 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Foundation Models and Crowdsourcing for Efficient, High-Quality Data Collection
Dec 16, 2024


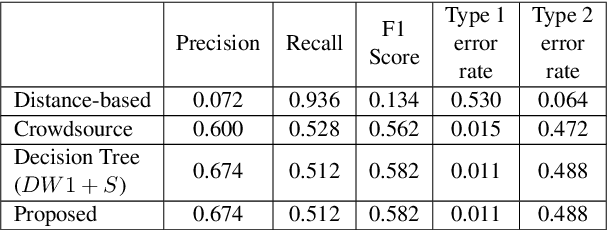
While crowdsourcing is an established solution for facilitating and scaling the collection of speech data, the involvement of non-experts necessitates protocols to ensure final data quality. To reduce the costs of these essential controls, this paper investigates the use of Speech Foundation Models (SFMs) to automate the validation process, examining for the first time the cost/quality trade-off in data acquisition. Experiments conducted on French, German, and Korean data demonstrate that SFM-based validation has the potential to reduce reliance on human validation, resulting in an estimated cost saving of over 40.0% without degrading final data quality. These findings open new opportunities for more efficient, cost-effective, and scalable speech data acquisition.
Speech-MASSIVE: A Multilingual Speech Dataset for SLU and Beyond
Aug 07, 2024



We present Speech-MASSIVE, a multilingual Spoken Language Understanding (SLU) dataset comprising the speech counterpart for a portion of the MASSIVE textual corpus. Speech-MASSIVE covers 12 languages from different families and inherits from MASSIVE the annotations for the intent prediction and slot-filling tasks. Our extension is prompted by the scarcity of massively multilingual SLU datasets and the growing need for versatile speech datasets to assess foundation models (LLMs, speech encoders) across languages and tasks. We provide a multimodal, multitask, multilingual dataset and report SLU baselines using both cascaded and end-to-end architectures in various training scenarios (zero-shot, few-shot, and full fine-tune). Furthermore, we demonstrate the suitability of Speech-MASSIVE for benchmarking other tasks such as speech transcription, language identification, and speech translation. The dataset, models, and code are publicly available at: https://github.com/hlt-mt/Speech-MASSIVE
mHuBERT-147: A Compact Multilingual HuBERT Model
Jun 11, 2024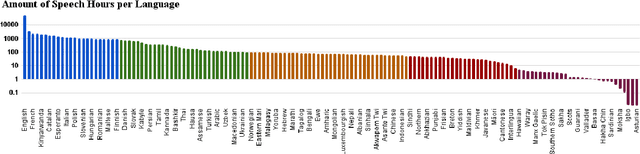
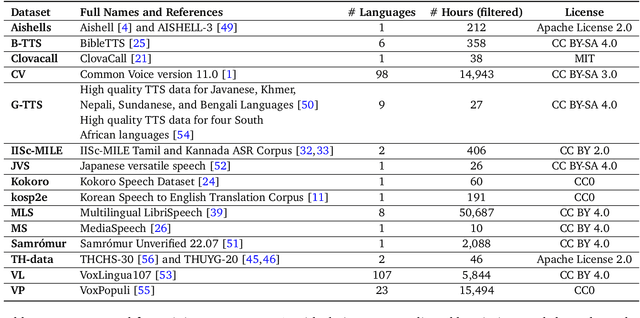
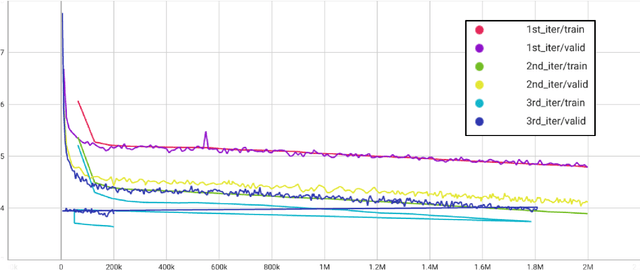
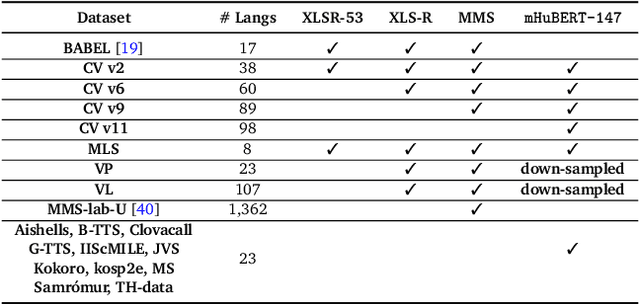
We present mHuBERT-147, the first general-purpose massively multilingual HuBERT speech representation model trained on 90K hours of clean, open-license data. To scale up the multi-iteration HuBERT approach, we use faiss-based clustering, achieving 5.2x faster label assignment than the original method. We also apply a new multilingual batching up-sampling strategy, leveraging both language and dataset diversity. After 3 training iterations, our compact 95M parameter mHuBERT-147 outperforms larger models trained on substantially more data. We rank second and first on the ML-SUPERB 10min and 1h leaderboards, with SOTA scores for 3 tasks. Across ASR/LID tasks, our model consistently surpasses XLS-R (300M params; 436K hours) and demonstrates strong competitiveness against the much larger MMS (1B params; 491K hours). Our findings indicate that mHuBERT-147 is a promising model for multilingual speech tasks, offering an unprecedented balance between high performance and parameter efficiency.
