 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADIT: A Dataset for Demographic Classification of Italian Twitter Users and a Comparison of Prediction Methods
Mar 08, 2024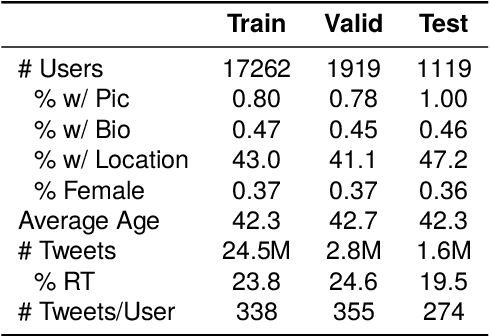
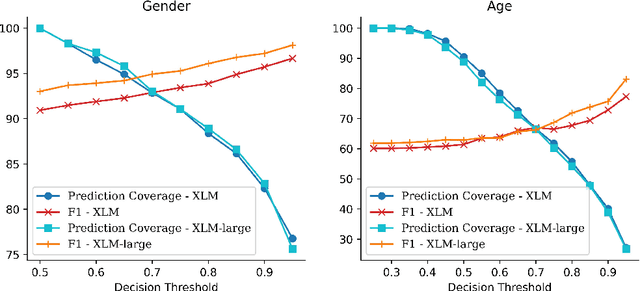
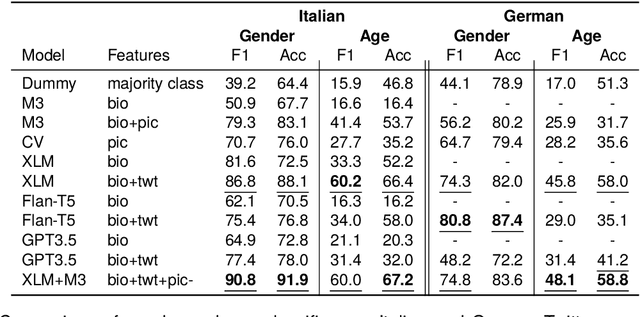
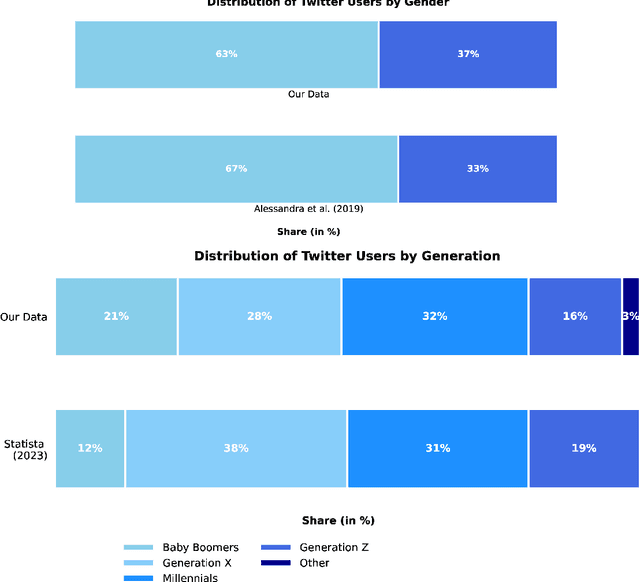
Social scientists increasingly use demographically stratified social media data to study the attitudes, beliefs, and behavior of the general public. To facilitate such analyses, we construct, validate, and release publicly the representative DADIT dataset of 30M tweets of 20k Italian Twitter users, along with their bios and profile pictures. We enrich the user data with high-quality labels for gender, age, and location. DADIT enables us to train and compare the performance of various state-of-the-art models for the prediction of the gender and age of social media users. In particular, we investigate if tweets contain valuable information for the task, since popular classifiers like M3 don't leverage them. Our best XLM-based classifier improves upon the commonly used competitor M3 by up to 53% F1. Especially for age prediction, classifiers profit from including tweets as features. We also confirm these findings on a German test set.
