 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Data Selection Strategies for Pre-training Self-Supervised Speech Models
Jan 28, 2026Self-supervised learning (SSL) has transformed speech processing, yet its reliance on massive pre-training datasets remains a bottleneck. While robustness is often attributed to scale and diversity, the role of the data distribution is less understood. We systematically examine how curated subsets of pre-training data influence Automatic Speech Recognition (ASR) performance. Surprisingly, optimizing for acoustic, speaker, or linguistic diversity yields no clear improvements over random sampling. Instead, we find that prioritizing the longest utterances achieves superior ASR results while using only half the original dataset, reducing pre-training time by 24% on a large corpora. These findings suggest that for pre-training speech SSL models, data length is a more critical factor than either data diversity or overall data quantity for performance and efficiency, offering a new perspective for data selection strategies in SSL speech processing.
Pantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
DOLFIN -- Document-Level Financial test set for Machine Translation
Feb 05, 2025Despite the strong research interest in document-level Machine Translation (MT), the test sets dedicated to this task are still scarce. The existing test sets mainly cover topics from the general domain and fall short on specialised domains, such as legal and financial. Also, in spite of their document-level aspect, they still follow a sentence-level logic that does not allow for including certain linguistic phenomena such as information reorganisation. In this work, we aim to fill this gap by proposing a novel test set: DOLFIN. The dataset is built from specialised financial documents, and it makes a step towards true document-level MT by abandoning the paradigm of perfectly aligned sentences, presenting data in units of sections rather than sentences. The test set consists of an average of 1950 aligned sections for five language pairs. We present a detailed data collection pipeline that can serve as inspiration for aligning new document-level datasets. We demonstrate the usefulness and quality of this test set by evaluating a number of models. Our results show that the test set is able to discriminate between context-sensitive and context-agnostic models and shows the weaknesses when models fail to accurately translate financial texts. The test set is made public for the community.
Towards Early Prediction of Self-Supervised Speech Model Performance
