 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade-offs in Medical LLM Adaptation: An Empirical Study in French QA
Jun 17, 2026The development of large language models (LLMs) has led to an increased focus on their adaptation to specialized domains and languages, yet the effectiveness of domain adaptation strategies remains unclear. We present a study of medical domain adaptation using French medical question-answering (QA) as a case study. We compare continual pretraining (CPT), supervised fine-tuning (SFT), and their combination across three model families, multiple sizes, and three initialization types, explicitly disentangling adaptation effects from base model choice. We evaluate both multiple-choice (MCQA) and open-ended QA (OEQA) under greedy and constrained decoding using automatic metrics and LLM-as-a-Judge evaluation. For MCQA, CPT+SFT most often achieves the best scores, but gains over SFT are small and frequently not statistically significant, making SFT a strong and cost-effective default. For OEQA, CPT consistently improves overlap-based metrics, while SFT often degrades generation quality; instruction tuning and CPT+SFT are preferred by LLM-based evaluation. Cross-lingual experiments further show effective transfer from French adaptation to English benchmarks. Overall, we provide practical guidelines for selecting adaptation strategies under computational constraints.
Speaker Group Encoding in Self-supervised Speech Recognition Models
Jun 09, 2026We investigate what self-supervised speech recognition models (S3Ms) learn about speaker groups (SGs). We examine several states of S3Ms: pretrained, finetuned on speaker identification (SID), finetuned on automatic speech recognition (ASR), and ASR-finetuned using a fairness enhancing algorithm. We find that S3Ms encode information about several speaker group categories (SGCs), including their gender, age, dialect, ethnicity, and whether they are a native speaker. We find that finetuning for SID amplifies certain SGCs, namely those whose variance is more phonetic in nature, though it does not amplify other SGCs, namely those whose variance is more semantic in nature. On the other hand, finetuning for ASR discards phonetically variant speaker group information (SGI) but retains semantically variant SGI. We find that ASR algorithms designed for fairness improvement change to what extent SGI is encoded in S3Ms; however, this is primarily true for for phonetically variant SGCs, and less true for semantically variant SGCs. We discuss how SGI is encoded by each layer, and identify subdimensions of embeddings responsible for encoding different SGCs. Finally, we discuss how our findings could be beneficial in designing fairer ASR algorithms.
MedMeta: A Benchmark for LLMs in Synthesizing Meta-Analysis Conclusion from Medical Studies
May 10, 2026Large language models (LLMs) have saturated standard medical benchmarks that test factual recall, yet their ability to perform higher-order reasoning, such as synthesizing evidence from multiple sources, remains critically under-explored. To address this gap, we introduce MedMeta, the first benchmark designed to evaluate an LLM's ability to generate conclusions from medical meta-analyses using only the abstracts of cited studies. MedMeta comprises 81 meta-analyses from PubMed (2018--2025) and evaluates models using two distinct workflows: a Retrieval-Augmented Generation (Golden-RAG) setting with ground-truth abstracts, and a Parametric-only approach relying on internal knowledge. Our evaluation framework is validated by a well-structured analysis showing our LLM-as-a-judge protocol strongly aligns with human expert ratings, as evidenced by high Pearson's r correlation (0.81) and Bland-Altman analysis revealing negligible systematic bias, establishing it as a reliable proxy for scalable evaluation. Our findings underscore the critical importance of information grounding: the Golden-RAG workflow consistently and significantly outperforms the Parametric-only approach across models. In contrast, the benefits of domain-specific fine-tuning are marginal and largely neutralized when external material is provided. Furthermore, stress tests show that all models, regardless of architecture, fail to identify and reject negated evidence, highlighting a critical vulnerability in current RAG systems. Notably, even under ideal RAG conditions, current LLMs achieve only slightly above-average performance (~2.7/5.0). MedMeta provides a challenging new benchmark for evidence synthesis and demonstrates that for clinical applications, developing robust RAG systems is a more promising direction than model specialization alone.
Who Judges the Judge? Evaluating LLM-as-a-Judge for French Medical open-ended QA
Mar 04, 2026Automatic evaluation of medical open-ended question answering (OEQA) remains challenging due to the need for expert annotations. We evaluate whether large language models (LLMs) can act as judges of semantic equivalence in French medical OEQA, comparing closed-access, general-purpose, and biomedical domain-adapted models. Our results show that LLM-based judgments are strongly influenced by the model that generated the answer, with agreement varying substantially across generators. Domain-adapted and large general-purpose models achieve the highest alignment with expert annotations. We further show that lightweight adaptation of a compact model using supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) substantially improves performance and reduces generator sensitivity, even with limited data. Overall, our findings highlight the need for generator-aware evaluation and suggest that carefully adapted small models can support scalable evaluation in low-resource medical settings.
CareMedEval dataset: Evaluating Critical Appraisal and Reasoning in the Biomedical Field
Nov 05, 2025



Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal.