How to Use Large Language Models for Text Coding: The Case of Fatherhood Roles in Public Policy Documents
Nov 20, 2023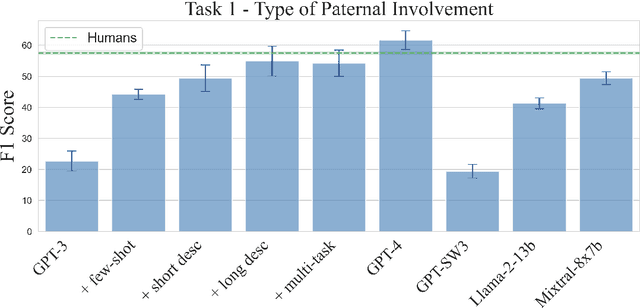
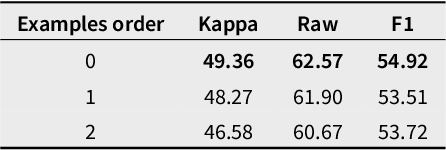
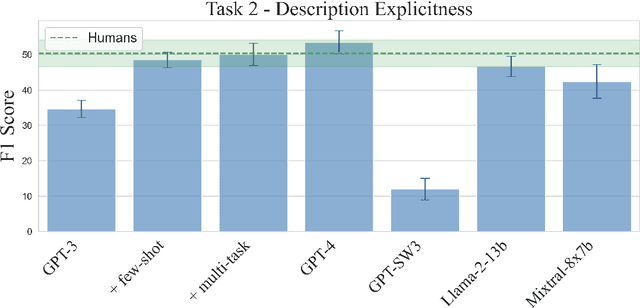
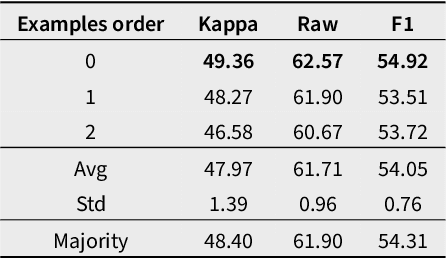
Recent advances in large language models (LLMs) like GPT-3 and GPT-4 have opened up new opportunities for text analysis in political science. They promise automation with better results and less programming. In this study, we evaluate LLMs on three original coding tasks of non-English political science texts, and we provide a detailed description of a general workflow for using LLMs for text coding in political science research. Our use case offers a practical guide for researchers looking to incorporate LLMs into their research on text analysis. We find that, when provided with detailed label definitions and coding examples, an LLM can be as good as or even better than a human annotator while being much faster (up to hundreds of times), considerably cheaper (costing up to 60% less than human coding), and much easier to scale to large amounts of text. Overall, LLMs present a viable option for most text coding projects.