ELITR-Bench: A Meeting Assistant Benchmark for Long-Context Language Models
Mar 29, 2024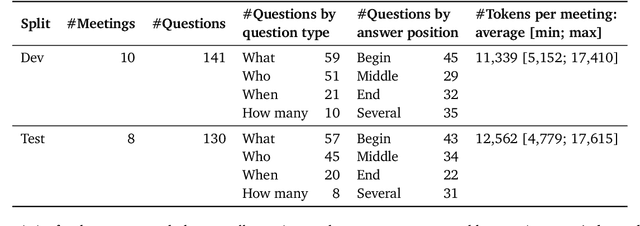
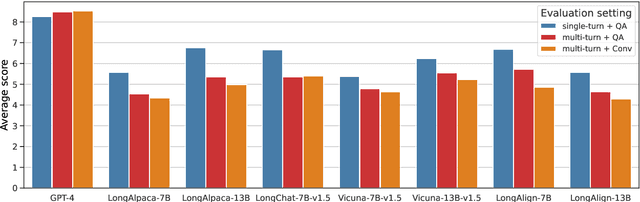
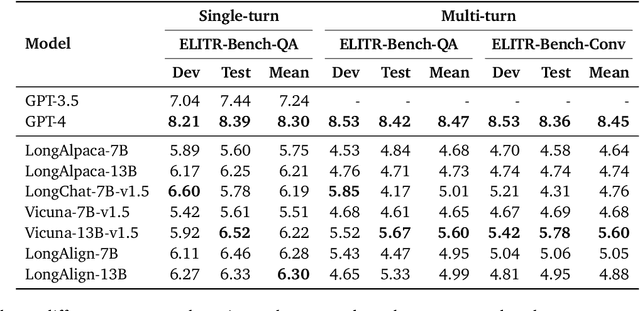
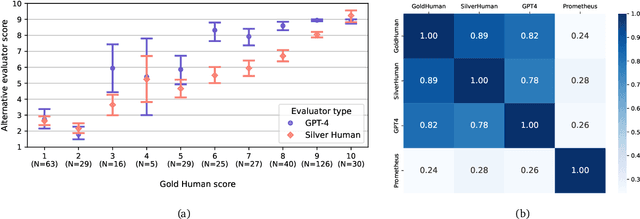
Research on Large Language Models (LLMs) has recently witnessed an increasing interest in extending models' context size to better capture dependencies within long documents. While benchmarks have been proposed to assess long-range abilities, existing efforts primarily considered generic tasks that are not necessarily aligned with real-world applications. In contrast, our work proposes a new benchmark for long-context LLMs focused on a practical meeting assistant scenario. In this scenario, the long contexts consist of transcripts obtained by automatic speech recognition, presenting unique challenges for LLMs due to the inherent noisiness and oral nature of such data. Our benchmark, named ELITR-Bench, augments the existing ELITR corpus' transcripts with 271 manually crafted questions and their ground-truth answers. Our experiments with recent long-context LLMs on ELITR-Bench highlight a gap between open-source and proprietary