 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex QA and language models hybrid architectures, Survey
Feb 17, 2023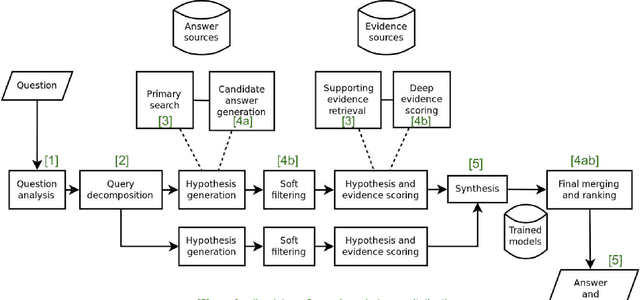
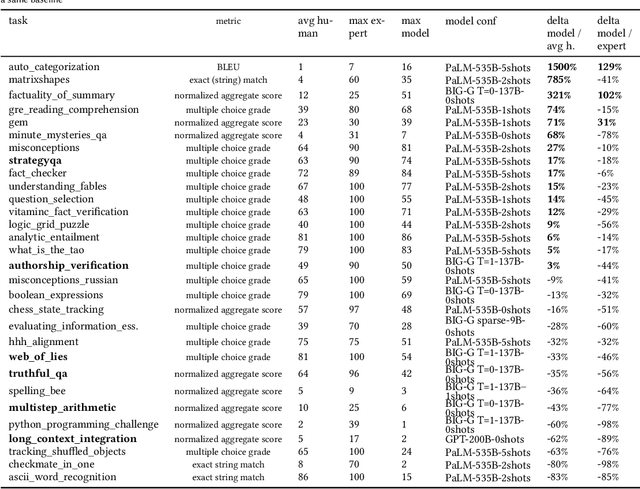
This paper provides a survey of the state of the art of hybrid language models architectures and strategies for "complex" question-answering (QA, CQA, CPS). Very large language models are good at leveraging public data on standard problems but once you want to tackle more specific complex questions or problems you may need specific architecture, knowledge, skills, tasks, methods, sensitive data, performance, human approval and versatile feedback... This survey extends findings from the robust community edited research papers BIG, BLOOM and HELM which open source, benchmark and analyze limits and challenges of large language models in terms of tasks complexity and strict evaluation on accuracy (e.g. fairness, robustness, toxicity, ...). It identifies the key elements used with Large Language Models (LLM) to solve complex questions or problems. Recent projects like ChatGPT and GALACTICA have allowed non-specialists to grasp the great potential as well as the equally strong limitations of language models in complex QA. Hybridizing these models with different components could allow to overcome these different limits and go much further. We discuss some challenges associated with complex QA, including domain adaptation, decomposition and efficient multi-step QA, long form QA, non-factoid QA, safety and multi-sensitivity data protection, multimodal search, hallucinations, QA explainability and truthfulness, time dimension. Therefore we review current solutions and promising strategies, using elements such as hybrid LLM architectures, human-in-the-loop reinforcement learning, prompting adaptation, neuro-symbolic and structured knowledge grounding, program synthesis, and others. We analyze existing solutions and provide an overview of the current research and trends in the area of complex QA.
