 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntweetive Text Summarization
Jan 16, 2020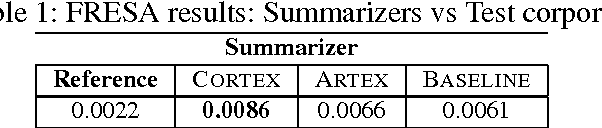


The amount of user generated contents from various social medias allows analyst to handle a wide view of conversations on several topics related to their business. Nevertheless keeping up-to-date with this amount of information is not humanly feasible. Automatic Summarization then provides an interesting mean to digest the dynamics and the mass volume of contents. In this paper, we address the issue of tweets summarization which remains scarcely explored. We propose to automatically generated summaries of Micro-Blogs conversations dealing with public figures E-Reputation. These summaries are generated using key-word queries or sample tweet and offer a focused view of the whole Micro-Blog network. Since state-of-the-art is lacking on this point we conduct and evaluate our experiments over the multilingual CLEF RepLab Topic-Detection dataset according to an experimental evaluation process.
* 8 pages, 4 tables
Predicting Personalized Academic and Career Roads: First Steps Toward a Multi-Uses Recommender System
Jan 03, 2020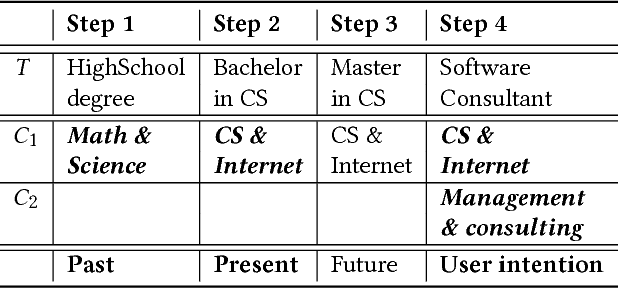
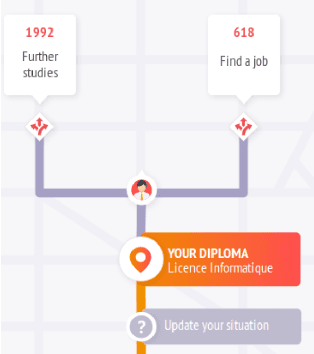

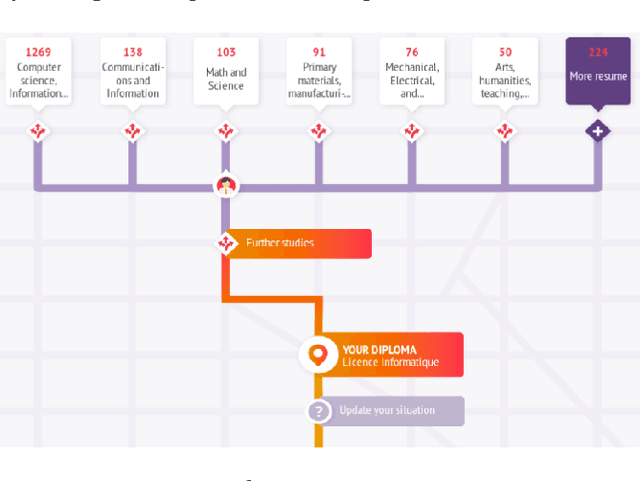
Nobody knows what one's do in the future and everyone will have had a different answer to the question : how do you see yourself in five years after your current job/diploma? In this paper we introduce concepts, large categories of fields of studies or job domains in order to represent the vision of the future of the user's trajectory. Then, we show how they can influence the prediction when proposing him a set of next steps to take.
* 4 pages, 3 figures, 4 tables
Un duel probabiliste pour départager deux présidents (LIA @ DEFT'2005)
Mar 11, 2019
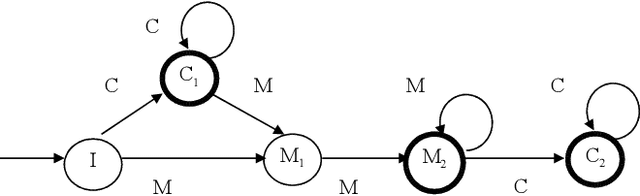
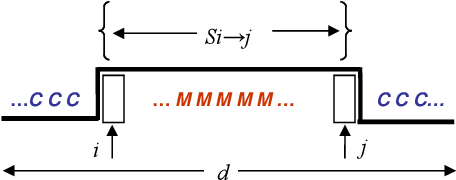
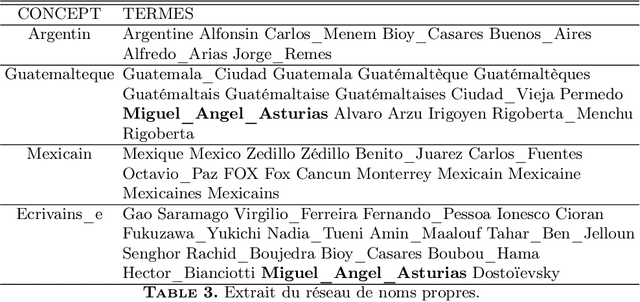
We present a set of probabilistic models applied to binary classification as defined in the DEFT'05 challenge. The challenge consisted a mixture of two differents problems in Natural Language Processing : identification of author (a sequence of Fran\c{c}ois Mitterrand's sentences might have been inserted into a speech of Jacques Chirac) and thematic break detection (the subjects addressed by the two authors are supposed to be different). Markov chains, Bayes models and an adaptative process have been used to identify the paternity of these sequences. A probabilistic model of the internal coherence of speeches which has been employed to identify thematic breaks. Adding this model has shown to improve the quality results. A comparison with different approaches demostrates the superiority of a strategy that combines learning, coherence and adaptation. Applied to the DEFT'05 data test the results in terms of precision (0.890), recall (0.955) and Fscore (0.925) measure are very promising.
* 27 figures, 1 table (in French)
Algorithmes de classification et d'optimisation: participation du LIA/ADOC á DEFT'14
Feb 21, 2017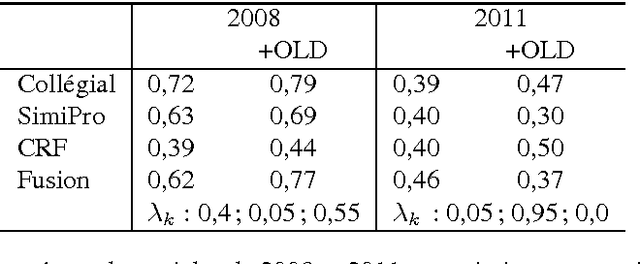

