 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Rule: Training Context-Aware Multi-Encoder Translation Models with Little Resources
Paper and Code


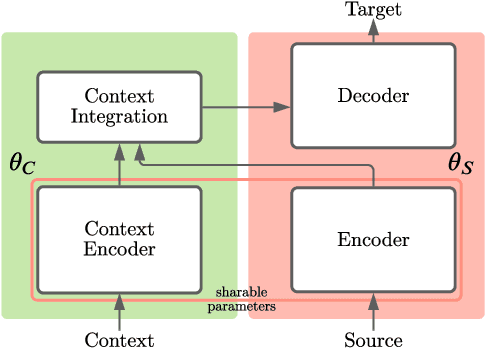
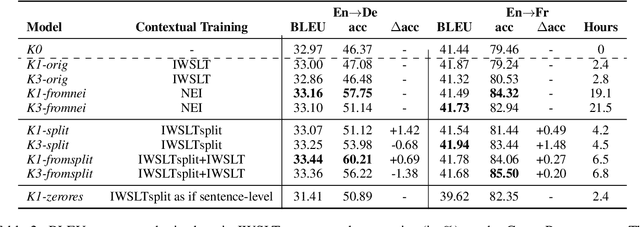
Multi-encoder models are a broad family of context-aware Neural Machine Translation (NMT) systems that aim to improve translation quality by encoding document-level contextual information alongside the current sentence. The context encoding is undertaken by contextual parameters, trained on document-level data. In this work, we show that training these parameters takes large amount of data, since the contextual training signal is sparse. We propose an efficient alternative, based on splitting sentence pairs, that allows to enrich the training signal of a set of parallel sentences by breaking intra-sentential syntactic links, and thus frequently pushing the model to search the context for disambiguating clues. We evaluate our approach with BLEU and contrastive test sets, showing that it allows multi-encoder models to achieve comparable performances to a setting where they are trained with $\times10$ document-level data. We also show that our approach is a viable option to context-aware NMT for language pairs with zero document-level parallel data.