 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUbuntuGuard: A Culturally-Grounded Policy Benchmark for Equitable AI Safety in African Languages
Jan 19, 2026Current guardian models are predominantly Western-centric and optimized for high-resource languages, leaving low-resource African languages vulnerable to evolving harms, cross-lingual safety failures, and cultural misalignment. Moreover, most guardian models rely on rigid, predefined safety categories that fail to generalize across diverse linguistic and sociocultural contexts. Robust safety, therefore, requires flexible, runtime-enforceable policies and benchmarks that reflect local norms, harm scenarios, and cultural expectations. We introduce UbuntuGuard, the first African policy-based safety benchmark built from adversarial queries authored by 155 domain experts across sensitive fields, including healthcare. From these expert-crafted queries, we derive context-specific safety policies and reference responses that capture culturally grounded risk signals, enabling policy-aligned evaluation of guardian models. We evaluate 13 models, comprising six general-purpose LLMs and seven guardian models across three distinct variants: static, dynamic, and multilingual. Our findings reveal that existing English-centric benchmarks overestimate real-world multilingual safety, cross-lingual transfer provides partial but insufficient coverage, and dynamic models, while better equipped to leverage policies at inference time, still struggle to fully localize African-language contexts. These findings highlight the urgent need for multilingual, culturally grounded safety benchmarks to enable the development of reliable and equitable guardian models for low-resource languages. Our code can be found online.\footnote{Code repository available at https://github.com/hemhemoh/UbuntuGuard.
From Scarcity to Efficiency: Investigating the Effects of Data Augmentation on African Machine Translation
Sep 09, 2025The linguistic diversity across the African continent presents different challenges and opportunities for machine translation. This study explores the effects of data augmentation techniques in improving translation systems in low-resource African languages. We focus on two data augmentation techniques: sentence concatenation with back translation and switch-out, applying them across six African languages. Our experiments show significant improvements in machine translation performance, with a minimum increase of 25\% in BLEU score across all six languages.We provide a comprehensive analysis and highlight the potential of these techniques to improve machine translation systems for low-resource languages, contributing to the development of more robust translation systems for under-resourced languages.
The NaijaVoices Dataset: Cultivating Large-Scale, High-Quality, Culturally-Rich Speech Data for African Languages
May 26, 2025The development of high-performing, robust, and reliable speech technologies depends on large, high-quality datasets. However, African languages -- including our focus, Igbo, Hausa, and Yoruba -- remain under-represented due to insufficient data. Popular voice-enabled technologies do not support any of the 2000+ African languages, limiting accessibility for circa one billion people. While previous dataset efforts exist for the target languages, they lack the scale and diversity needed for robust speech models. To bridge this gap, we introduce the NaijaVoices dataset, a 1,800-hour speech-text dataset with 5,000+ speakers. We outline our unique data collection approach, analyze its acoustic diversity, and demonstrate its impact through finetuning experiments on automatic speech recognition, averagely achieving 75.86% (Whisper), 52.06% (MMS), and 42.33% (XLSR) WER improvements. These results highlight NaijaVoices' potential to advance multilingual speech processing for African languages.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

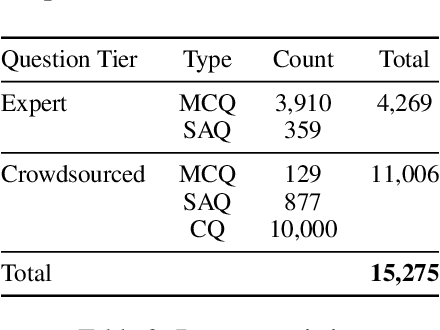

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
Performant ASR Models for Medical Entities in Accented Speech
Jun 18, 2024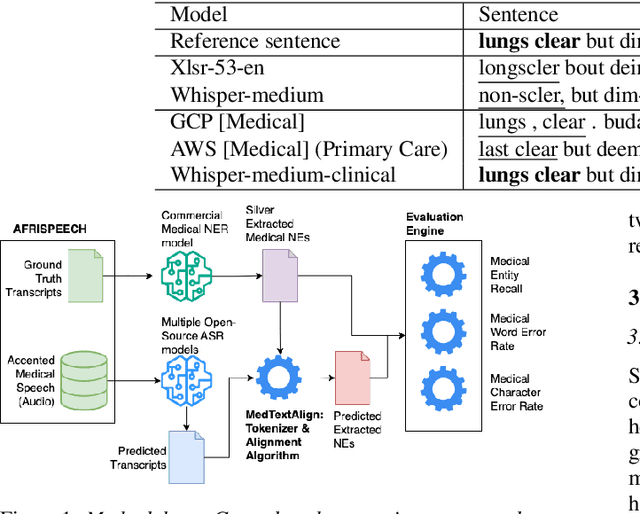



Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
Bloom Library: Multimodal Datasets in 300+ Languages for a Variety of Downstream Tasks
Oct 26, 2022
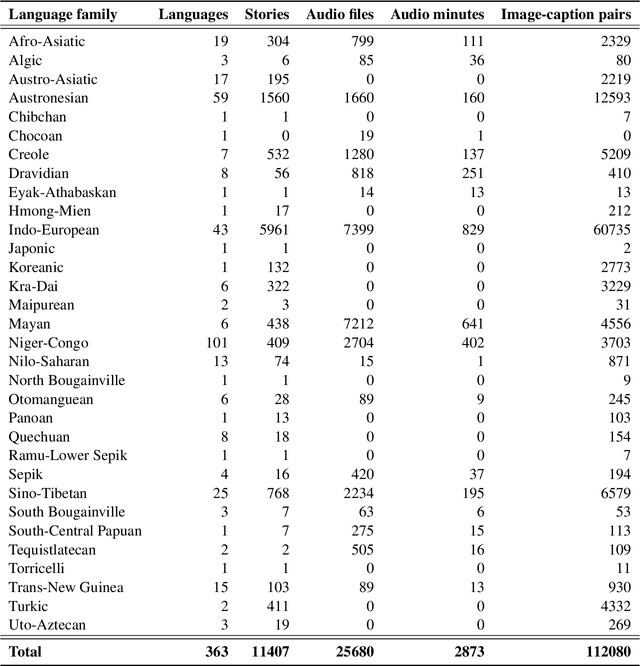
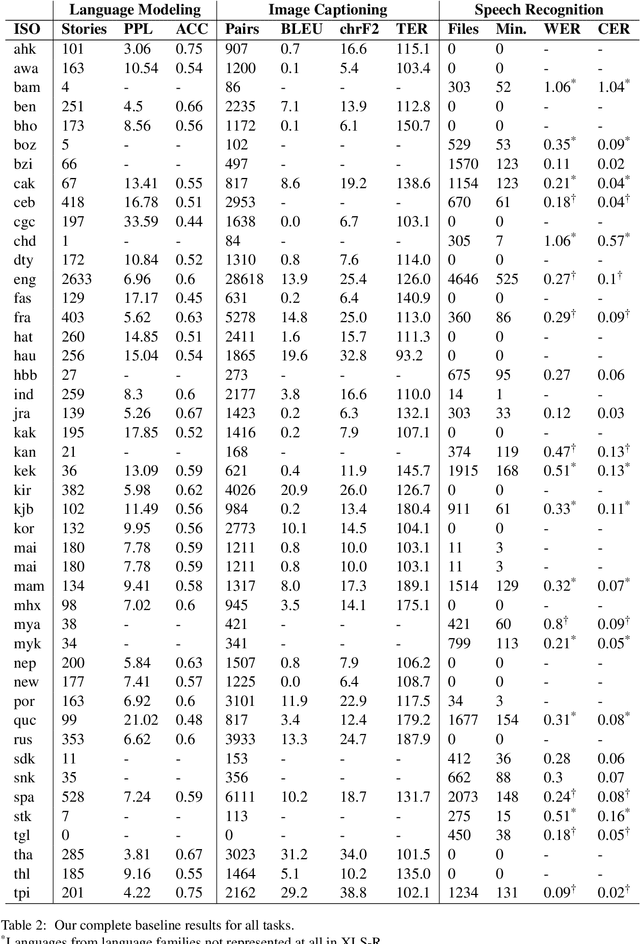
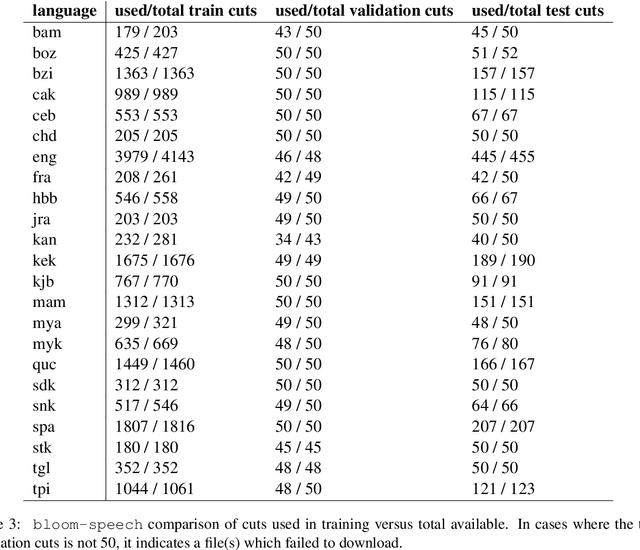
We present Bloom Library, a linguistically diverse set of multimodal and multilingual datasets for language modeling, image captioning, visual storytelling, and speech synthesis/recognition. These datasets represent either the most, or among the most, multilingual datasets for each of the included downstream tasks. In total, the initial release of the Bloom Library datasets covers 363 languages across 32 language families. We train downstream task models for various languages represented in the data, showing the viability of the data for future work in low-resource, multimodal NLP and establishing the first known baselines for these downstream tasks in certain languages (e.g., Bisu [bzi], with an estimated population of 700 users). Some of these first-of-their-kind baselines are comparable to state-of-the-art performance for higher-resourced languages. The Bloom Library datasets are released under Creative Commons licenses on the Hugging Face datasets hub to catalyze more linguistically diverse research in the included downstream tasks.
* 14 pages, 1 figure, 3 tables, accepted to and presented at EMNLP 2022