Jan 10, 2025


In Self-Supervised Learning (SSL), pre-training and evaluation are resource intensive. In the speech domain, current indicators of the quality of SSL models during pre-training, such as the loss, do not correlate well with downstream performance. Consequently, it is often difficult to gauge the final downstream performance in a cost efficient manner during pre-training. In this work, we propose unsupervised efficient methods that give insights into the quality of the pre-training of SSL speech models, namely, measuring the cluster quality and rank of the embeddings of the SSL model. Results show that measures of cluster quality and rank correlate better with downstream performance than the pre-training loss with only one hour of unlabeled audio, reducing the need for GPU hours and labeled data in SSL model evaluation.
An Analysis of Linear Complexity Attention Substitutes with BEST-RQ
Sep 04, 2024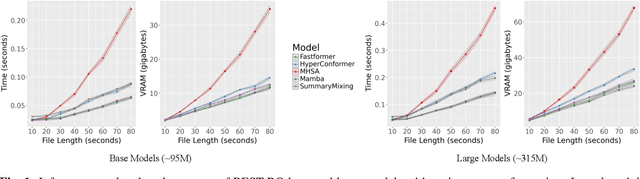
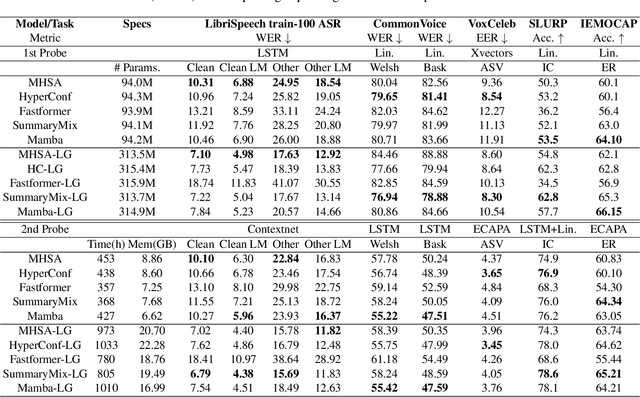
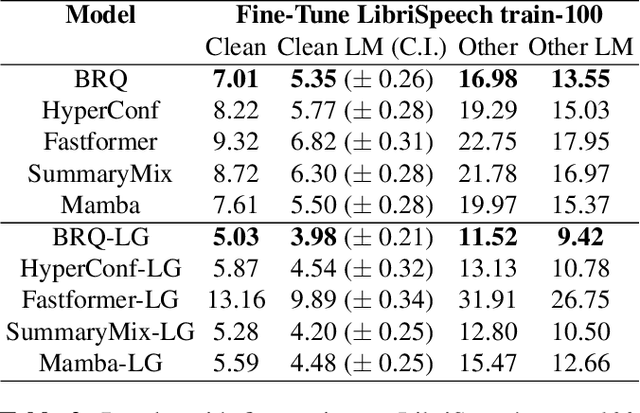
Self-Supervised Learning (SSL) has proven to be effective in various domains, including speech processing. However, SSL is computationally and memory expensive. This is in part due the quadratic complexity of multi-head self-attention (MHSA). Alternatives for MHSA have been proposed and used in the speech domain, but have yet to be investigated properly in an SSL setting. In this work, we study the effects of replacing MHSA with recent state-of-the-art alternatives that have linear complexity, namely, HyperMixing, Fastformer, SummaryMixing, and Mamba. We evaluate these methods by looking at the speed, the amount of VRAM consumed, and the performance on the SSL MP3S benchmark. Results show that these linear alternatives maintain competitive performance compared to MHSA while, on average, decreasing VRAM consumption by around 20% to 60% and increasing speed from 7% to 65% for input sequences ranging from 20 to 80 seconds.
Open Implementation and Study of BEST-RQ for Speech Processing
May 07, 2024Self-Supervised Learning (SSL) has proven to be useful in various speech tasks. However, these methods are generally very demanding in terms of data, memory, and computational resources. BERT-based Speech pre-Training with Random-projection Quantizer (BEST-RQ), is an SSL method that has shown great performance on Automatic Speech Recognition (ASR) while being simpler than other SSL methods, such as wav2vec 2.0. Despite BEST-RQ's great performance, details are lacking in the original paper, such as the