models, especially when questions are asked sequentially within a conversation. We also provide a thorough analysis of our GPT-4-based evaluation method, encompassing insights from a crowdsourcing study. Our findings suggest that while GPT-4's evaluation scores are correlated with human judges', its ability to differentiate among more than three score levels may be limited.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Encoding Sentence Position in Context-Aware Neural Machine Translation with Concatenation
Feb 13, 2023
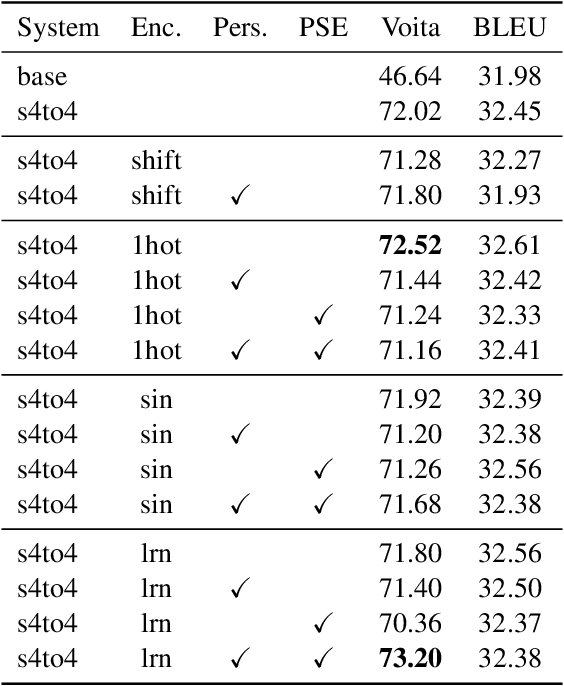
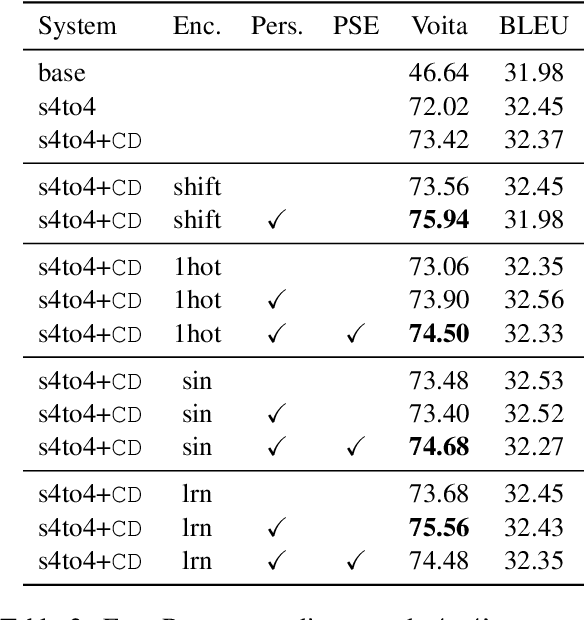
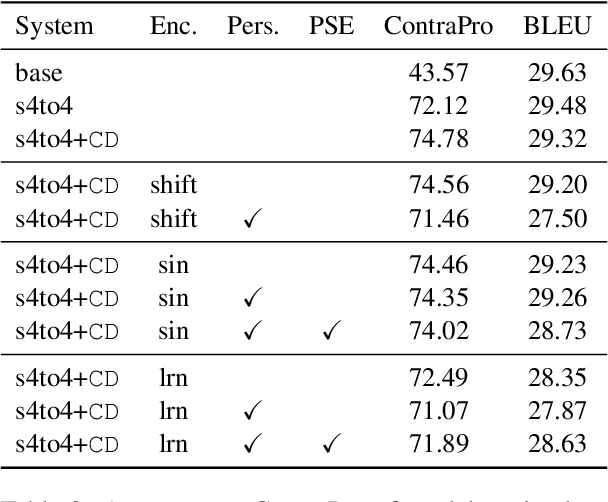
Context-aware translation can be achieved by processing a concatenation of consecutive sentences with the standard translation approach. This paper investigates the intuitive idea of adopting segment embeddings for this task to help the Transformer discern the position of each sentence in the concatenation sequence. We compare various segment embeddings and propose novel methods to encode sentence position into token representations, showing that they do not benefit the vanilla concatenation approach except in a specific setting.