Crossing the Species Divide: Transfer Learning from Speech to Animal Sounds
Sep 04, 2025Self-supervised speech models have demonstrated impressive performance in speech processing, but their effectiveness on non-speech data remains underexplored. We study the transfer learning capabilities of such models on bioacoustic detection and classification tasks. We show that models such as HuBERT, WavLM, and XEUS can generate rich latent representations of animal sounds across taxa. We analyze the models properties with linear probing on time-averaged representations. We then extend the approach to account for the effect of time-wise information with other downstream architectures. Finally, we study the implication of frequency range and noise on performance. Notably, our results are competitive with fine-tuned bioacoustic pre-trained models and show the impact of noise-robust pre-training setups. These findings highlight the potential of speech-based self-supervised learning as an efficient framework for advancing bioacoustic research.
Increasing faithfulness in human-human dialog summarization with Spoken Language Understanding tasks
Sep 16, 2024



Dialogue summarization aims to provide a concise and coherent summary of conversations between multiple speakers. While recent advancements in language models have enhanced this process, summarizing dialogues accurately and faithfully remains challenging due to the need to understand speaker interactions and capture relevant information. Indeed, abstractive models used for dialog summarization may generate summaries that contain inconsistencies. We suggest using the semantic information proposed for performing Spoken Language Understanding (SLU) in human-machine dialogue systems for goal-oriented human-human dialogues to obtain a more semantically faithful summary regarding the task. This study introduces three key contributions: First, we propose an exploration of how incorporating task-related information can enhance the summarization process, leading to more semantically accurate summaries. Then, we introduce a new evaluation criterion based on task semantics. Finally, we propose a new dataset version with increased annotated data standardized for research on task-oriented dialogue summarization. The study evaluates these methods using the DECODA corpus, a collection of French spoken dialogues from a call center. Results show that integrating models with task-related information improves summary accuracy, even with varying word error rates.
"Do you follow me?": A Survey of Recent Approaches in Dialogue State Tracking
Jul 29, 2022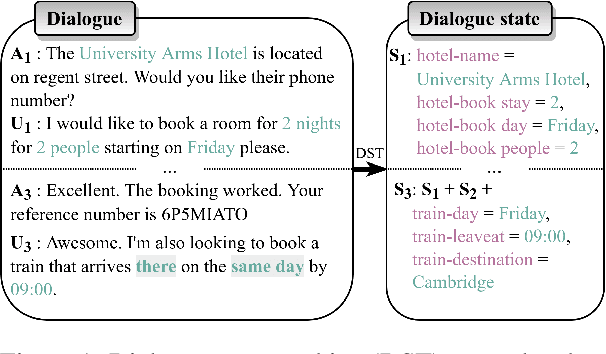
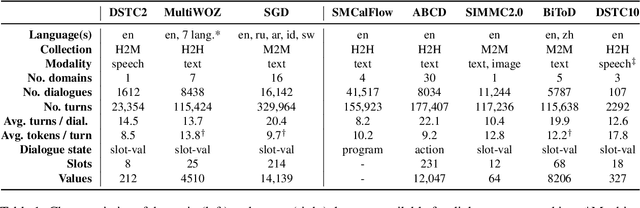
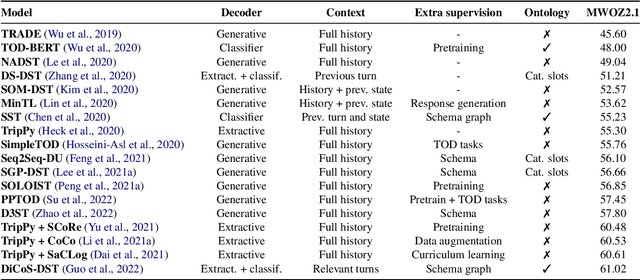

While communicating with a user, a task-oriented dialogue system has to track the user's needs at each turn according to the conversation history. This process called dialogue state tracking (DST) is crucial because it directly informs the downstream dialogue policy. DST has received a lot of interest in recent years with the text-to-text paradigm emerging as the favored approach. In this review paper, we first present the task and its associated datasets. Then, considering a large number of recent publications, we identify highlights and advances of research in 2021-2022. Although neural approaches have enabled significant progress, we argue that some critical aspects of dialogue systems such as generalizability are still underexplored. To motivate future studies, we propose several research avenues.
