 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAG-MMLU: Benchmarking Frontier LLM Understanding in Latvian and Giriama
Mar 14, 2025



As large language models (LLMs) rapidly advance, evaluating their performance is critical. LLMs are trained on multilingual data, but their reasoning abilities are mainly evaluated using English datasets. Hence, robust evaluation frameworks are needed using high-quality non-English datasets, especially low-resource languages (LRLs). This study evaluates eight state-of-the-art (SOTA) LLMs on Latvian and Giriama using a Massive Multitask Language Understanding (MMLU) subset curated with native speakers for linguistic and cultural relevance. Giriama is benchmarked for the first time. Our evaluation shows that OpenAI's o1 model outperforms others across all languages, scoring 92.8\% in English, 88.8\% in Latvian, and 70.8\% in Giriama on 0-shot tasks. Mistral-large (35.6\%) and Llama-70B IT (41\%) have weak performance, on both Latvian and Giriama. Our results underscore the need for localized benchmarks and human evaluations in advancing cultural AI contextualization.
* Accepted in NoDaLiDa/Baltic-HLT 2025
RideKE: Leveraging Low-Resource, User-Generated Twitter Content for Sentiment and Emotion Detection in Kenyan Code-Switched Dataset
Feb 10, 2025Social media has become a crucial open-access platform for individuals to express opinions and share experiences. However, leveraging low-resource language data from Twitter is challenging due to scarce, poor-quality content and the major variations in language use, such as slang and code-switching. Identifying tweets in these languages can be difficult as Twitter primarily supports high-resource languages. We analyze Kenyan code-switched data and evaluate four state-of-the-art (SOTA) transformer-based pretrained models for sentiment and emotion classification, using supervised and semi-supervised methods. We detail the methodology behind data collection and annotation, and the challenges encountered during the data curation phase. Our results show that XLM-R outperforms other models; for sentiment analysis, XLM-R supervised model achieves the highest accuracy (69.2\%) and F1 score (66.1\%), XLM-R semi-supervised (67.2\% accuracy, 64.1\% F1 score). In emotion analysis, DistilBERT supervised leads in accuracy (59.8\%) and F1 score (31\%), mBERT semi-supervised (accuracy (59\% and F1 score 26.5\%). AfriBERTa models show the lowest accuracy and F1 scores. All models tend to predict neutral sentiment, with Afri-BERT showing the highest bias and unique sensitivity to empathy emotion. https://github.com/NEtori21/Ride_hailing
* Accepted in WASSA 2024
Afrispeech-Dialog: A Benchmark Dataset for Spontaneous English Conversations in Healthcare and Beyond
Feb 06, 2025Speech technologies are transforming interactions across various sectors, from healthcare to call centers and robots, yet their performance on African-accented conversations remains underexplored. We introduce Afrispeech-Dialog, a benchmark dataset of 50 simulated medical and non-medical African-accented English conversations, designed to evaluate automatic speech recognition (ASR) and related technologies. We assess state-of-the-art (SOTA) speaker diarization and ASR systems on long-form, accented speech, comparing their performance with native accents and discover a 10%+ performance degradation. Additionally, we explore medical conversation summarization capabilities of large language models (LLMs) to demonstrate the impact of ASR errors on downstream medical summaries, providing insights into the challenges and opportunities for speech technologies in the Global South. Our work highlights the need for more inclusive datasets to advance conversational AI in low-resource settings.
Uhura: A Benchmark for Evaluating Scientific Question Answering and Truthfulness in Low-Resource African Languages
Dec 01, 2024



Evaluations of Large Language Models (LLMs) on knowledge-intensive tasks and factual accuracy often focus on high-resource languages primarily because datasets for low-resource languages (LRLs) are scarce. In this paper, we present Uhura -- a new benchmark that focuses on two tasks in six typologically-diverse African languages, created via human translation of existing English benchmarks. The first dataset, Uhura-ARC-Easy, is composed of multiple-choice science questions. The second, Uhura-TruthfulQA, is a safety benchmark testing the truthfulness of models on topics including health, law, finance, and politics. We highlight the challenges creating benchmarks with highly technical content for LRLs and outline mitigation strategies. Our evaluation reveals a significant performance gap between proprietary models such as GPT-4o and o1-preview, and Claude models, and open-source models like Meta's LLaMA and Google's Gemma. Additionally, all models perform better in English than in African languages. These results indicate that LMs struggle with answering scientific questions and are more prone to generating false claims in low-resource African languages. Our findings underscore the necessity for continuous improvement of multilingual LM capabilities in LRL settings to ensure safe and reliable use in real-world contexts. We open-source the Uhura Benchmark and Uhura Platform to foster further research and development in NLP for LRLs.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

