 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying several dialectal Nawatl varieties
Jan 05, 2026Mexico is a country with a large number of indigenous languages, among which the most widely spoken is Nawatl, with more than two million people currently speaking it (mainly in North and Central America). Despite its rich cultural heritage, which dates back to the 15th century, Nawatl is a language with few computer resources. The problem is compounded when it comes to its dialectal varieties, with approximately 30 varieties recognised, not counting the different spellings in the written forms of the language. In this research work, we addressed the problem of classifying Nawatl varieties using Machine Learning and Neural Networks.
Two CFG Nahuatl for automatic corpora expansion
Dec 16, 2025The aim of this article is to introduce two Context-Free Grammars (CFG) for Nawatl Corpora expansion. Nawatl is an Amerindian language (it is a National Language of Mexico) of the $π$-language type, i.e. a language with few digital resources. For this reason the corpora available for the learning of Large Language Models (LLMs) are virtually non-existent, posing a significant challenge. The goal is to produce a substantial number of syntactically valid artificial Nawatl sentences and thereby to expand the corpora for the purpose of learning non contextual embeddings. For this objective, we introduce two new Nawatl CFGs and use them in generative mode. Using these grammars, it is possible to expand Nawatl corpus significantly and subsequently to use it to learn embeddings and to evaluate their relevance in a sentences semantic similarity task. The results show an improvement compared to the results obtained using only the original corpus without artificial expansion, and also demonstrate that economic embeddings often perform better than some LLMs.
A First Context-Free Grammar Applied to Nawatl Corpora Augmentation
Oct 06, 2025



In this article we introduce a context-free grammar (CFG) for the Nawatl language. Nawatl (or Nahuatl) is an Amerindian language of the $\pi$-language type, i.e. a language with few digital resources, in which the corpora available for machine learning are virtually non-existent. The objective here is to generate a significant number of grammatically correct artificial sentences, in order to increase the corpora available for language model training. We want to show that a grammar enables us significantly to expand a corpus in Nawatl which we call $\pi$-\textsc{yalli}. The corpus, thus enriched, enables us to train algorithms such as FastText and to evaluate them on sentence-level semantic tasks. Preliminary results show that by using the grammar, comparative improvements are achieved over some LLMs. However, it is observed that to achieve more significant improvement, grammars that model the Nawatl language even more effectively are required.
$π$-yalli: un nouveau corpus pour le nahuatl
Dec 20, 2024



The NAHU$^2$ project is a Franco-Mexican collaboration aimed at building the $\pi$-YALLI corpus adapted to machine learning, which will subsequently be used to develop computer resources for the Nahuatl language. Nahuatl is a language with few computational resources, even though it is a living language spoken by around 2 million people. We have decided to build $\pi$-YALLI, a corpus that will enable to carry out research on Nahuatl in order to develop Language Models (LM), whether dynamic or not, which will make it possible to in turn enable the development of Natural Language Processing (NLP) tools such as: a) a grapheme unifier, b) a word segmenter, c) a POS grammatical analyser, d) a content-based Automatic Text Summarization; and possibly, e) a translator translator (probabilistic or learning-based).
A Preliminary Study for Literary Rhyme Generation based on Neuronal Representation, Semantics and Shallow Parsing
Dec 25, 2021