ASR-Generated Text for Language Model Pre-training Applied to Speech Tasks
Jul 05, 2022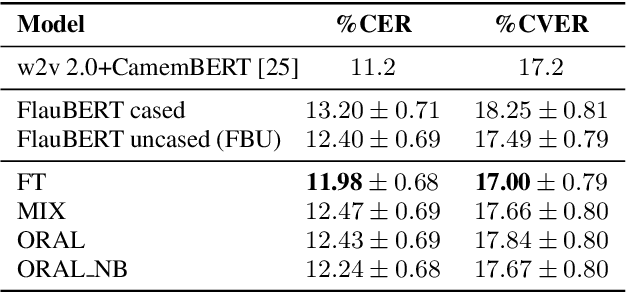
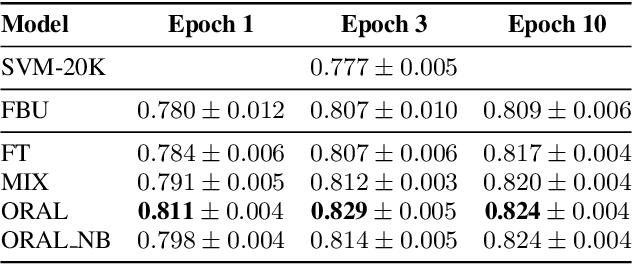
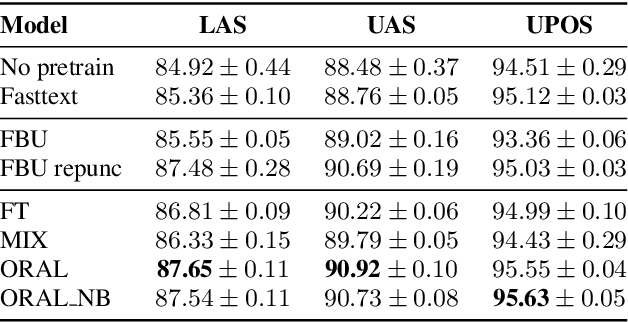
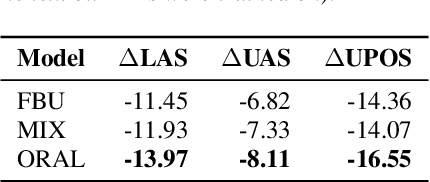
We aim at improving spoken language modeling (LM) using very large amount of automatically transcribed speech. We leverage the INA (French National Audiovisual Institute) collection and obtain 19GB of text after applying ASR on 350,000 hours of diverse TV shows. From this, spoken language models are trained either by fine-tuning an existing LM (FlauBERT) or through training a LM from scratch. New models (FlauBERT-Oral) are shared with the community and evaluated for 3 downstream tasks: spoken language understanding, classification of TV shows and speech syntactic parsing. Results show that FlauBERT-Oral can be beneficial compared to its initial FlauBERT version demonstrating that, despite its inherent noisy nature, ASR-generated text can be used to build spoken language models.
Zero-Shot and Few-Shot Classification of Biomedical Articles in Context of the COVID-19 Pandemic
Jan 11, 2022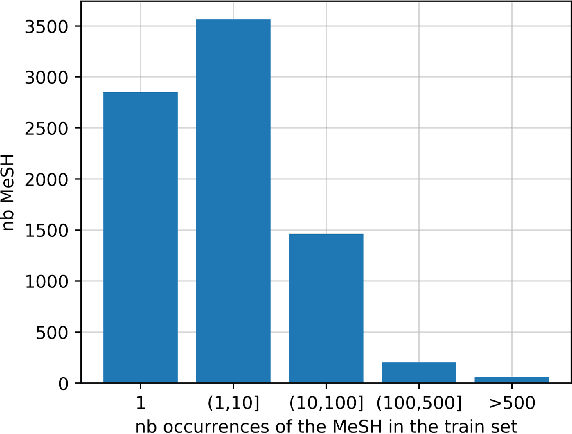

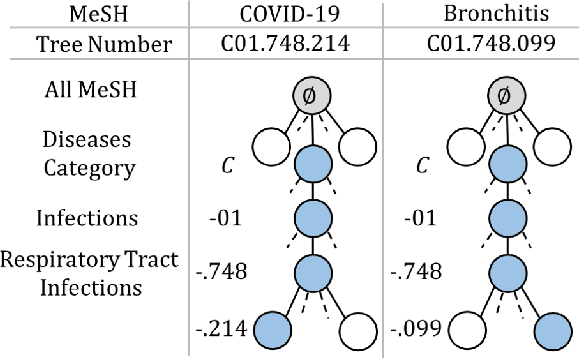
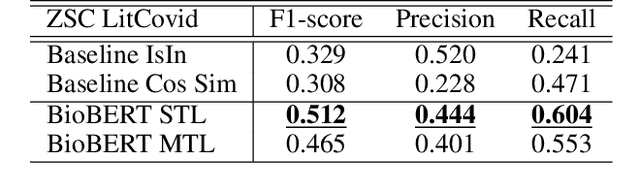
MeSH (Medical Subject Headings) is a large thesaurus created by the National Library of Medicine and used for fine-grained indexing of publications in the biomedical domain. In the context of the COVID-19 pandemic, MeSH descriptors have emerged in relation to articles published on the corresponding topic. Zero-shot classification is an adequate response for timely labeling of the stream of papers with MeSH categories. In this work, we hypothesise that rich semantic information available in MeSH has potential to improve BioBERT representations and make them more suitable for zero-shot/few-shot tasks. We frame the problem as determining if MeSH term definitions, concatenated with paper abstracts are valid instances or not, and leverage multi-task learning to induce the MeSH hierarchy in the representations thanks to a seq2seq task. Results establish a baseline on the MedLine and LitCovid datasets, and probing shows that the resulting representations convey the hierarchical relations present in MeSH.