Focused Concatenation for Context-Aware Neural Machine Translation
Oct 24, 2022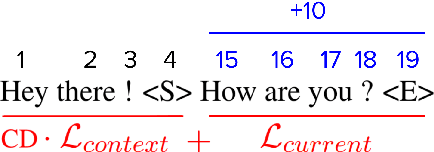
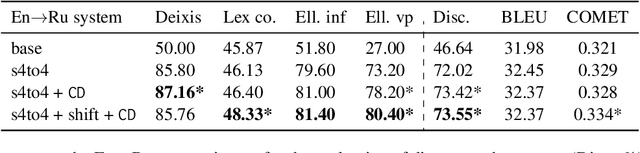
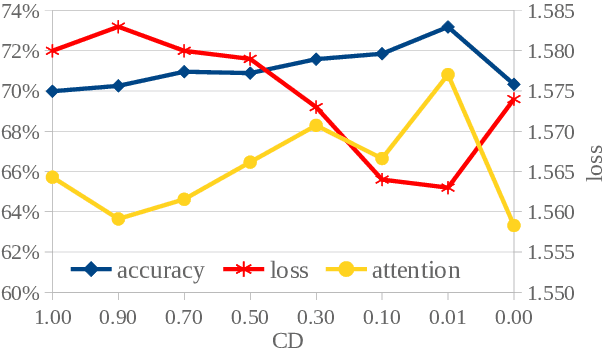
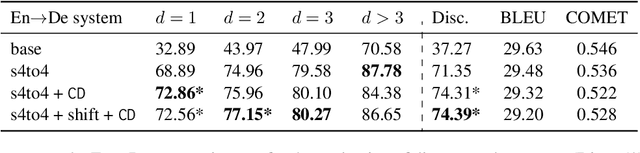
A straightforward approach to context-aware neural machine translation consists in feeding the standard encoder-decoder architecture with a window of consecutive sentences, formed by the current sentence and a number of sentences from its context concatenated to it. In this work, we propose an improved concatenation approach that encourages the model to focus on the translation of the current sentence, discounting the loss generated by target context. We also propose an additional improvement that strengthen the notion of sentence boundaries and of relative sentence distance, facilitating model compliance to the context-discounted objective. We evaluate our approach with both average-translation quality metrics and contrastive test sets for the translation of inter-sentential discourse phenomena, proving its superiority to the vanilla concatenation approach and other sophisticated context-aware systems.
ASR-Generated Text for Language Model Pre-training Applied to Speech Tasks
Jul 05, 2022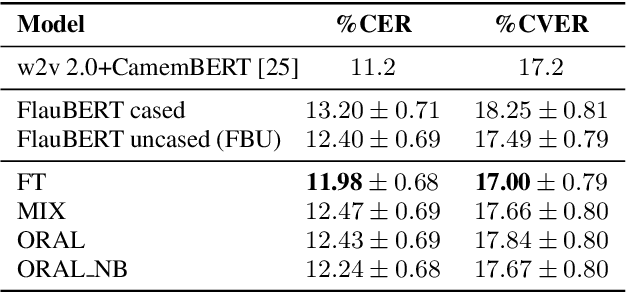
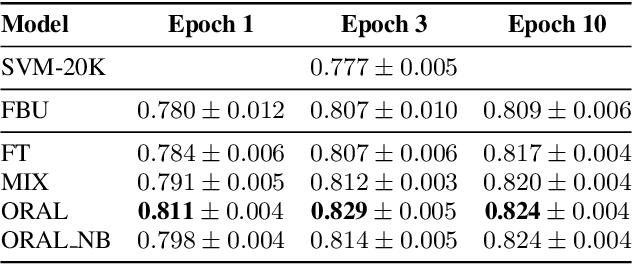
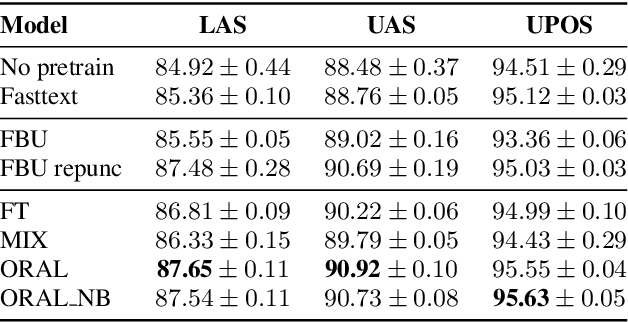
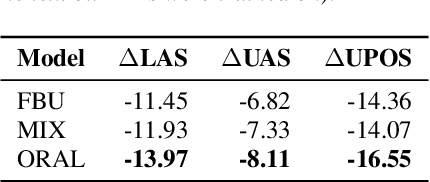
We aim at improving spoken language modeling (LM) using very large amount of automatically transcribed speech. We leverage the INA (French National Audiovisual Institute) collection and obtain 19GB of text after applying ASR on 350,000 hours of diverse TV shows. From this, spoken language models are trained either by fine-tuning an existing LM (FlauBERT) or through training a LM from scratch. New models (FlauBERT-Oral) are shared with the community and evaluated for 3 downstream tasks: spoken language understanding, classification of TV shows and speech syntactic parsing. Results show that FlauBERT-Oral can be beneficial compared to its initial FlauBERT version demonstrating that, despite its inherent noisy nature, ASR-generated text can be used to build spoken language models.
