 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Text Informativeness Measures to Passage Interestingness Evaluation (Language Model vs. Word Embedding)
Apr 14, 2020
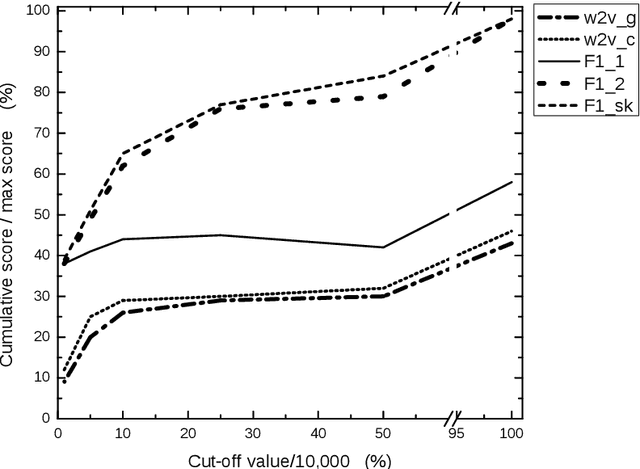

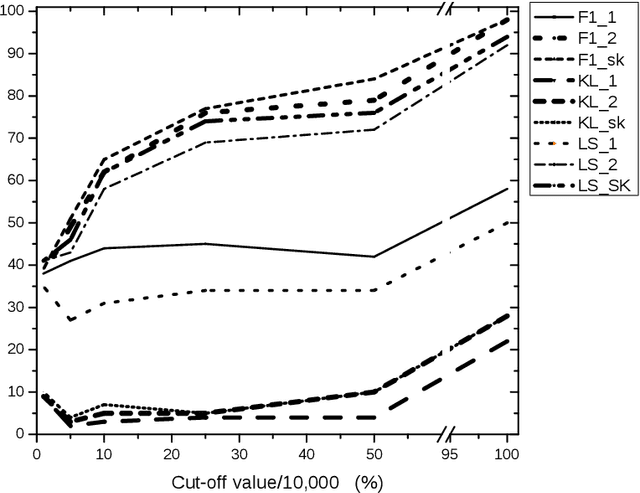
Standard informativeness measures used to evaluate Automatic Text Summarization mostly rely on n-gram overlapping between the automatic summary and the reference summaries. These measures differ from the metric they use (cosine, ROUGE, Kullback-Leibler, Logarithm Similarity, etc.) and the bag of terms they consider (single words, word n-grams, entities, nuggets, etc.). Recent word embedding approaches offer a continuous alternative to discrete approaches based on the presence/absence of a text unit. Informativeness measures have been extended to Focus Information Retrieval evaluation involving a user's information need represented by short queries. In particular for the task of CLEF-INEX Tweet Contextualization, tweet contents have been considered as queries. In this paper we define the concept of Interestingness as a generalization of Informativeness, whereby the information need is diverse and formalized as an unknown set of implicit queries. We then study the ability of state of the art Informativeness measures to cope with this generalization. Lately we show that with this new framework, standard word embeddings outperforms discrete measures only on uni-grams, however bi-grams seems to be a key point of interestingness evaluation. Lastly we prove that the CLEF-INEX Tweet Contextualization 2012 Logarithm Similarity measure provides best results.
Audio Summarization with Audio Features and Probability Distribution Divergence
Jan 20, 2020
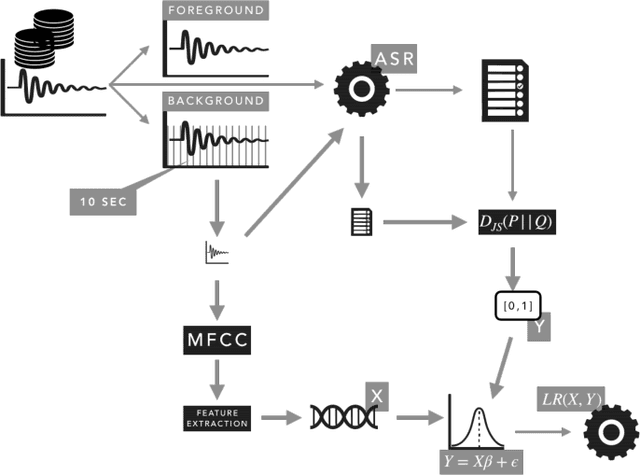
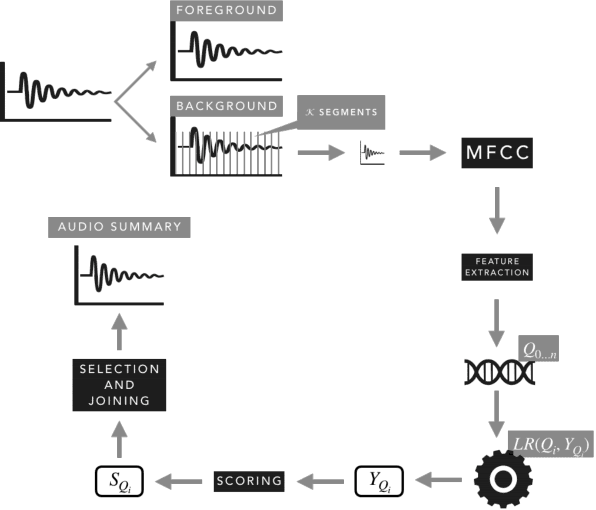

