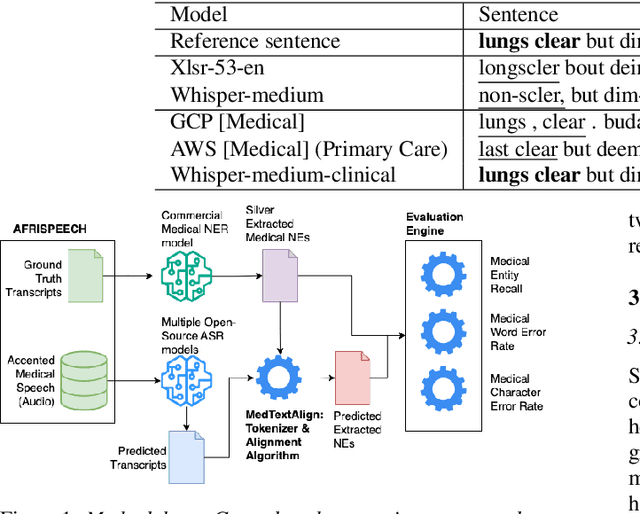



Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
1000 African Voices: Advancing inclusive multi-speaker multi-accent speech synthesis
Jun 17, 2024



Recent advances in speech synthesis have enabled many useful applications like audio directions in Google Maps, screen readers, and automated content generation on platforms like TikTok. However, these systems are mostly dominated by voices sourced from data-rich geographies with personas representative of their source data. Although 3000 of the world's languages are domiciled in Africa, African voices and personas are under-represented in these systems. As speech synthesis becomes increasingly democratized, it is desirable to increase the representation of African English accents. We present Afro-TTS, the first pan-African accented English speech synthesis system able to generate speech in 86 African accents, with 1000 personas representing the rich phonological diversity across the continent for downstream application in Education, Public Health, and Automated Content Creation. Speaker interpolation retains naturalness and accentedness, enabling the creation of new voices.
You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
Towards Biologically Plausible and Private Gene Expression Data Generation
Feb 07, 2024
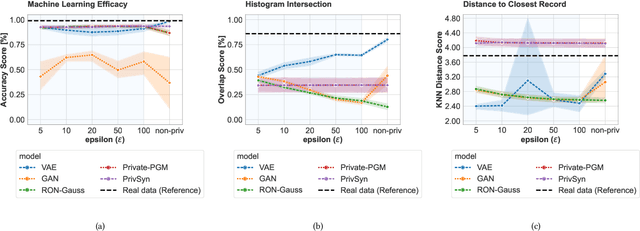

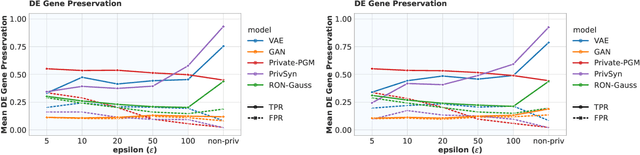
Generative models trained with Differential Privacy (DP) are becoming increasingly prominent in the creation of synthetic data for downstream applications. Existing literature, however, primarily focuses on basic benchmarking datasets and tends to report promising results only for elementary metrics and relatively simple data distributions. In this paper, we initiate a systematic analysis of how DP generative models perform in their natural application scenarios, specifically focusing on real-world gene expression data. We conduct a comprehensive analysis of five representative DP generation methods, examining them from various angles, such as downstream utility, statistical properties, and biological plausibility. Our extensive evaluation illuminates the unique characteristics of each DP generation method, offering critical insights into the strengths and weaknesses of each approach, and uncovering intriguing possibilities for future developments. Perhaps surprisingly, our analysis reveals that most methods are capable of achieving seemingly reasonable downstream utility, according to the standard evaluation metrics considered in existing literature. Nevertheless, we find that none of the DP methods are able to accurately capture the biological characteristics of the real dataset. This observation suggests a potential over-optimistic assessment of current methodologies in this field and underscores a pressing need for future enhancements in model design.
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
MargCTGAN: A "Marginally'' Better CTGAN for the Low Sample Regime
Jul 16, 2023The potential of realistic and useful synthetic data is significant. However, current evaluation methods for synthetic tabular data generation predominantly focus on downstream task usefulness, often neglecting the importance of statistical properties. This oversight becomes particularly prominent in low sample scenarios, accompanied by a swift deterioration of these statistical measures. In this paper, we address this issue by conducting an evaluation of three state-of-the-art synthetic tabular data generators based on their marginal distribution, column-pair correlation, joint distribution and downstream task utility performance across high to low sample regimes. The popular CTGAN model shows strong utility, but underperforms in low sample settings in terms of utility. To overcome this limitation, we propose MargCTGAN that adds feature matching of de-correlated marginals, which results in a consistent improvement in downstream utility as well as statistical properties of the synthetic data.