 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCareMedEval dataset: Evaluating Critical Appraisal and Reasoning in the Biomedical Field
Nov 05, 2025



Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal.
Statistical Deficiency for Task Inclusion Estimation
Mar 07, 2025Tasks are central in machine learning, as they are the most natural objects to assess the capabilities of current models. The trend is to build general models able to address any task. Even though transfer learning and multitask learning try to leverage the underlying task space, no well-founded tools are available to study its structure. This study proposes a theoretically grounded setup to define the notion of task and to compute the {\bf inclusion} between two tasks from a statistical deficiency point of view. We propose a tractable proxy as information sufficiency to estimate the degree of inclusion between tasks, show its soundness on synthetic data, and use it to reconstruct empirically the classic NLP pipeline.
On the Robustness of Temporal Factual Knowledge in Language Models
Feb 03, 2025This paper explores the temporal robustness of language models (LMs) in handling factual knowledge. While LMs can often complete simple factual statements, their ability to manage temporal facts (those valid only within specific timeframes) remains uncertain. We design a controlled experiment to test the robustness of temporal factual knowledge inside LMs, which we use to evaluate several pretrained and instruction-tuned models using prompts on popular Wikidata facts, assessing their performance across different temporal granularities (Day, Month, and Year). Our findings indicate that even very large state-of-the-art models, such as Llama-3.1-70B, vastly lack robust knowledge of temporal facts. In addition, they are incapable of generalizing their knowledge from one granularity to another. These results highlight the inherent limitations of using LMs as temporal knowledge bases. The source code and data to reproduce our experiments will be released.
A linguistically-motivated evaluation methodology for unraveling model's abilities in reading comprehension tasks
Jan 29, 2025We introduce an evaluation methodology for reading comprehension tasks based on the intuition that certain examples, by the virtue of their linguistic complexity, consistently yield lower scores regardless of model size or architecture. We capitalize on semantic frame annotation for characterizing this complexity, and study seven complexity factors that may account for model's difficulty. We first deploy this methodology on a carefully annotated French reading comprehension benchmark showing that two of those complexity factors are indeed good predictors of models' failure, while others are less so. We further deploy our methodology on a well studied English benchmark by using Chat-GPT as a proxy for semantic annotation. Our study reveals that fine-grained linguisticallymotivated automatic evaluation of a reading comprehension task is not only possible, but helps understand models' abilities to handle specific linguistic characteristics of input examples. It also shows that current state-of-the-art models fail with some for those characteristics which suggests that adequately handling them requires more than merely increasing model size.
Part-Of-Speech Sensitivity of Routers in Mixture of Experts Models
Dec 22, 2024This study investigates the behavior of model-integrated routers in Mixture of Experts (MoE) models, focusing on how tokens are routed based on their linguistic features, specifically Part-of-Speech (POS) tags. The goal is to explore across different MoE architectures whether experts specialize in processing tokens with similar linguistic traits. By analyzing token trajectories across experts and layers, we aim to uncover how MoE models handle linguistic information. Findings from six popular MoE models reveal expert specialization for specific POS categories, with routing paths showing high predictive accuracy for POS, highlighting the value of routing paths in characterizing tokens.
WikiFactDiff: A Large, Realistic, and Temporally Adaptable Dataset for Atomic Factual Knowledge Update in Causal Language Models
Mar 21, 2024The factuality of large language model (LLMs) tends to decay over time since events posterior to their training are "unknown" to them. One way to keep models up-to-date could be factual update: the task of inserting, replacing, or removing certain simple (atomic) facts within the model. To study this task, we present WikiFactDiff, a dataset that describes the evolution of factual knowledge between two dates as a collection of simple facts divided into three categories: new, obsolete, and static. We describe several update scenarios arising from various combinations of these three types of basic update. The facts are represented by subject-relation-object triples; indeed, WikiFactDiff was constructed by comparing the state of the Wikidata knowledge base at 4 January 2021 and 27 February 2023. Those fact are accompanied by verbalization templates and cloze tests that enable running update algorithms and their evaluation metrics. Contrary to other datasets, such as zsRE and CounterFact, WikiFactDiff constitutes a realistic update setting that involves various update scenarios, including replacements, archival, and new entity insertions. We also present an evaluation of existing update algorithms on WikiFactDiff.