amount of GPU/TPU hours used in pre-training, and there is no official easy-to-use open-source implementation. Furthermore, BEST-RQ has not been evaluated on other downstream tasks aside from ASR and speech translation. In this work, we describe a re-implementation of a Random-projection quantizer and perform a preliminary study with a comparison to wav2vec 2.0 on four downstream tasks. We discuss the details and differences of our implementation. We show that a random projection quantizer can achieve similar downstream performance as wav2vec 2.0 while decreasing training time by over a factor of two.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Encoding Sentence Position in Context-Aware Neural Machine Translation with Concatenation
Feb 13, 2023
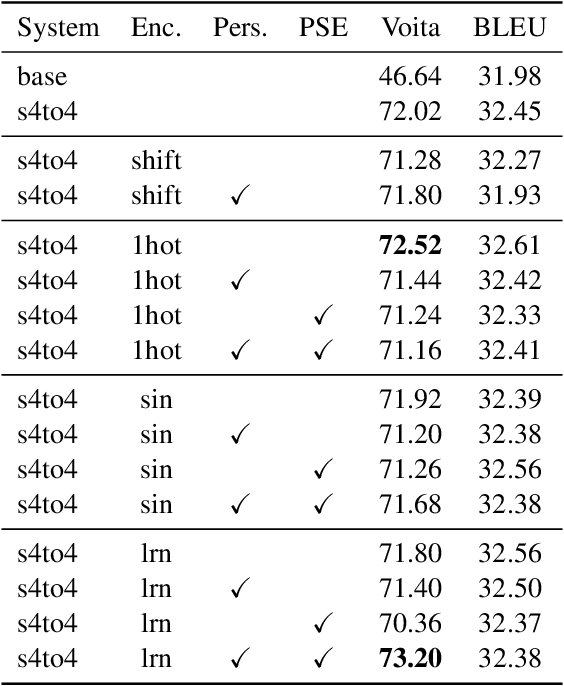
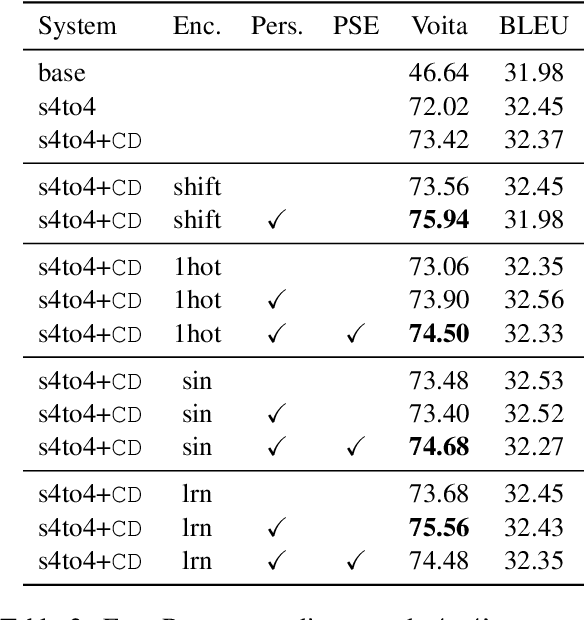
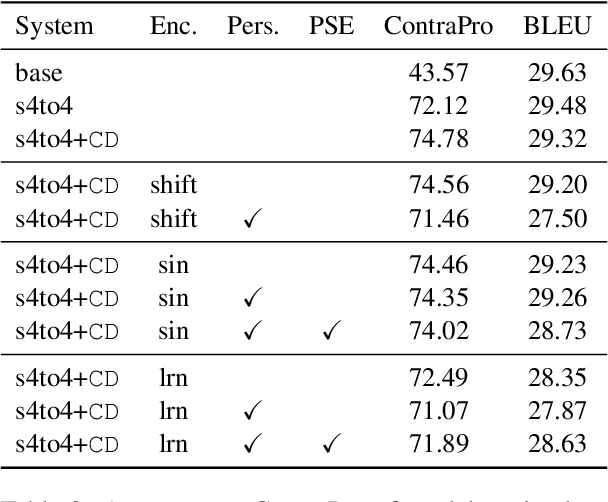
Context-aware translation can be achieved by processing a concatenation of consecutive sentences with the standard translation approach. This paper investigates the intuitive idea of adopting segment embeddings for this task to help the Transformer discern the position of each sentence in the concatenation sequence. We compare various segment embeddings and propose novel methods to encode sentence position into token representations, showing that they do not benefit the vanilla concatenation approach except in a specific setting.
Focused Concatenation for Context-Aware Neural Machine Translation
Oct 24, 2022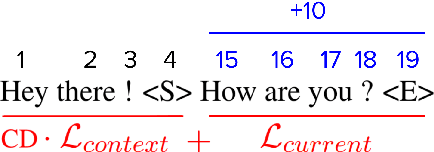
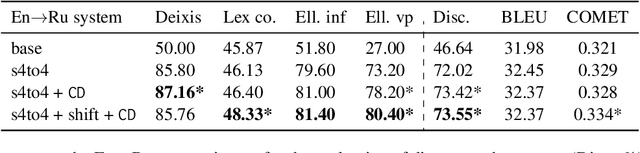
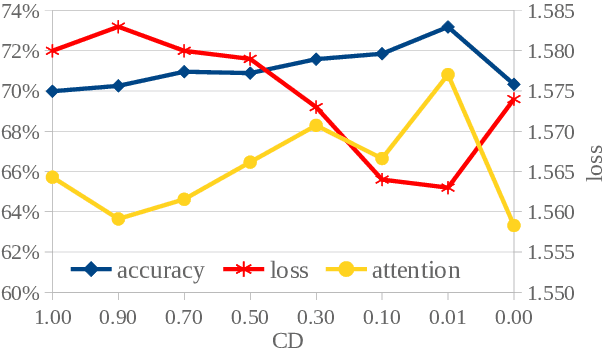
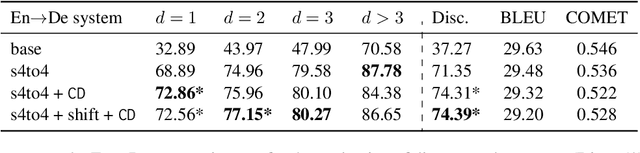
A straightforward approach to context-aware neural machine translation consists in feeding the standard encoder-decoder architecture with a window of consecutive sentences, formed by the current sentence and a number of sentences from its context concatenated to it. In this work, we propose an improved concatenation approach that encourages the model to focus on the translation of the current sentence, discounting the loss generated by target context. We also propose an additional improvement that strengthen the notion of sentence boundaries and of relative sentence distance, facilitating model compliance to the context-discounted objective. We evaluate our approach with both average-translation quality metrics and contrastive test sets for the translation of inter-sentential discourse phenomena, proving its superiority to the vanilla concatenation approach and other sophisticated context-aware systems.
