Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Sentence Position in Context-Aware Neural Machine Translation with Concatenation
Paper and Code
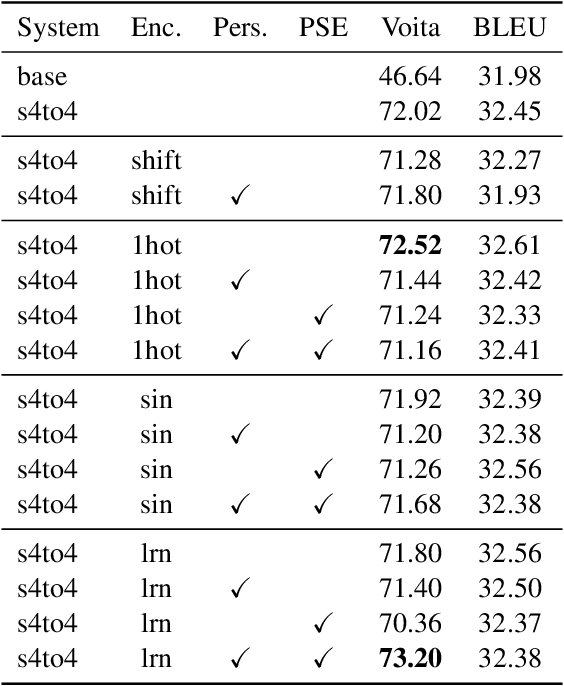
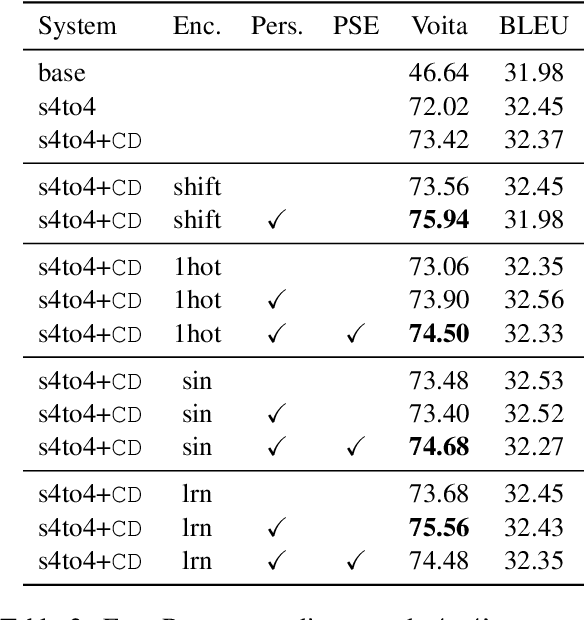
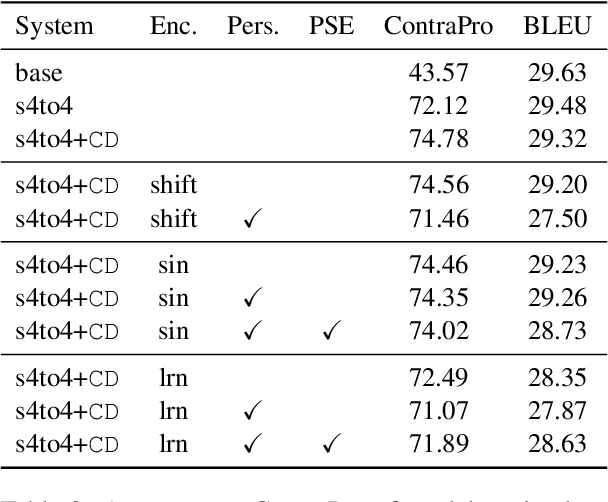
Context-aware translation can be achieved by processing a concatenation of consecutive sentences with the standard translation approach. This paper investigates the intuitive idea of adopting segment embeddings for this task to help the Transformer discern the position of each sentence in the concatenation sequence. We compare various segment embeddings and propose novel methods to encode sentence position into token representations, showing that they do not benefit the vanilla concatenation approach except in a specific setting.
View paper on