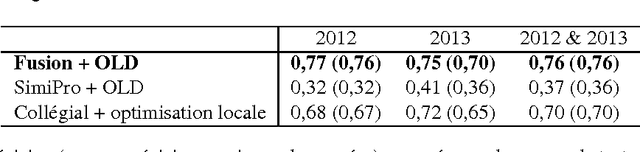
This year, the DEFT campaign (D\'efi Fouilles de Textes) incorporates a task which aims at identifying the session in which articles of previous TALN conferences were presented. We describe the three statistical systems developed at LIA/ADOC for this task. A fusion of these systems enables us to obtain interesting results (micro-precision score of 0.76 measured on the test corpus)
Systèmes du LIA à DEFT'13
Feb 21, 2017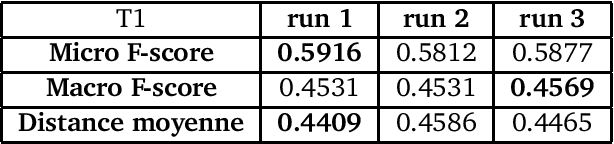


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)
Optimisation using Natural Language Processing: Personalized Tour Recommendation for Museums
Jan 06, 2015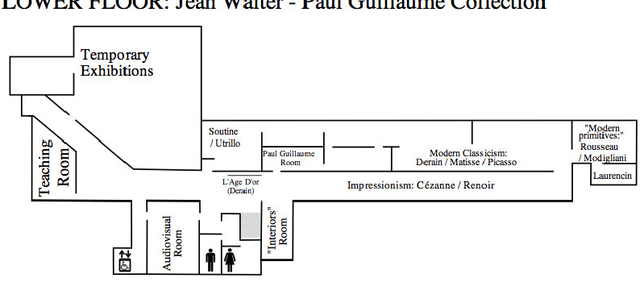
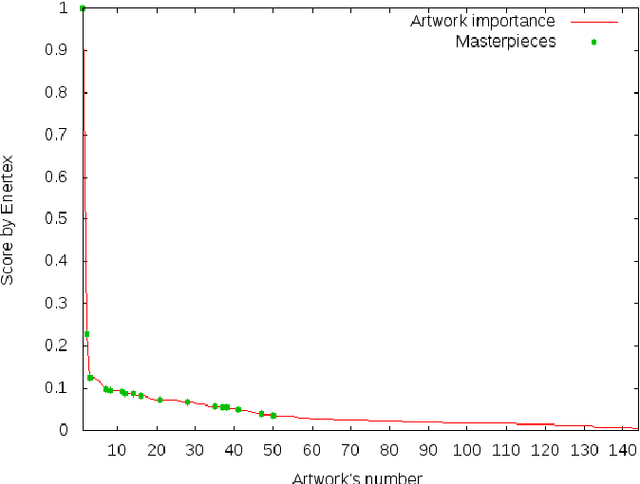
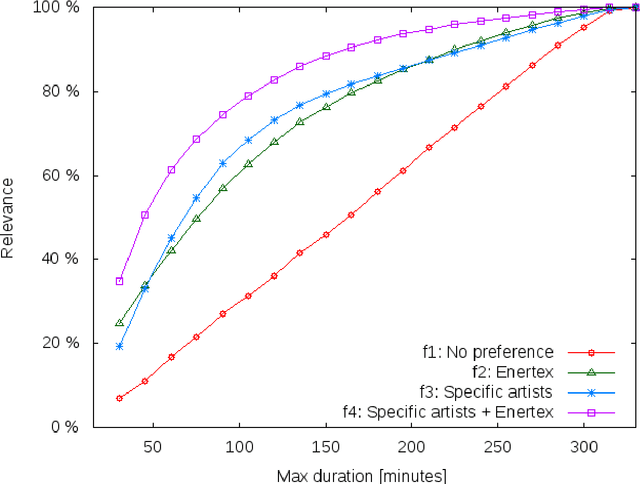
This paper proposes a new method to provide personalized tour recommendation for museum visits. It combines an optimization of preference criteria of visitors with an automatic extraction of artwork importance from museum information based on Natural Language Processing using textual energy. This project includes researchers from computer and social sciences. Some results are obtained with numerical experiments. They show that our model clearly improves the satisfaction of the visitor who follows the proposed tour. This work foreshadows some interesting outcomes and applications about on-demand personalized visit of museums in a very near future.
