 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrispeech-Dialog: A Benchmark Dataset for Spontaneous English Conversations in Healthcare and Beyond
Feb 06, 2025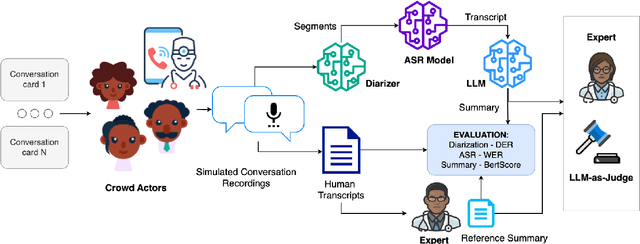


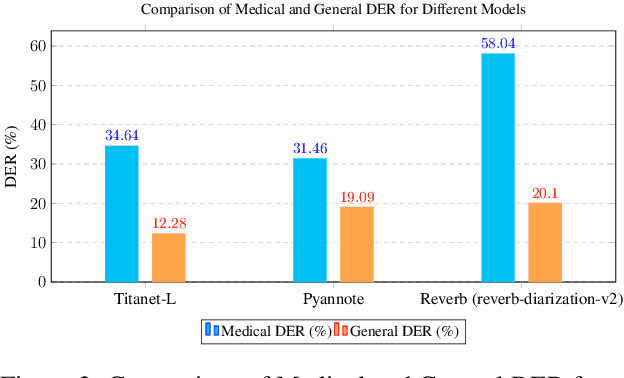
Speech technologies are transforming interactions across various sectors, from healthcare to call centers and robots, yet their performance on African-accented conversations remains underexplored. We introduce Afrispeech-Dialog, a benchmark dataset of 50 simulated medical and non-medical African-accented English conversations, designed to evaluate automatic speech recognition (ASR) and related technologies. We assess state-of-the-art (SOTA) speaker diarization and ASR systems on long-form, accented speech, comparing their performance with native accents and discover a 10%+ performance degradation. Additionally, we explore medical conversation summarization capabilities of large language models (LLMs) to demonstrate the impact of ASR errors on downstream medical summaries, providing insights into the challenges and opportunities for speech technologies in the Global South. Our work highlights the need for more inclusive datasets to advance conversational AI in low-resource settings.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

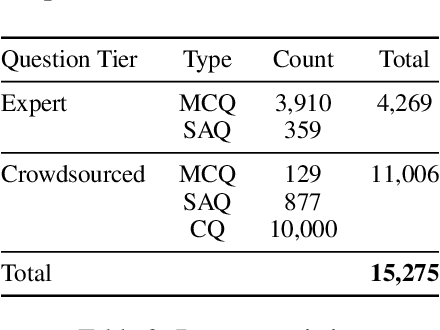

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
Performant ASR Models for Medical Entities in Accented Speech
Jun 18, 2024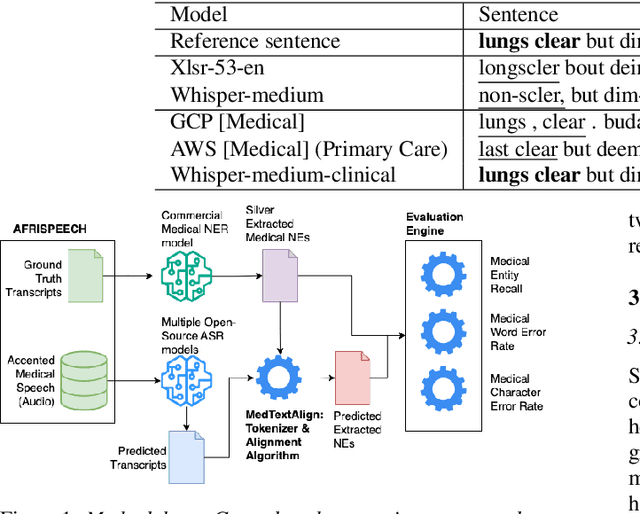



Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
The MICCAI Hackathon on reproducibility, diversity, and selection of papers at the MICCAI conference
Mar 04, 2021
The MICCAI conference has encountered tremendous growth over the last years in terms of the size of the community, as well as the number of contributions and their technical success. With this growth, however, come new challenges for the community. Methods are more difficult to reproduce and the ever-increasing number of paper submissions to the MICCAI conference poses new questions regarding the selection process and the diversity of topics. To exchange, discuss, and find novel and creative solutions to these challenges, a new format of a hackathon was initiated as a satellite event at the MICCAI 2020 conference: The MICCAI Hackathon. The first edition of the MICCAI Hackathon covered the topics reproducibility, diversity, and selection of MICCAI papers. In the manner of a small think-tank, participants collaborated to find solutions to these challenges. In this report, we summarize the insights from the MICCAI Hackathon into immediate and long-term measures to address these challenges. The proposed measures can be seen as starting points and guidelines for discussions and actions to possibly improve the MICCAI conference with regards to reproducibility, diversity, and selection of papers.