TArC: Tunisian Arabish Corpus First complete release
Jul 11, 2022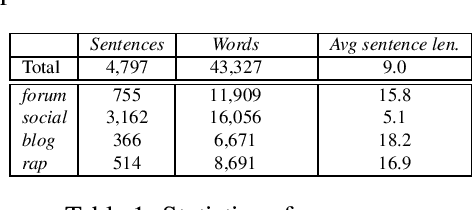
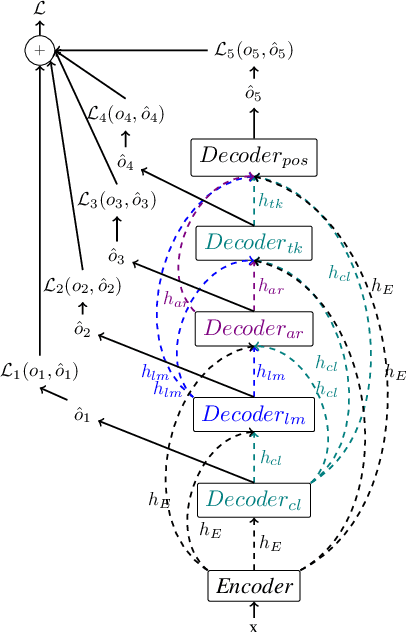
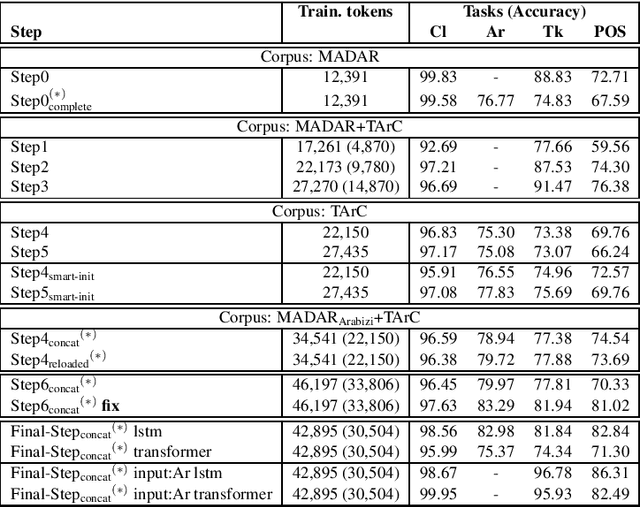
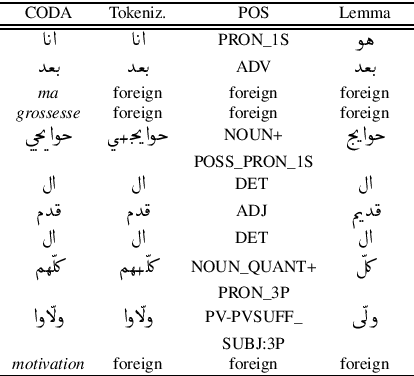
In this paper we present the final result of a project on Tunisian Arabic encoded in Arabizi, the Latin-based writing system for digital conversations. The project led to the creation of two integrated and independent resources: a corpus and a NLP tool created to annotate the former with various levels of linguistic information: word classification, transliteration, tokenization, POS-tagging, lemmatization. We discuss our choices in terms of computational and linguistic methodology and the strategies adopted to improve our results. We report on the experiments performed in order to outline our research path. Finally, we explain why we believe in the potential of these resources for both computational and linguistic researches. Keywords: Tunisian Arabizi, Annotated Corpus, Neural Network Architecture