Predicting Links on Wikipedia with Anchor Text Information
May 25, 2021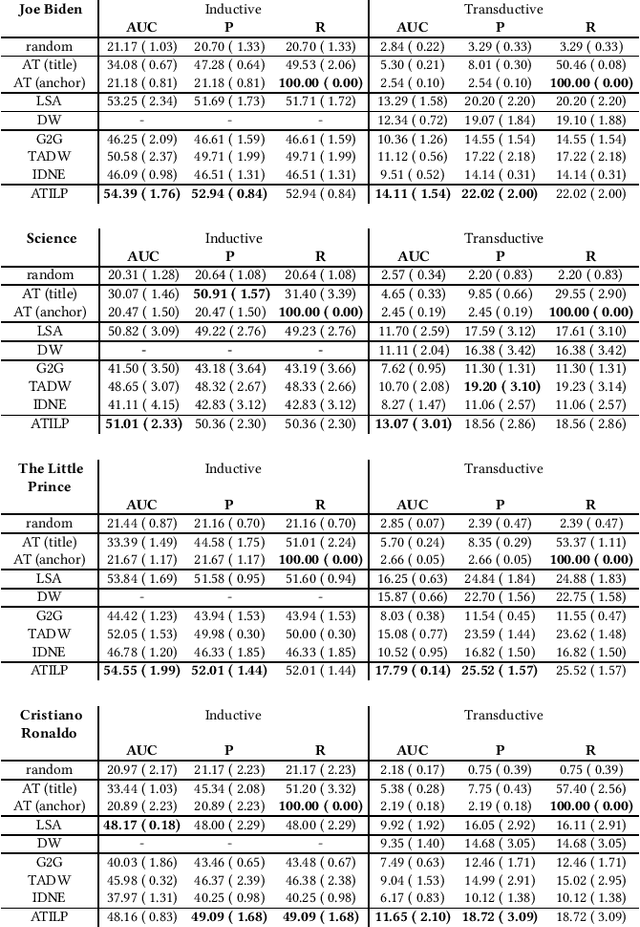
Wikipedia, the largest open-collaborative online encyclopedia, is a corpus of documents bound together by internal hyperlinks. These links form the building blocks of a large network whose structure contains important information on the concepts covered in this encyclopedia. The presence of a link between two articles, materialised by an anchor text in the source page pointing to the target page, can increase readers' understanding of a topic. However, the process of linking follows specific editorial rules to avoid both under-linking and over-linking. In this paper, we study the transductive and the inductive tasks of link prediction on several subsets of the English Wikipedia and identify some key challenges behind automatic linking based on anchor text information. We propose an appropriate evaluation sampling methodology and compare several algorithms. Moreover, we propose baseline models that provide a good estimation of the overall difficulty of the tasks.
Adapting a FrameNet Semantic Parser for Spoken Language Understanding Using Adversarial Learning
Oct 07, 2019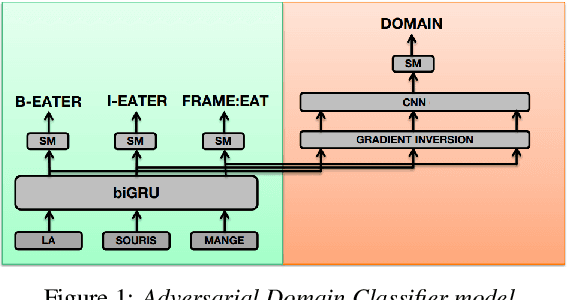
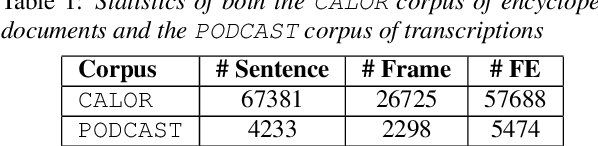
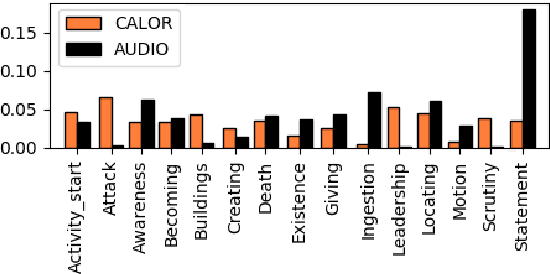
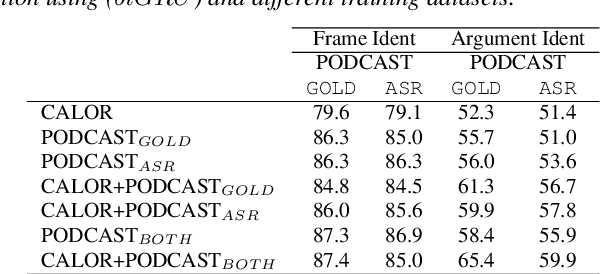
This paper presents a new semantic frame parsing model, based on Berkeley FrameNet, adapted to process spoken documents in order to perform information extraction from broadcast contents. Building upon previous work that had shown the effectiveness of adversarial learning for domain generalization in the context of semantic parsing of encyclopedic written documents, we propose to extend this approach to elocutionary style generalization. The underlying question throughout this study is whether adversarial learning can be used to combine data from different sources and train models on a higher level of abstraction in order to increase their robustness to lexical and stylistic variations as well as automatic speech recognition errors. The proposed strategy is evaluated on a French corpus of encyclopedic written documents and a smaller corpus of radio podcast transcriptions, both annotated with a FrameNet paradigm. We show that adversarial learning increases all models generalization capabilities both on manual and automatic speech transcription as well as on encyclopedic data.