Encoding Sentence Position in Context-Aware Neural Machine Translation with Concatenation
Feb 13, 2023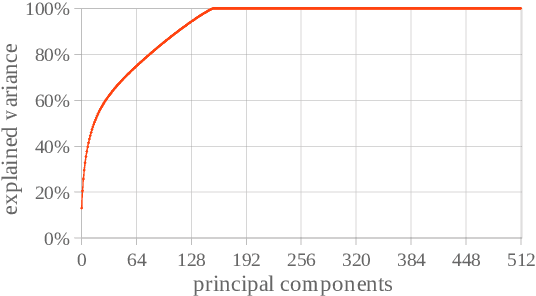
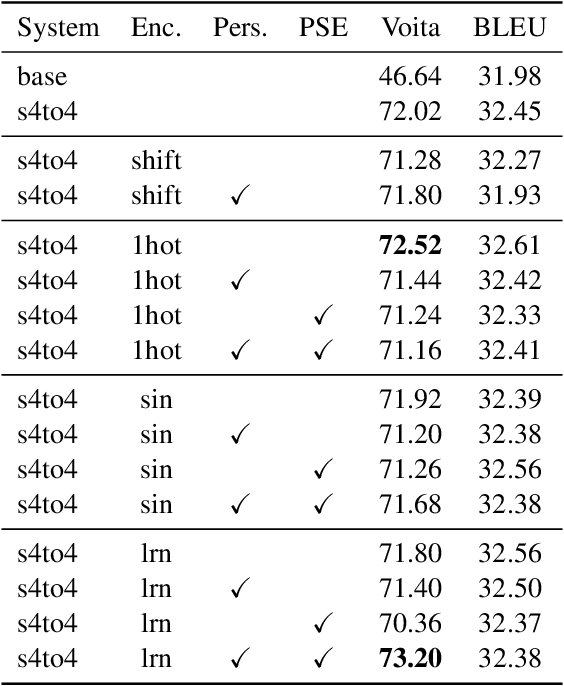
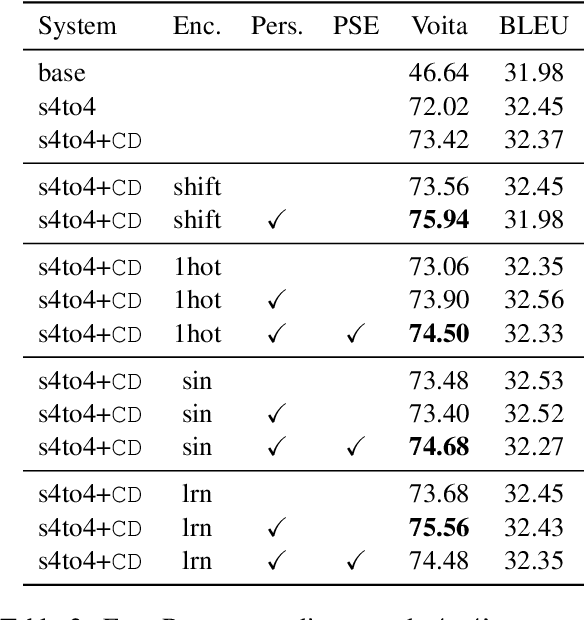
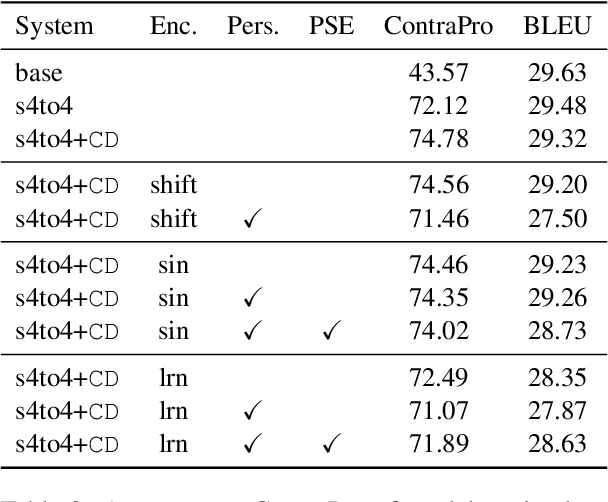
Context-aware translation can be achieved by processing a concatenation of consecutive sentences with the standard translation approach. This paper investigates the intuitive idea of adopting segment embeddings for this task to help the Transformer discern the position of each sentence in the concatenation sequence. We compare various segment embeddings and propose novel methods to encode sentence position into token representations, showing that they do not benefit the vanilla concatenation approach except in a specific setting.
