 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing faithfulness in human-human dialog summarization with Spoken Language Understanding tasks
Sep 16, 2024



Dialogue summarization aims to provide a concise and coherent summary of conversations between multiple speakers. While recent advancements in language models have enhanced this process, summarizing dialogues accurately and faithfully remains challenging due to the need to understand speaker interactions and capture relevant information. Indeed, abstractive models used for dialog summarization may generate summaries that contain inconsistencies. We suggest using the semantic information proposed for performing Spoken Language Understanding (SLU) in human-machine dialogue systems for goal-oriented human-human dialogues to obtain a more semantically faithful summary regarding the task. This study introduces three key contributions: First, we propose an exploration of how incorporating task-related information can enhance the summarization process, leading to more semantically accurate summaries. Then, we introduce a new evaluation criterion based on task semantics. Finally, we propose a new dataset version with increased annotated data standardized for research on task-oriented dialogue summarization. The study evaluates these methods using the DECODA corpus, a collection of French spoken dialogues from a call center. Results show that integrating models with task-related information improves summary accuracy, even with varying word error rates.
Investigating the Effect of Relative Positional Embeddings on AMR-to-Text Generation with Structural Adapters
Feb 12, 2023



Text generation from Abstract Meaning Representation (AMR) has substantially benefited from the popularized Pretrained Language Models (PLMs). Myriad approaches have linearized the input graph as a sequence of tokens to fit the PLM tokenization requirements. Nevertheless, this transformation jeopardizes the structural integrity of the graph and is therefore detrimental to its resulting representation. To overcome this issue, Ribeiro et al. have recently proposed StructAdapt, a structure-aware adapter which injects the input graph connectivity within PLMs using Graph Neural Networks (GNNs). In this paper, we investigate the influence of Relative Position Embeddings (RPE) on AMR-to-Text, and, in parallel, we examine the robustness of StructAdapt. Through ablation studies, graph attack and link prediction, we reveal that RPE might be partially encoding input graphs. We suggest further research regarding the role of RPE will provide valuable insights for Graph-to-Text generation.
FrameNet automatic analysis : a study on a French corpus of encyclopedic texts
Dec 19, 2018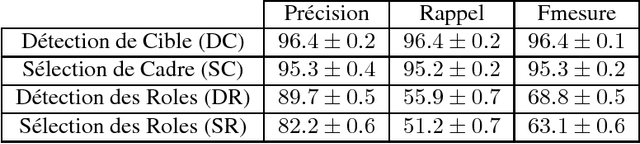



This article presents an automatic frame analysis system evaluated on a corpus of French encyclopedic history texts annotated according to the FrameNet formalism. The chosen approach relies on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The purpose of this study is to analyze the task complexity from several dimensions. Hence we provide detailed evaluations from a feature selection point of view and from the data point of view.
* in French
Semantic Frame Parsing for Information Extraction : the CALOR corpus
Dec 19, 2018