BERT, can HE predict contrastive focus? Predicting and controlling prominence in neural TTS using a language model
Jul 04, 2022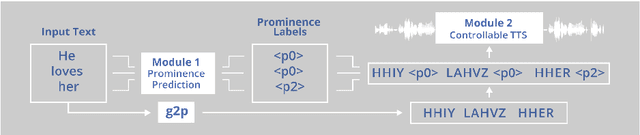

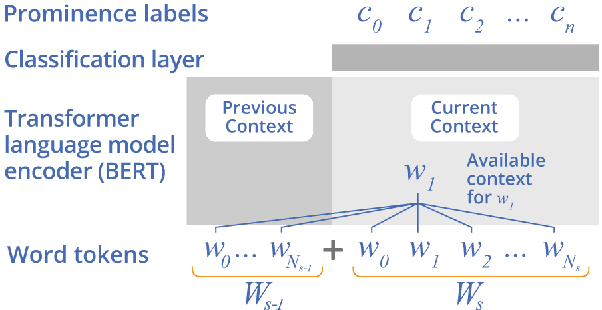
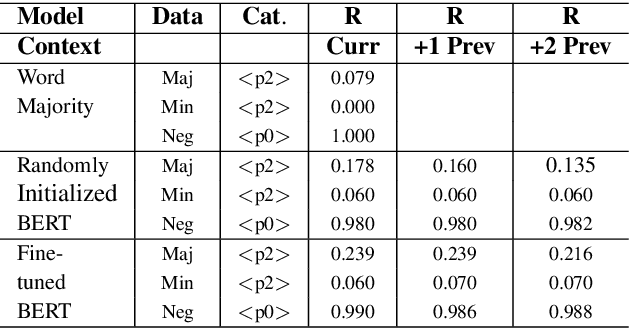
Several recent studies have tested the use of transformer language model representations to infer prosodic features for text-to-speech synthesis (TTS). While these studies have explored prosody in general, in this work, we look specifically at the prediction of contrastive focus on personal pronouns. This is a particularly challenging task as it often requires semantic, discursive and/or pragmatic knowledge to predict correctly. We collect a corpus of utterances containing contrastive focus and we evaluate the accuracy of a BERT model, finetuned to predict quantized acoustic prominence features, on these samples. We also investigate how past utterances can provide relevant information for this prediction. Furthermore, we evaluate the controllability of pronoun prominence in a TTS model conditioned on acoustic prominence features.
What Do Compressed Multilingual Machine Translation Models Forget?
May 22, 2022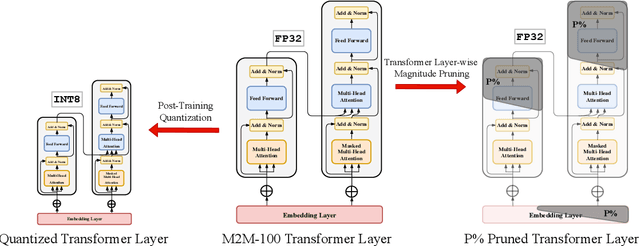

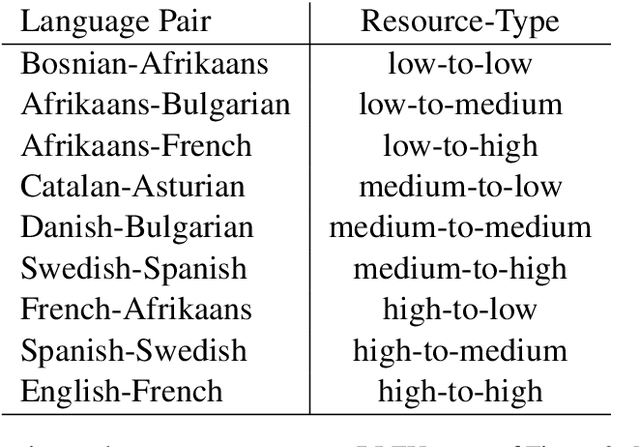
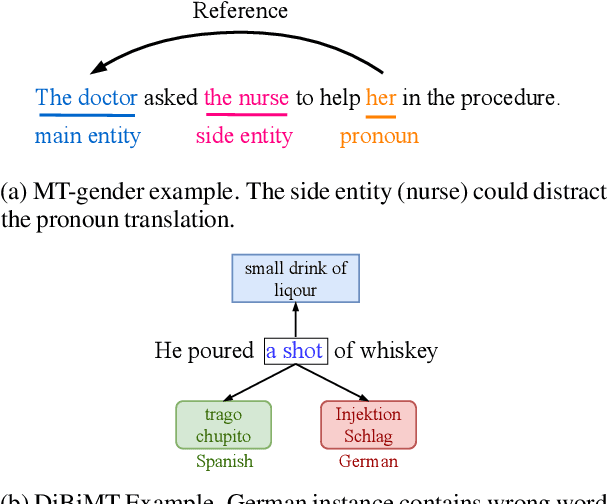
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.