Focused Concatenation for Context-Aware Neural Machine Translation
Oct 24, 2022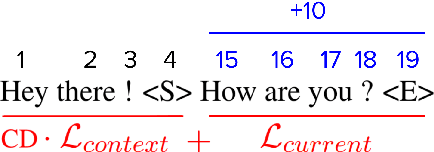
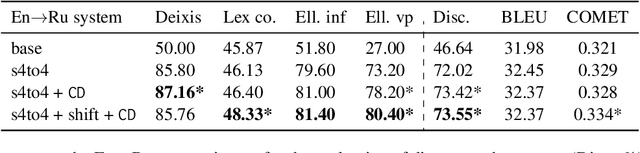
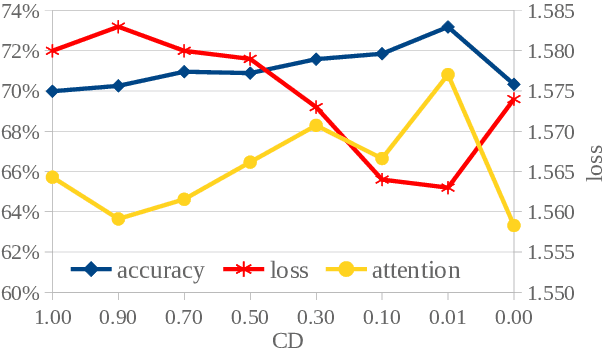
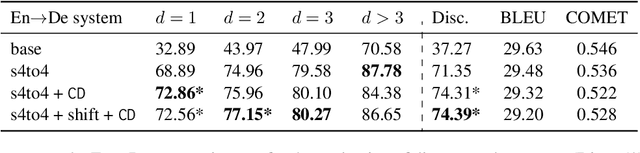
A straightforward approach to context-aware neural machine translation consists in feeding the standard encoder-decoder architecture with a window of consecutive sentences, formed by the current sentence and a number of sentences from its context concatenated to it. In this work, we propose an improved concatenation approach that encourages the model to focus on the translation of the current sentence, discounting the loss generated by target context. We also propose an additional improvement that strengthen the notion of sentence boundaries and of relative sentence distance, facilitating model compliance to the context-discounted objective. We evaluate our approach with both average-translation quality metrics and contrastive test sets for the translation of inter-sentential discourse phenomena, proving its superiority to the vanilla concatenation approach and other sophisticated context-aware systems.
Divide and Rule: Training Context-Aware Multi-Encoder Translation Models with Little Resources
Mar 31, 2021

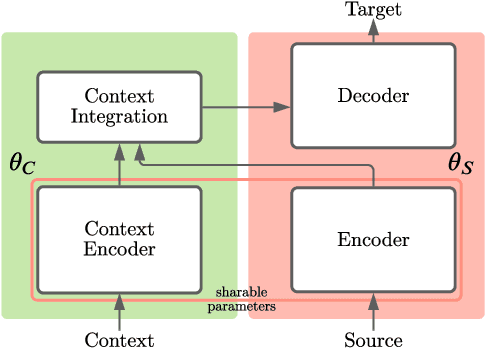
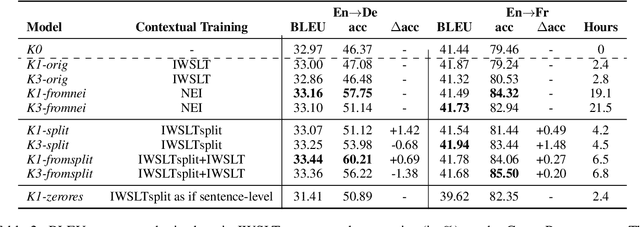
Multi-encoder models are a broad family of context-aware Neural Machine Translation (NMT) systems that aim to improve translation quality by encoding document-level contextual information alongside the current sentence. The context encoding is undertaken by contextual parameters, trained on document-level data. In this work, we show that training these parameters takes large amount of data, since the contextual training signal is sparse. We propose an efficient alternative, based on splitting sentence pairs, that allows to enrich the training signal of a set of parallel sentences by breaking intra-sentential syntactic links, and thus frequently pushing the model to search the context for disambiguating clues. We evaluate our approach with BLEU and contrastive test sets, showing that it allows multi-encoder models to achieve comparable performances to a setting where they are trained with $\times10$ document-level data. We also show that our approach is a viable option to context-aware NMT for language pairs with zero document-level parallel data.