GRAPHYP: A Scientific Knowledge Graph with Manifold Subnetworks of Communities. Detection of Scholarly Disputes in Adversarial Information Routes
May 03, 2022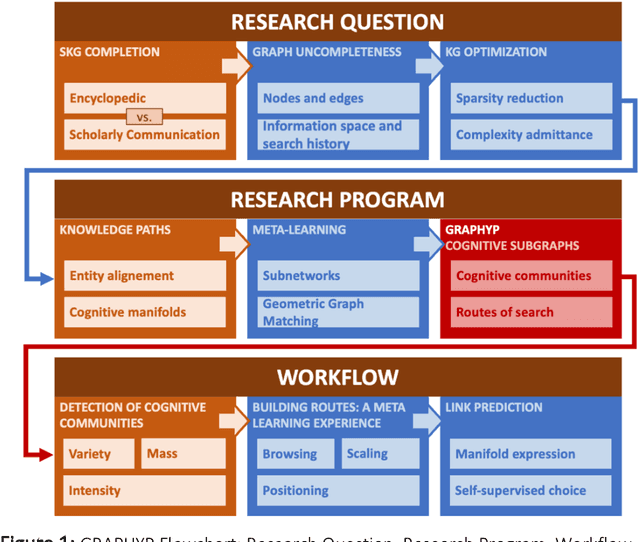


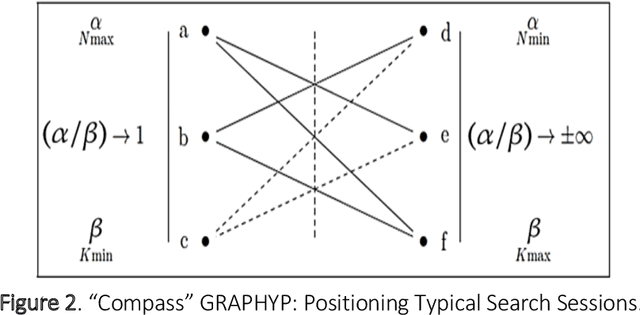
The cognitive manifold of published content is currently expanding in all areas of science. However, Scientific Knowledge Graphs (SKGs) only provide poor pictures of the adversarial directions and scientific controversies that feed the production of knowledge. In this Article, we tackle the understanding of the design of the information space of a cognitive representation of research activities, and of related bottlenecks that affect search interfaces, in the mapping of structured objects into graphs. We propose, with SKG GRAPHYP, a novel graph designed geometric architecture which optimizes both the detection of the knowledge manifold of "cognitive communities", and the representation of alternative paths to adversarial answers to a research question, for instance in the context of academic disputes. With a methodology for designing "Manifold Subnetworks of Cognitive Communities", GRAPHYP provides a classification of distinct search paths in a research field. Users are detected from the variety of their search practices and classified in "Cognitive communities" from the analysis of the search history of their logs of scientific documentation. The manifold of practices is expressed from metrics of differentiated uses by triplets of nodes shaped into symmetrical graph subnetworks, with the following three parameters: Mass, Intensity, and Variety.