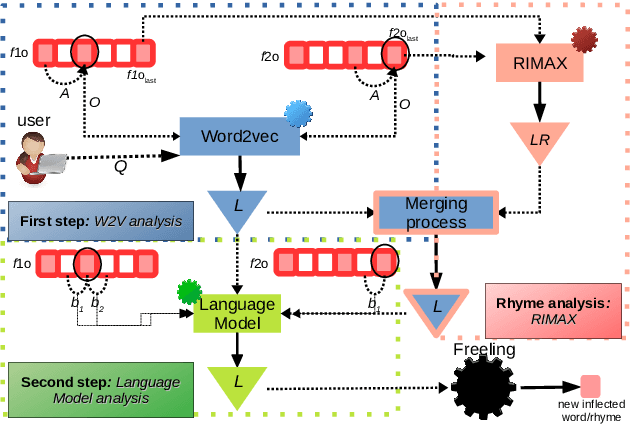
In recent years, researchers in the area of Computational Creativity have studied the human creative process proposing different approaches to reproduce it with a formal procedure. In this paper, we introduce a model for the generation of literary rhymes in Spanish, combining structures of language and neural network models %(\textit{Word2vec}).%, into a structure for semantic assimilation. The results obtained with a manual evaluation of the texts generated by our algorithm are encouraging.
* 7 pages, 2 figures
LUC at ComMA-2021 Shared Task: Multilingual Gender Biased and Communal Language Identification without using linguistic features
Dec 19, 2021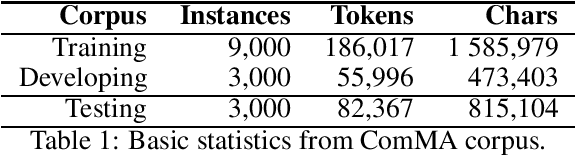
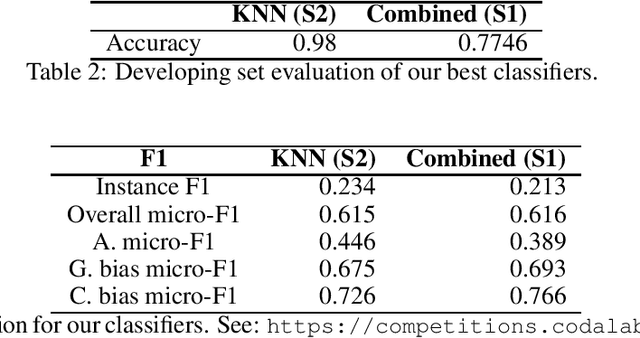
This work aims to evaluate the ability that both probabilistic and state-of-the-art vector space modeling (VSM) methods provide to well known machine learning algorithms to identify social network documents to be classified as aggressive, gender biased or communally charged. To this end, an exploratory stage was performed first in order to find relevant settings to test, i.e. by using training and development samples, we trained multiple algorithms using multiple vector space modeling and probabilistic methods and discarded the less informative configurations. These systems were submitted to the competition of the ComMA@ICON'21 Workshop on Multilingual Gender Biased and Communal Language Identification.
* 6 pages
LiSSS: A toy corpus of Spanish Literary Sentences for Emotions detection
Jun 06, 2020

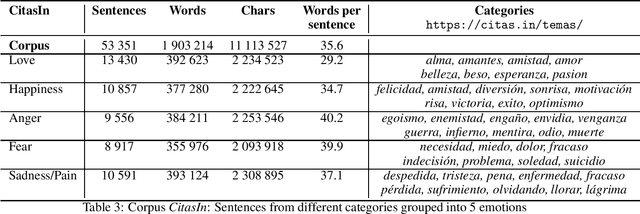
In this work we present a new small data-set in Computational Creativity (CC) field, the Spanish Literary Sentences for emotions detection corpus (LISSS). We address this corpus of literary sentences in order to evaluate or design algorithms of emotions classification and detection. We have constitute this corpus by manually classifying the sentences in a set of emotions: Love, Fear, Happiness, Anger and Sadness/Pain. We also present some baseline classification algorithms applied on our corpus. The LISSS corpus will be available to the community as a free resource to evaluate or create CC-like algorithms.
Automatic Discourse Segmentation: Review and Perspectives
May 01, 2020Multilingual discourse parsing is a very prominent research topic. The first stage for discourse parsing is discourse segmentation. The study reported in this article addresses a review of two on-line available discourse segmenters (for English and Portuguese). We evaluate the possibility of developing similar discourse segmenters for Spanish, French and African languages.
* 5 pages, 1 figure
Extending Text Informativeness Measures to Passage Interestingness Evaluation (Language Model vs. Word Embedding)
Apr 14, 2020
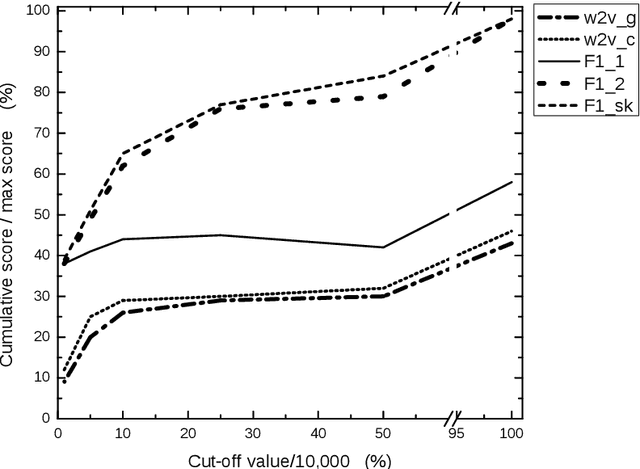