The automatic summarization of multimedia sources is an important task that facilitates the understanding of an individual by condensing the source while maintaining relevant information. In this paper we focus on audio summarization based on audio features and the probability of distribution divergence. Our method, based on an extractive summarization approach, aims to select the most relevant segments until a time threshold is reached. It takes into account the segment's length, position and informativeness value. Informativeness of each segment is obtained by mapping a set of audio features issued from its Mel-frequency Cepstral Coefficients and their corresponding Jensen-Shannon divergence score. Results over a multi-evaluator scheme shows that our approach provides understandable and informative summaries.
Intweetive Text Summarization
Jan 16, 2020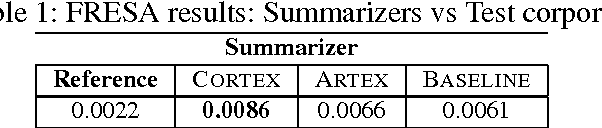


The amount of user generated contents from various social medias allows analyst to handle a wide view of conversations on several topics related to their business. Nevertheless keeping up-to-date with this amount of information is not humanly feasible. Automatic Summarization then provides an interesting mean to digest the dynamics and the mass volume of contents. In this paper, we address the issue of tweets summarization which remains scarcely explored. We propose to automatically generated summaries of Micro-Blogs conversations dealing with public figures E-Reputation. These summaries are generated using key-word queries or sample tweet and offer a focused view of the whole Micro-Blog network. Since state-of-the-art is lacking on this point we conduct and evaluate our experiments over the multilingual CLEF RepLab Topic-Detection dataset according to an experimental evaluation process.
* 8 pages, 4 tables
Étude de l'informativité des transcriptions : une approche basée sur le résumé automatique
Sep 04, 2018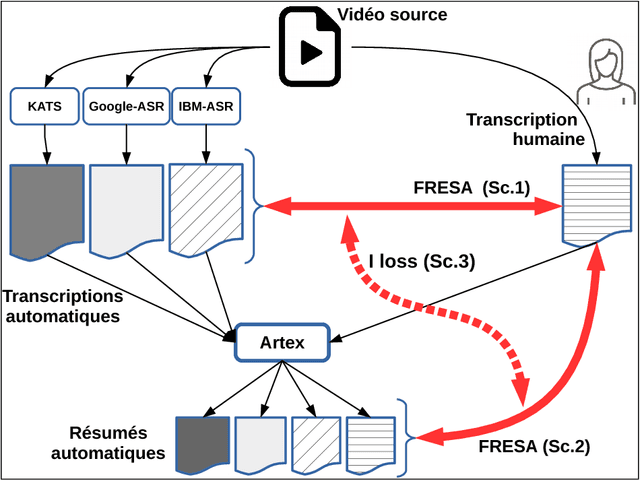
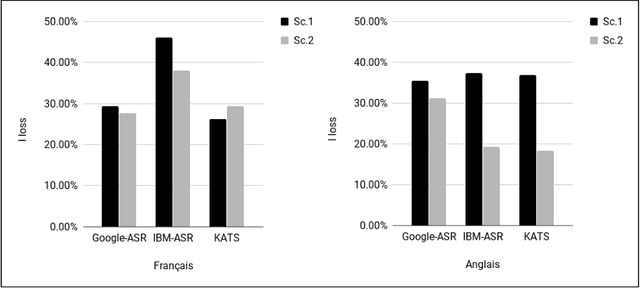
In this paper we propose a new approach to evaluate the informativeness of transcriptions coming from Automatic Speech Recognition systems. This approach, based in the notion of informativeness, is focused on the framework of Automatic Text Summarization performed over these transcriptions. At a first glance we estimate the informative content of the various automatic transcriptions, then we explore the capacity of Automatic Text Summarization to overcome the informative loss. To do this we use an automatic summary evaluation protocol without reference (based on the informative content), which computes the divergence between probability distributions of different textual representations: manual and automatic transcriptions and their summaries. After a set of evaluations this analysis allowed us to judge both the quality of the transcriptions in terms of informativeness and to assess the ability of automatic text summarization to compensate the problems raised during the transcription phase.
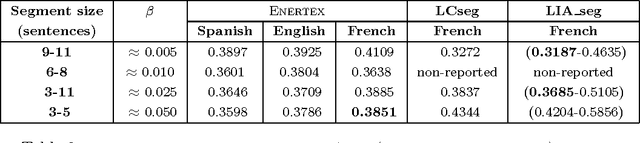
Extending Automatic Discourse Segmentation for Texts in Spanish to Catalan
Mar 11, 2017