A Preliminary Study for Building an Arabic Corpus of Pair Questions-Texts from the Web: AQA-Webcorp
Sep 27, 2017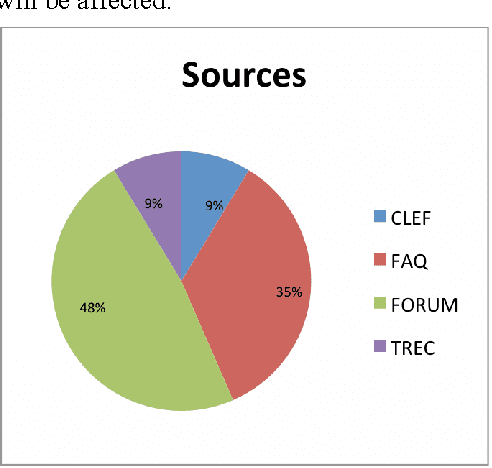
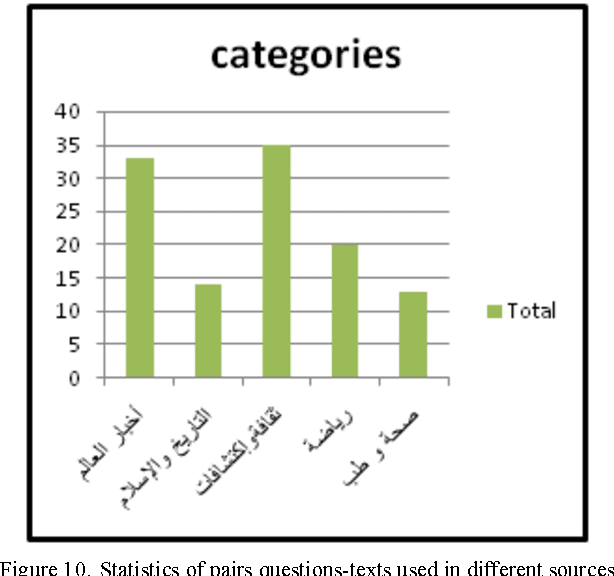
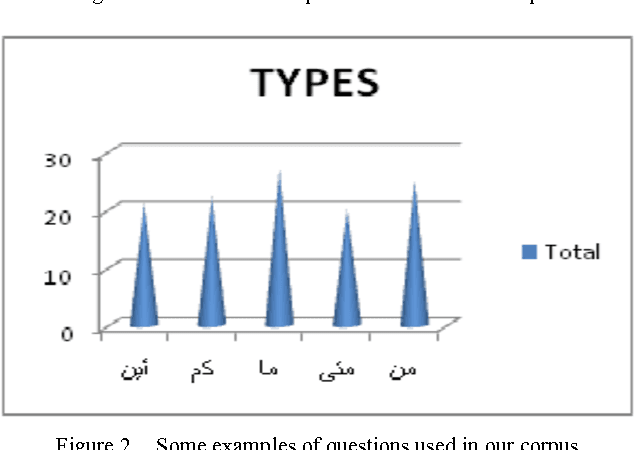
With the development of electronic media and the heterogeneity of Arabic data on the Web, the idea of building a clean corpus for certain applications of natural language processing, including machine translation, information retrieval, question answer, become more and more pressing. In this manuscript, we seek to create and develop our own corpus of pair's questions-texts. This constitution then will provide a better base for our experimentation step. Thus, we try to model this constitution by a method for Arabic insofar as it recovers texts from the web that could prove to be answers to our factual questions. To do this, we had to develop a java script that can extract from a given query a list of html pages. Then clean these pages to the extent of having a data base of texts and a corpus of pair's question-texts. In addition, we give preliminary results of our proposal method. Some investigations for the construction of Arabic corpus are also presented in this document.
