 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADIT: A Dataset for Demographic Classification of Italian Twitter Users and a Comparison of Prediction Methods
Paper and Code
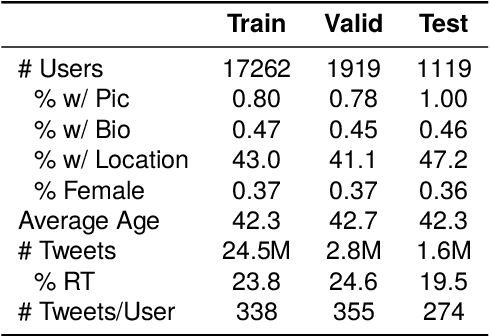
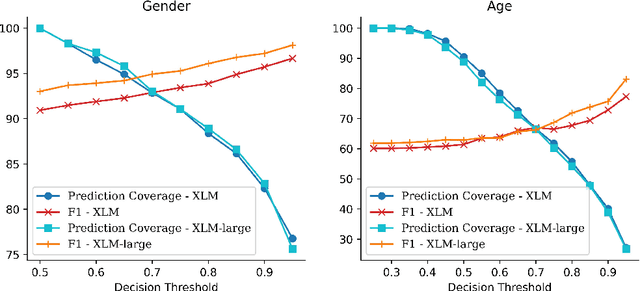
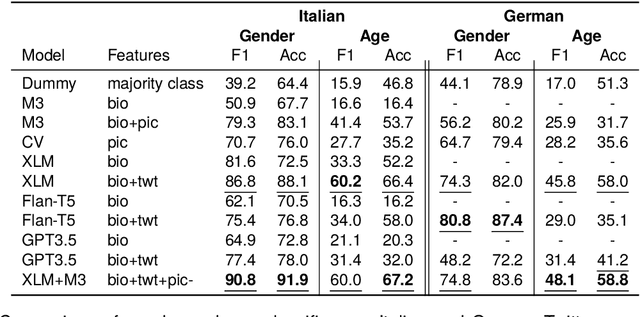
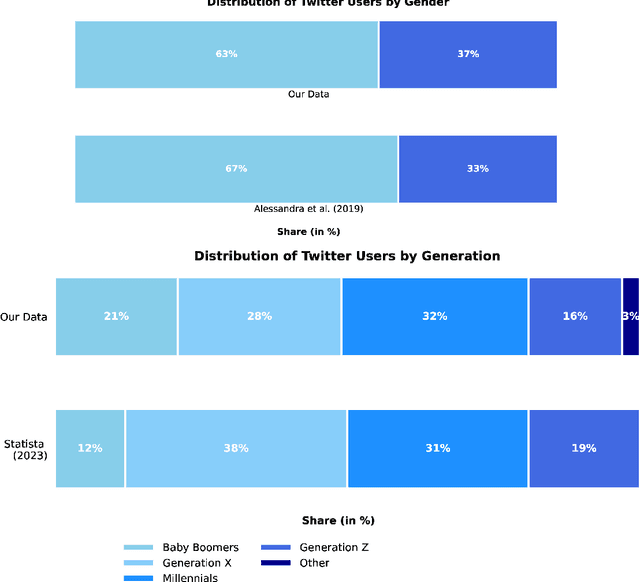
Social scientists increasingly use demographically stratified social media data to study the attitudes, beliefs, and behavior of the general public. To facilitate such analyses, we construct, validate, and release publicly the representative DADIT dataset of 30M tweets of 20k Italian Twitter users, along with their bios and profile pictures. We enrich the user data with high-quality labels for gender, age, and location. DADIT enables us to train and compare the performance of various state-of-the-art models for the prediction of the gender and age of social media users. In particular, we investigate if tweets contain valuable information for the task, since popular classifiers like M3 don't leverage them. Our best XLM-based classifier improves upon the commonly used competitor M3 by up to 53% F1. Especially for age prediction, classifiers profit from including tweets as features. We also confirm these findings on a German test set.