At present, automatic discourse analysis is a relevant research topic in the field of NLP. However, discourse is one of the phenomena most difficult to process. Although discourse parsers have been already developed for several languages, this tool does not exist for Catalan. In order to implement this kind of parser, the first step is to develop a discourse segmenter. In this article we present the first discourse segmenter for texts in Catalan. This segmenter is based on Rhetorical Structure Theory (RST) for Spanish, and uses lexical and syntactic information to translate rules valid for Spanish into rules for Catalan. We have evaluated the system by using a gold standard corpus including manually segmented texts and results are promising.
Sentence Compression in Spanish driven by Discourse Segmentation and Language Models
Dec 17, 2012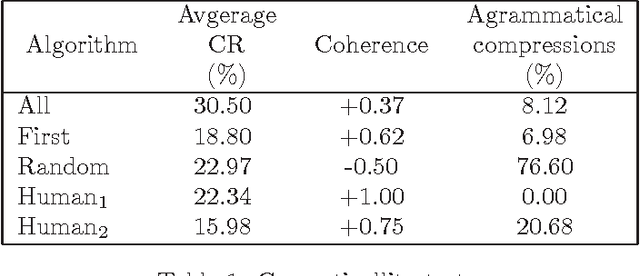

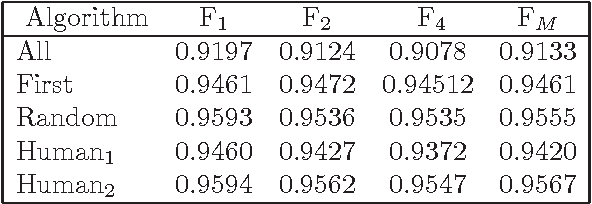
Previous works demonstrated that Automatic Text Summarization (ATS) by sentences extraction may be improved using sentence compression. In this work we present a sentence compressions approach guided by level-sentence discourse segmentation and probabilistic language models (LM). The results presented here show that the proposed solution is able to generate coherent summaries with grammatical compressed sentences. The approach is simple enough to be transposed into other languages.
Statistical Physics for Natural Language Processing
Jul 01, 2011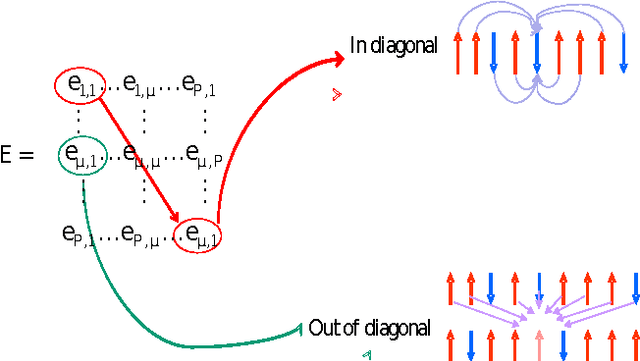


This paper has been withdrawn by the author.