Supervised Term Weighting Metrics for Sentiment Analysis in Short Text
Oct 10, 2016
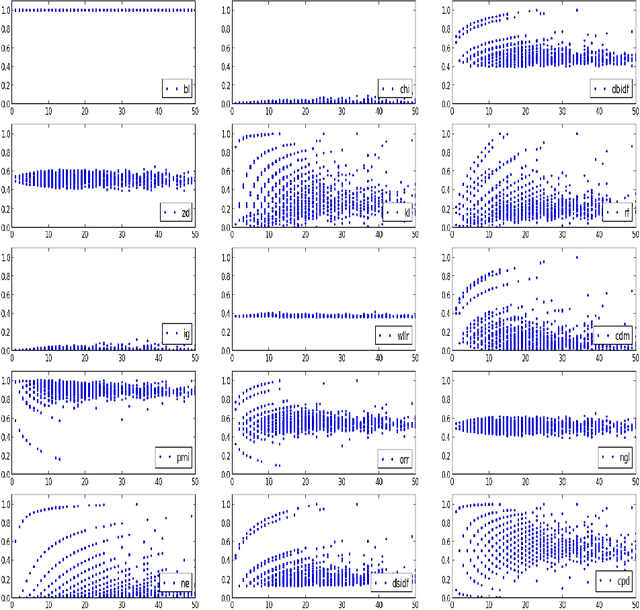
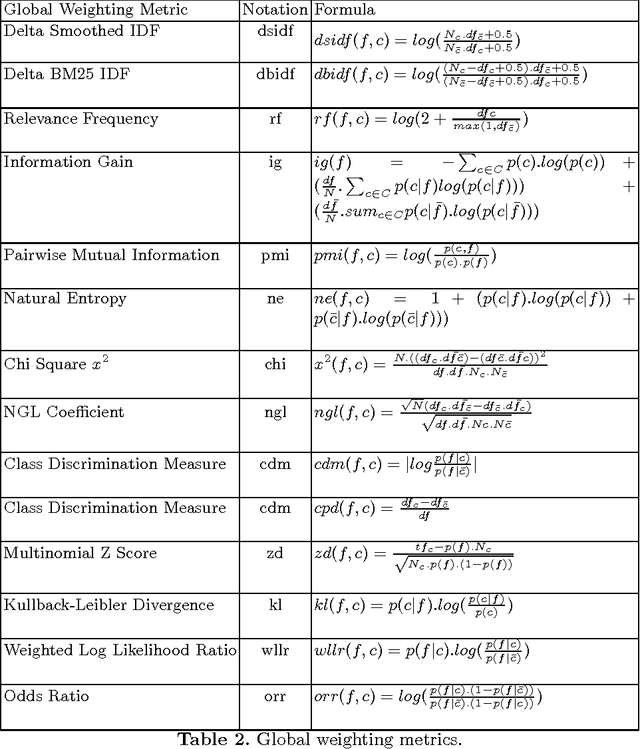
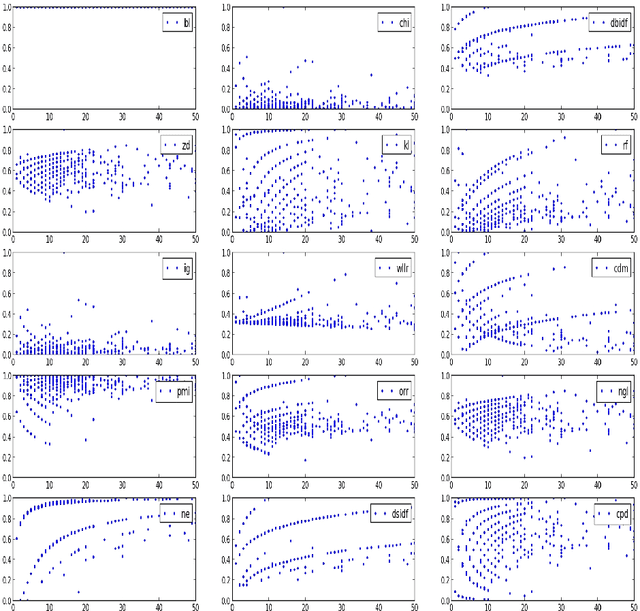
Term weighting metrics assign weights to terms in order to discriminate the important terms from the less crucial ones. Due to this characteristic, these metrics have attracted growing attention in text classification and recently in sentiment analysis. Using the weights given by such metrics could lead to more accurate document representation which may improve the performance of the classification. While previous studies have focused on proposing or comparing different weighting metrics at two-classes document level sentiment analysis, this study propose to analyse the results given by each metric in order to find out the characteristics of good and bad weighting metrics. Therefore we present an empirical study of fifteen global supervised weighting metrics with four local weighting metrics adopted from information retrieval, we also give an analysis to understand the behavior of each metric by observing and analysing how each metric distributes the terms and deduce some characteristics which may distinguish the good and bad metrics. The evaluation has been done using Support Vector Machine on three different datasets: Twitter, restaurant and laptop reviews.