Automatic Summarization System coupled with a Question-Answering System (QAAS)
May 18, 2009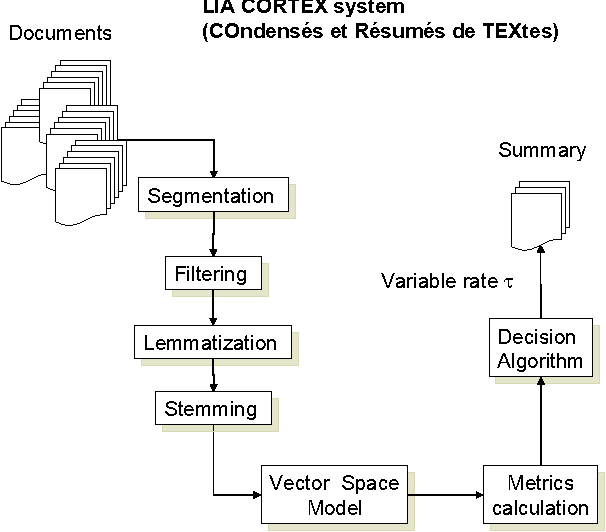
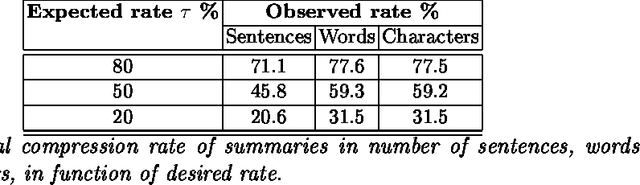
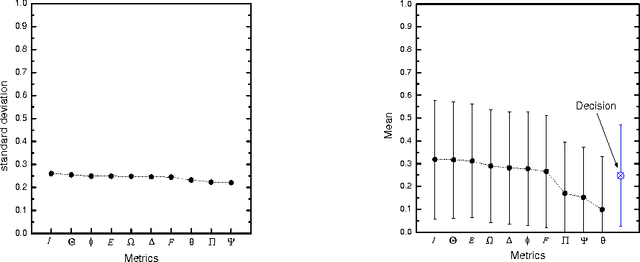

To select the most relevant sentences of a document, it uses an optimal decision algorithm that combines several metrics. The metrics processes, weighting and extract pertinence sentences by statistical and informational algorithms. This technique might improve a Question-Answering system, whose function is to provide an exact answer to a question in natural language. In this paper, we present the results obtained by coupling the Cortex summarizer with a Question-Answering system (QAAS). Two configurations have been evaluated. In the first one, a low compression level is selected and the summarization system is only used as a noise filter. In the second configuration, the system actually functions as a summarizer, with a very high level of compression. Our results on French corpus demonstrate that the coupling of Automatic Summarization system with a Question-Answering system is promising. Then the system has been adapted to generate a customized summary depending on the specific question. Tests on a french multi-document corpus have been realized, and the personalized QAAS system obtains the best performances.