Robust Semantic Parsing with Adversarial Learning for Domain Generalization
Oct 01, 2019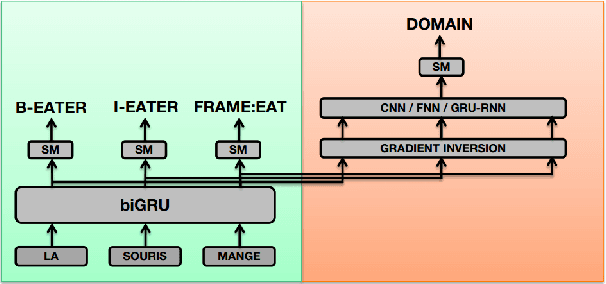


This paper addresses the issue of generalization for Semantic Parsing in an adversarial framework. Building models that are more robust to inter-document variability is crucial for the integration of Semantic Parsing technologies in real applications. The underlying question throughout this study is whether adversarial learning can be used to train models on a higher level of abstraction in order to increase their robustness to lexical and stylistic variations.We propose to perform Semantic Parsing with a domain classification adversarial task without explicit knowledge of the domain. The strategy is first evaluated on a French corpus of encyclopedic documents, annotated with FrameNet, in an information retrieval perspective, then on PropBank Semantic Role Labeling task on the CoNLL-2005 benchmark. We show that adversarial learning increases all models generalization capabilities both on in and out-of-domain data.
Un duel probabiliste pour départager deux présidents (LIA @ DEFT'2005)
Mar 11, 2019
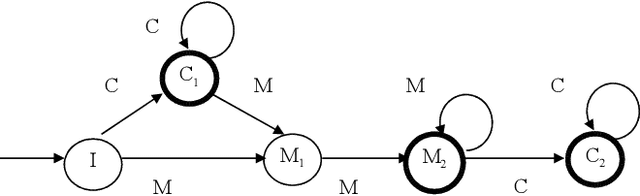
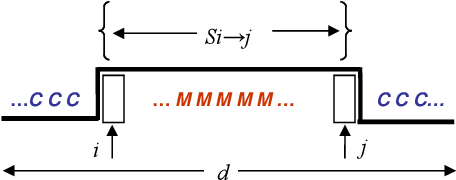
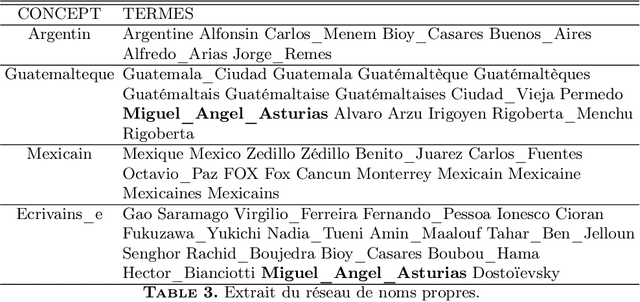
We present a set of probabilistic models applied to binary classification as defined in the DEFT'05 challenge. The challenge consisted a mixture of two differents problems in Natural Language Processing : identification of author (a sequence of Fran\c{c}ois Mitterrand's sentences might have been inserted into a speech of Jacques Chirac) and thematic break detection (the subjects addressed by the two authors are supposed to be different). Markov chains, Bayes models and an adaptative process have been used to identify the paternity of these sequences. A probabilistic model of the internal coherence of speeches which has been employed to identify thematic breaks. Adding this model has shown to improve the quality results. A comparison with different approaches demostrates the superiority of a strategy that combines learning, coherence and adaptation. Applied to the DEFT'05 data test the results in terms of precision (0.890), recall (0.955) and Fscore (0.925) measure are very promising.
* 27 figures, 1 table (in French)