 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale cloze evaluation reveals that token prediction tasks are neither lexically nor semantically aligned
Oct 15, 2024In this work we compare the generative behavior at the next token prediction level in several language models by comparing them to human productions in the cloze task. We find that while large models trained for longer are typically better estimators of human productions, but they reliably under-estimate the probabilities of human responses, over-rank rare responses, under-rank top responses, and produce highly distinct semantic spaces. Altogether, this work demonstrates in a tractable, interpretable domain that LM generations can not be used as replacements of or models of the cloze task.
Kreyòl-MT: Building MT for Latin American, Caribbean and Colonial African Creole Languages
May 08, 2024



A majority of language technologies are tailored for a small number of high-resource languages, while relatively many low-resource languages are neglected. One such group, Creole languages, have long been marginalized in academic study, though their speakers could benefit from machine translation (MT). These languages are predominantly used in much of Latin America, Africa and the Caribbean. We present the largest cumulative dataset to date for Creole language MT, including 14.5M unique Creole sentences with parallel translations -- 11.6M of which we release publicly, and the largest bitexts gathered to date for 41 languages -- the first ever for 21. In addition, we provide MT models supporting all 41 Creole languages in 172 translation directions. Given our diverse dataset, we produce a model for Creole language MT exposed to more genre diversity than ever before, which outperforms a genre-specific Creole MT model on its own benchmark for 23 of 34 translation directions.
CreoleVal: Multilingual Multitask Benchmarks for Creoles
Oct 30, 2023Creoles represent an under-explored and marginalized group of languages, with few available resources for NLP research. While the genealogical ties between Creoles and other highly-resourced languages imply a significant potential for transfer learning, this potential is hampered due to this lack of annotated data. In this work we present CreoleVal, a collection of benchmark datasets spanning 8 different NLP tasks, covering up to 28 Creole languages; it is an aggregate of brand new development datasets for machine comprehension, relation classification, and machine translation for Creoles, in addition to a practical gateway to a handful of preexisting benchmarks. For each benchmark, we conduct baseline experiments in a zero-shot setting in order to further ascertain the capabilities and limitations of transfer learning for Creoles. Ultimately, the goal of CreoleVal is to empower research on Creoles in NLP and computational linguistics. We hope this resource will contribute to technological inclusion for Creole language users around the globe.
Hybrid Neural Models For Sequence Modelling: The Best Of Three Worlds
Sep 16, 2019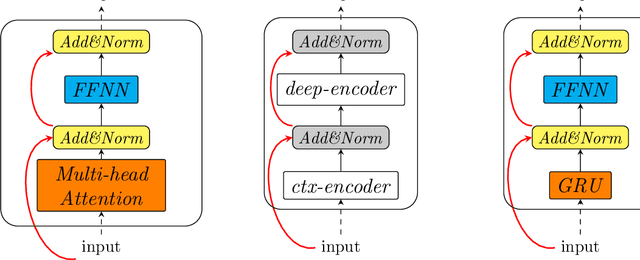


We propose a neural architecture with the main characteristics of the most successful neural models of the last years: bidirectional RNNs, encoder-decoder, and the Transformer model. Evaluation on three sequence labelling tasks yields results that are close to the state-of-the-art for all tasks and better than it for some of them, showing the pertinence of this hybrid architecture for this kind of tasks.
Seq2Biseq: Bidirectional Output-wise Recurrent Neural Networks for Sequence Modelling
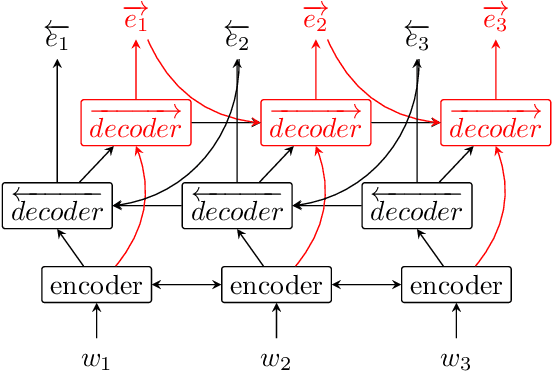
Apr 16, 2019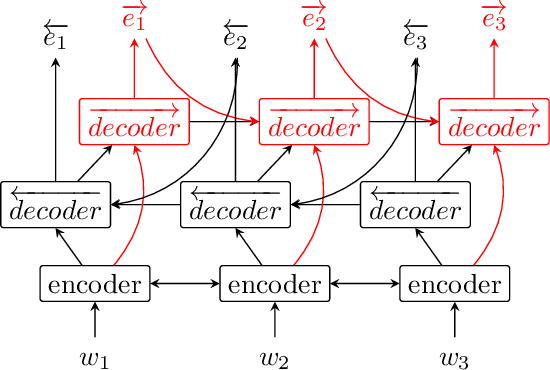
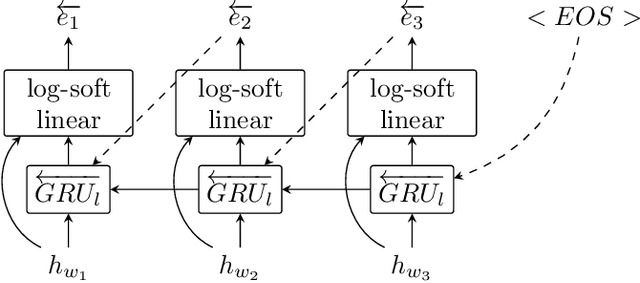
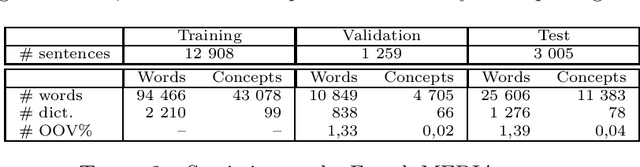
During the last couple of years, Recurrent Neural Networks (RNN) have reached state-of-the-art performances on most of the sequence modelling problems. In particular, the "sequence to sequence" model and the neural CRF have proved to be very effective in this domain. In this article, we propose a new RNN architecture for sequence labelling, leveraging gated recurrent layers to take arbitrarily long contexts into account, and using two decoders operating forward and backward. We compare several variants of the proposed solution and their performances to the state-of-the-art. Most of our results are better than the state-of-the-art or very close to it and thanks to the use of recent technologies, our architecture can scale on corpora larger than those used in this work.