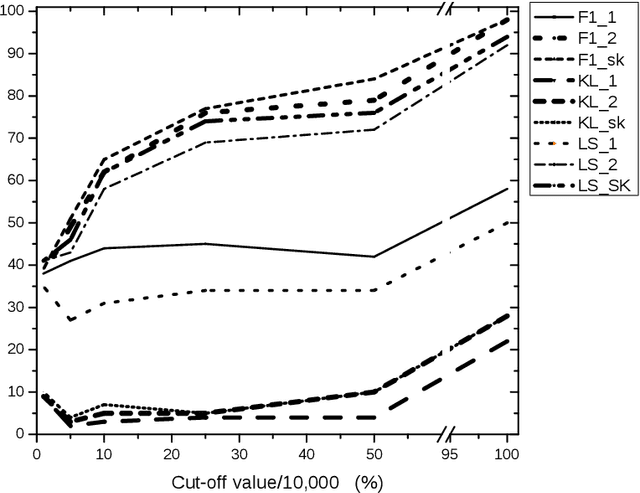
Standard informativeness measures used to evaluate Automatic Text Summarization mostly rely on n-gram overlapping between the automatic summary and the reference summaries. These measures differ from the metric they use (cosine, ROUGE, Kullback-Leibler, Logarithm Similarity, etc.) and the bag of terms they consider (single words, word n-grams, entities, nuggets, etc.). Recent word embedding approaches offer a continuous alternative to discrete approaches based on the presence/absence of a text unit. Informativeness measures have been extended to Focus Information Retrieval evaluation involving a user's information need represented by short queries. In particular for the task of CLEF-INEX Tweet Contextualization, tweet contents have been considered as queries. In this paper we define the concept of Interestingness as a generalization of Informativeness, whereby the information need is diverse and formalized as an unknown set of implicit queries. We then study the ability of state of the art Informativeness measures to cope with this generalization. Lately we show that with this new framework, standard word embeddings outperforms discrete measures only on uni-grams, however bi-grams seems to be a key point of interestingness evaluation. Lastly we prove that the CLEF-INEX Tweet Contextualization 2012 Logarithm Similarity measure provides best results.
A Multilingual Study of Multi-Sentence Compression using Word Vertex-Labeled Graphs and Integer Linear Programming
Apr 09, 2020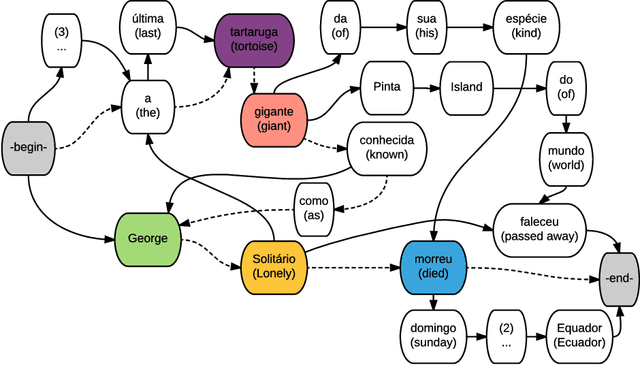
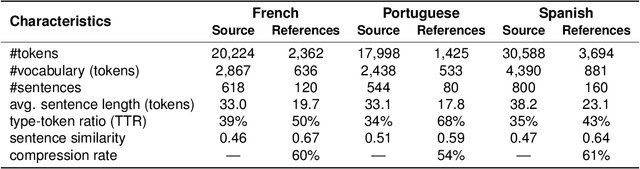
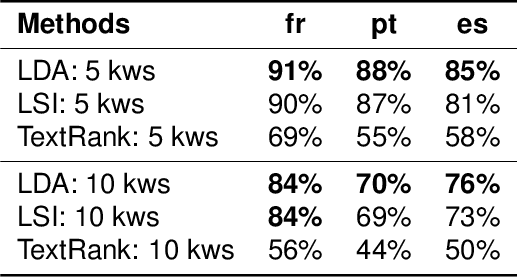
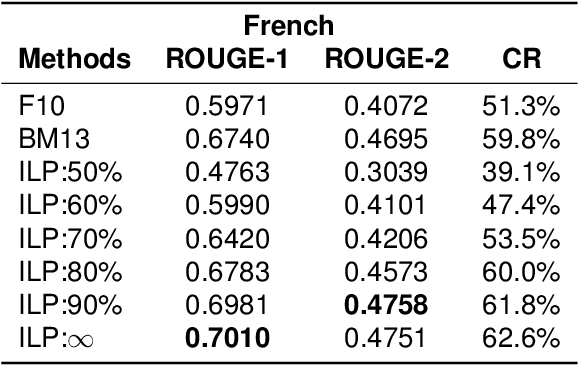
Multi-Sentence Compression (MSC) aims to generate a short sentence with the key information from a cluster of similar sentences. MSC enables summarization and question-answering systems to generate outputs combining fully formed sentences from one or several documents. This paper describes an Integer Linear Programming method for MSC using a vertex-labeled graph to select different keywords, with the goal of generating more informative sentences while maintaining their grammaticality. Our system is of good quality and outperforms the state of the art for evaluations led on news datasets in three languages: French, Portuguese and Spanish. We led both automatic and manual evaluations to determine the informativeness and the grammaticality of compressions for each dataset. In additional tests, which take advantage of the fact that the length of compressions can be modulated, we still improve ROUGE scores with shorter output sentences.
* Preprint version