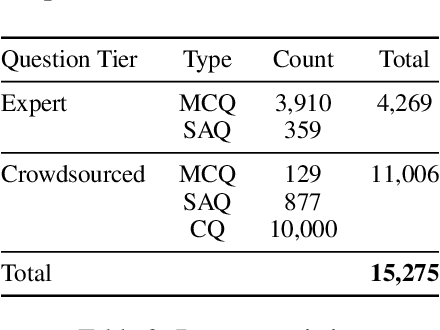

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
State of NLP in Kenya: A Survey
Oct 13, 2024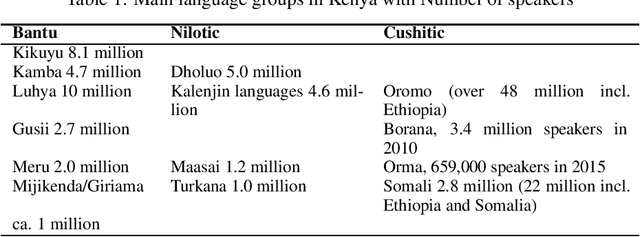
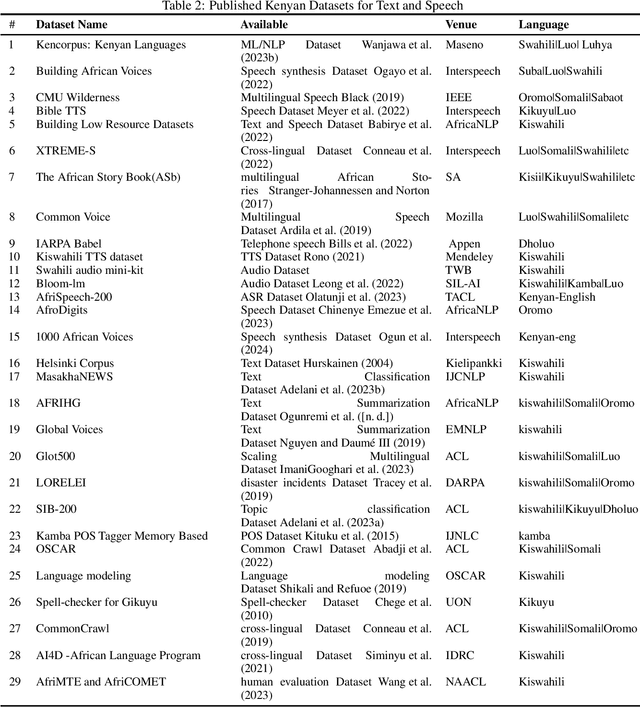
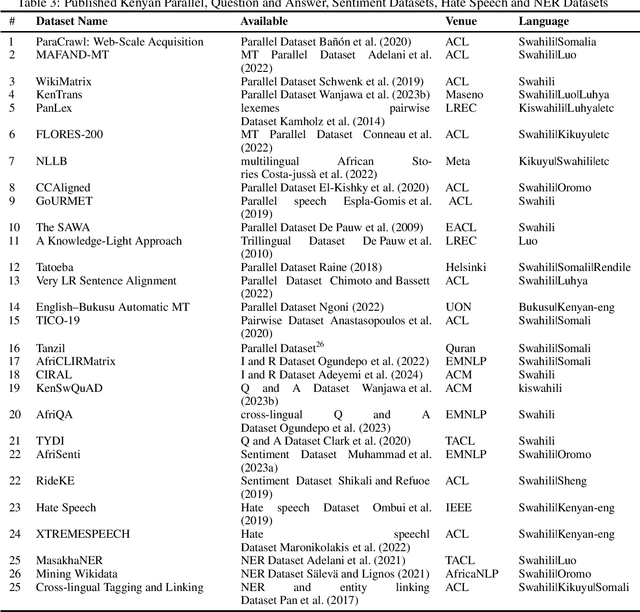
Kenya, known for its linguistic diversity, faces unique challenges and promising opportunities in advancing Natural Language Processing (NLP) technologies, particularly for its underrepresented indigenous languages. This survey provides a detailed assessment of the current state of NLP in Kenya, emphasizing ongoing efforts in dataset creation, machine translation, sentiment analysis, and speech recognition for local dialects such as Kiswahili, Dholuo, Kikuyu, and Luhya. Despite these advancements, the development of NLP in Kenya remains constrained by limited resources and tools, resulting in the underrepresentation of most indigenous languages in digital spaces. This paper uncovers significant gaps by critically evaluating the available datasets and existing NLP models, most notably the need for large-scale language models and the insufficient digital representation of Indigenous languages. We also analyze key NLP applications: machine translation, information retrieval, and sentiment analysis-examining how they are tailored to address local linguistic needs. Furthermore, the paper explores the governance, policies, and regulations shaping the future of AI and NLP in Kenya and proposes a strategic roadmap to guide future research and development efforts. Our goal is to provide a foundation for accelerating the growth of NLP technologies that meet Kenya's diverse linguistic demands.
Performant ASR Models for Medical Entities in Accented Speech
Jun 18, 2024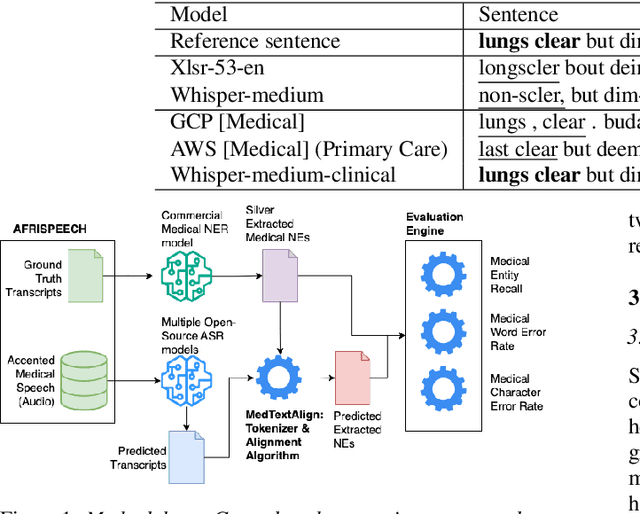



Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
1000 African Voices: Advancing inclusive multi-speaker multi-accent speech synthesis
Jun 17, 2024Recent advances in speech synthesis have enabled many useful applications like audio directions in Google Maps, screen readers, and automated content generation on platforms like TikTok. However, these systems are mostly dominated by voices sourced from data-rich geographies with personas representative of their source data. Although 3000 of the world's languages are domiciled in Africa, African voices and personas are under-represented in these systems. As speech synthesis becomes increasingly democratized, it is desirable to increase the representation of African English accents. We present Afro-TTS, the first pan-African accented English speech synthesis system able to generate speech in 86 African accents, with 1000 personas representing the rich phonological diversity across the continent for downstream application in Education, Public Health, and Automated Content Creation. Speaker interpolation retains naturalness and accentedness, enabling the creation of new voices.
Kreyòl-MT: Building MT for Latin American, Caribbean and Colonial African Creole Languages
May 08, 2024



A majority of language technologies are tailored for a small number of high-resource languages, while relatively many low-resource languages are neglected. One such group, Creole languages, have long been marginalized in academic study, though their speakers could benefit from machine translation (MT). These languages are predominantly used in much of Latin America, Africa and the Caribbean. We present the largest cumulative dataset to date for Creole language MT, including 14.5M unique Creole sentences with parallel translations -- 11.6M of which we release publicly, and the largest bitexts gathered to date for 41 languages -- the first ever for 21. In addition, we provide MT models supporting all 41 Creole languages in 172 translation directions. Given our diverse dataset, we produce a model for Creole language MT exposed to more genre diversity than ever before, which outperforms a genre-specific Creole MT model on its own benchmark for 23 of 34 translation directions.
TEXT2TASTE: A Versatile Egocentric Vision System for Intelligent Reading Assistance Using Large Language Model
Apr 14, 2024The ability to read, understand and find important information from written text is a critical skill in our daily lives for our independence, comfort and safety. However, a significant part of our society is affected by partial vision impairment, which leads to discomfort and dependency in daily activities. To address the limitations of this part of society, we propose an intelligent reading assistant based on smart glasses with embedded RGB cameras and a Large Language Model (LLM), whose functionality goes beyond corrective lenses. The video recorded from the egocentric perspective of a person wearing the glasses is processed to localise text information using object detection and optical character recognition methods. The LLM processes the data and allows the user to interact with the text and responds to a given query, thus extending the functionality of corrective lenses with the ability to find and summarize knowledge from the text. To evaluate our method, we create a chat-based application that allows the user to interact with the system. The evaluation is conducted in a real-world setting, such as reading menus in a restaurant, and involves four participants. The results show robust accuracy in text retrieval. The system not only provides accurate meal suggestions but also achieves high user satisfaction, highlighting the potential of smart glasses and LLMs in assisting people with special needs.