Sentiment Analysis in Scholarly Book Reviews
Mar 04, 2016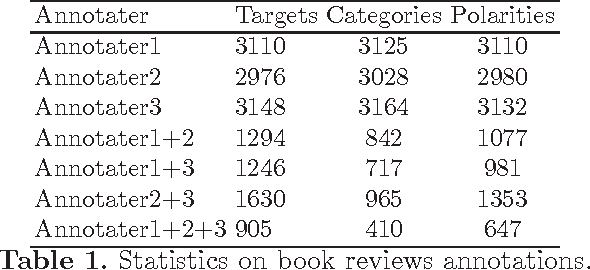
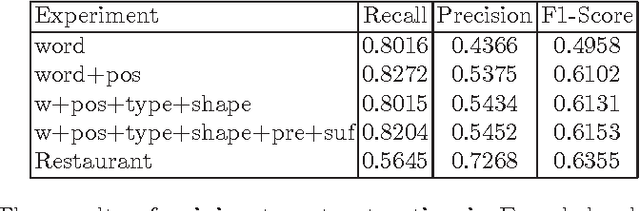
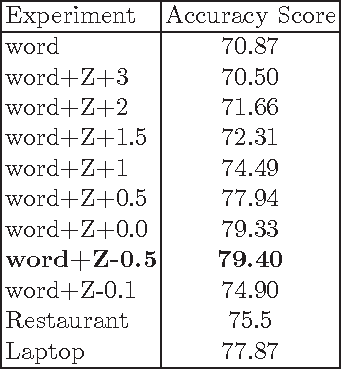
So far different studies have tackled the sentiment analysis in several domains such as restaurant and movie reviews. But, this problem has not been studied in scholarly book reviews which is different in terms of review style and size. In this paper, we propose to combine different features in order to be presented to a supervised classifiers which extract the opinion target expressions and detect their polarities in scholarly book reviews. We construct a labeled corpus for training and evaluating our methods in French book reviews. We also evaluate them on English restaurant reviews in order to measure their robustness across the domains and languages. The evaluation shows that our methods are enough robust for English restaurant reviews and French book reviews.
Automatic Summarization System coupled with a Question-Answering System (QAAS)
May 18, 2009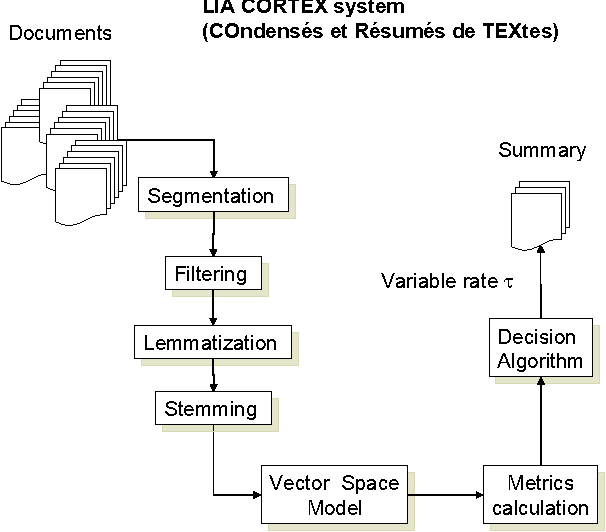
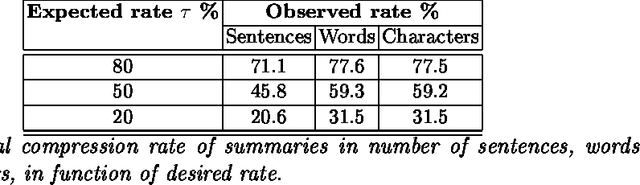
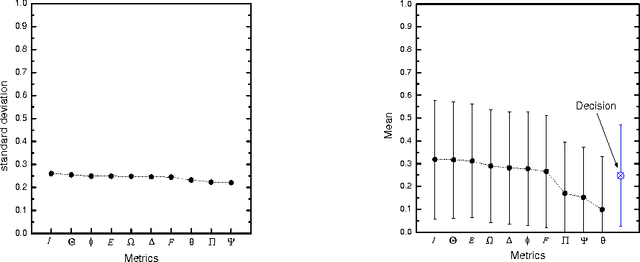

To select the most relevant sentences of a document, it uses an optimal decision algorithm that combines several metrics. The metrics processes, weighting and extract pertinence sentences by statistical and informational algorithms. This technique might improve a Question-Answering system, whose function is to provide an exact answer to a question in natural language. In this paper, we present the results obtained by coupling the Cortex summarizer with a Question-Answering system (QAAS). Two configurations have been evaluated. In the first one, a low compression level is selected and the summarization system is only used as a noise filter. In the second configuration, the system actually functions as a summarizer, with a very high level of compression. Our results on French corpus demonstrate that the coupling of Automatic Summarization system with a Question-Answering system is promising. Then the system has been adapted to generate a customized summary depending on the specific question. Tests on a french multi-document corpus have been realized, and the personalized QAAS system obtains the best performances.