This paper presents a publicly available corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The main difference in our approach compared to previous works on semantic parsing with FrameNet is that we are not interested here in full text parsing but rather on partial parsing. The goal is to select from the FrameNet resources the minimal set of frames that are going to be useful for the applicative framework targeted, in our case Information Extraction from encyclopedic documents. Such an approach leverages the manual annotation of larger corpora than those obtained through full text parsing and therefore opens the door to alternative methods for Frame parsing than those used so far on the FrameNet 1.5 benchmark corpus. The approaches compared in this study rely on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The models compared are CRFs and multitasks bi-LSTMs.
Supervised Term Weighting Metrics for Sentiment Analysis in Short Text
Oct 10, 2016
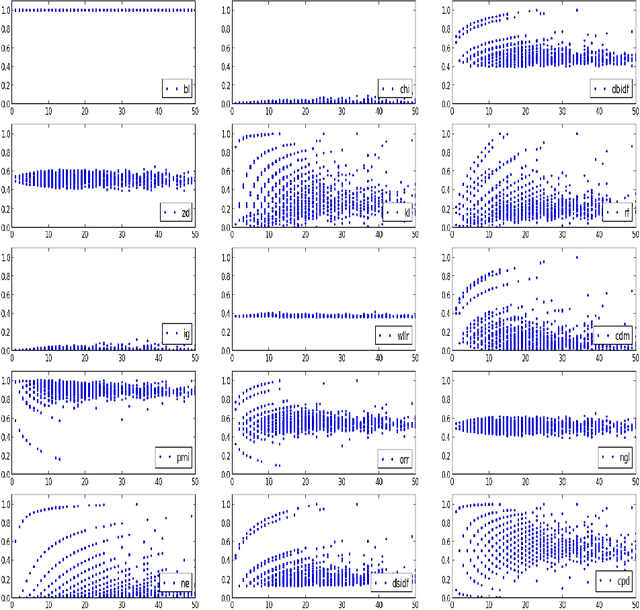
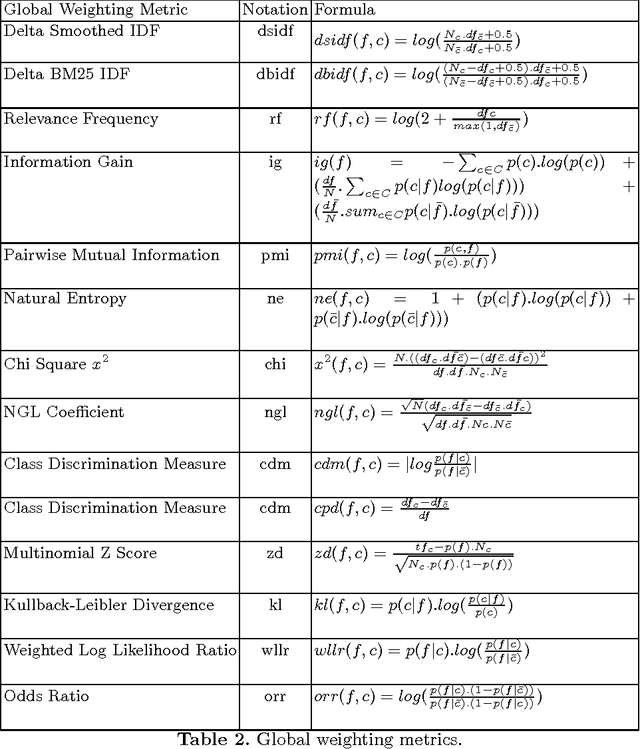
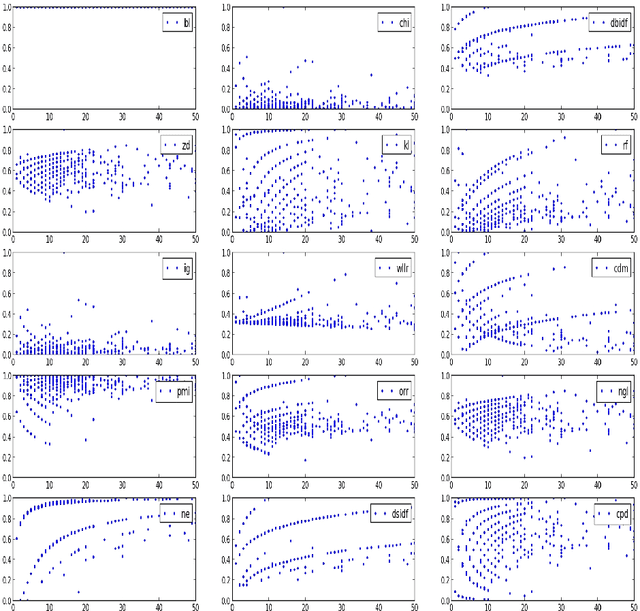
Term weighting metrics assign weights to terms in order to discriminate the important terms from the less crucial ones. Due to this characteristic, these metrics have attracted growing attention in text classification and recently in sentiment analysis. Using the weights given by such metrics could lead to more accurate document representation which may improve the performance of the classification. While previous studies have focused on proposing or comparing different weighting metrics at two-classes document level sentiment analysis, this study propose to analyse the results given by each metric in order to find out the characteristics of good and bad weighting metrics. Therefore we present an empirical study of fifteen global supervised weighting metrics with four local weighting metrics adopted from information retrieval, we also give an analysis to understand the behavior of each metric by observing and analysing how each metric distributes the terms and deduce some characteristics which may distinguish the good and bad metrics. The evaluation has been done using Support Vector Machine on three different datasets: Twitter, restaurant and laptop reviews.
Sentiment Analysis in Scholarly Book Reviews
Mar 04, 2016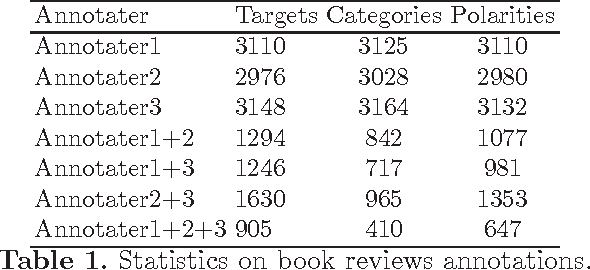
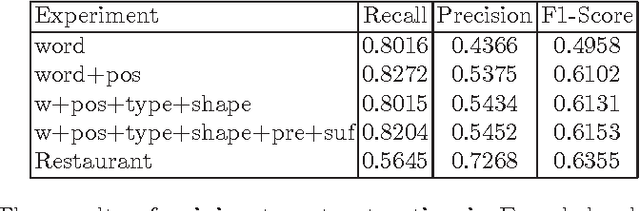
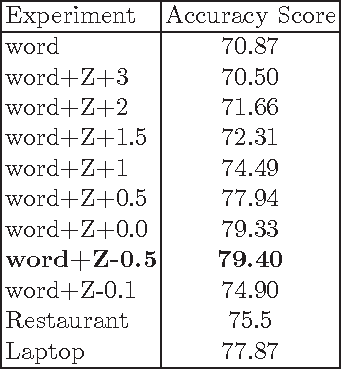
So far different studies have tackled the sentiment analysis in several domains such as restaurant and movie reviews. But, this problem has not been studied in scholarly book reviews which is different in terms of review style and size. In this paper, we propose to combine different features in order to be presented to a supervised classifiers which extract the opinion target expressions and detect their polarities in scholarly book reviews. We construct a labeled corpus for training and evaluating our methods in French book reviews. We also evaluate them on English restaurant reviews in order to measure their robustness across the domains and languages. The evaluation shows that our methods are enough robust for English restaurant reviews and French book reviews.