 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges of language technologies for the indigenous languages of the Americas
Jun 12, 2018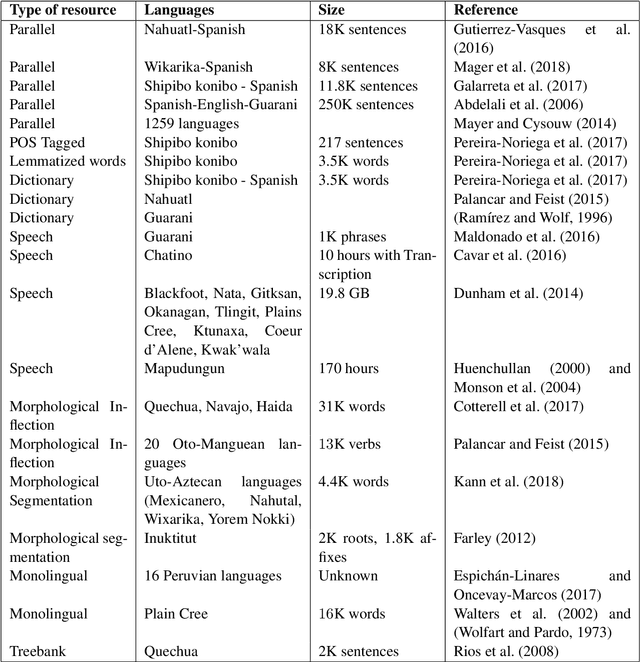
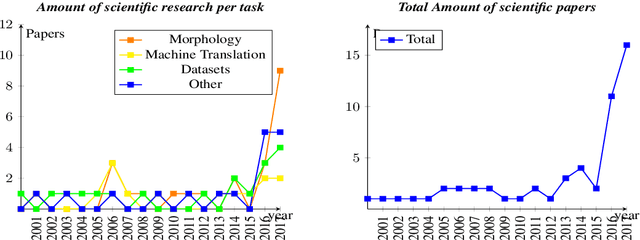
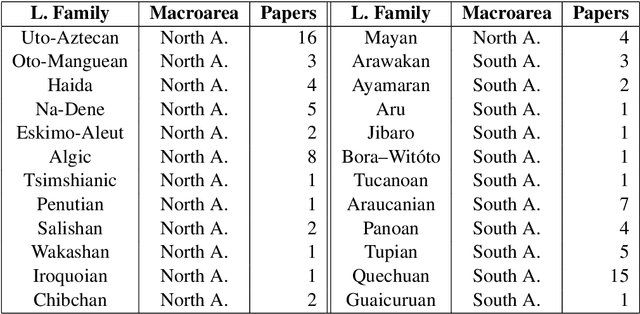
Indigenous languages of the American continent are highly diverse. However, they have received little attention from the technological perspective. In this paper, we review the research, the digital resources and the available NLP systems that focus on these languages. We present the main challenges and research questions that arise when distant languages and low-resource scenarios are faced. We would like to encourage NLP research in linguistically rich and diverse areas like the Americas.
Unsupervised Sentence Representations as Word Information Series: Revisiting TF--IDF
Oct 20, 2017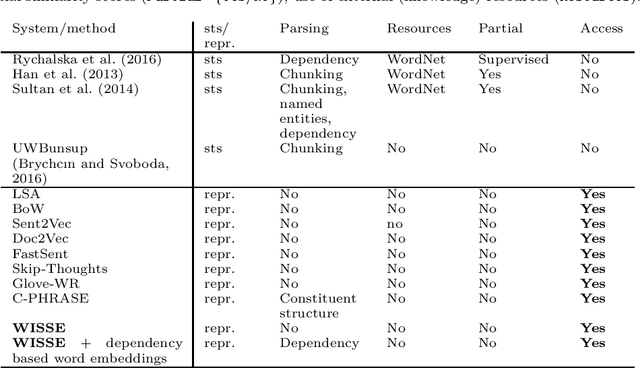


Sentence representation at the semantic level is a challenging task for Natural Language Processing and Artificial Intelligence. Despite the advances in word embeddings (i.e. word vector representations), capturing sentence meaning is an open question due to complexities of semantic interactions among words. In this paper, we present an embedding method, which is aimed at learning unsupervised sentence representations from unlabeled text. We propose an unsupervised method that models a sentence as a weighted series of word embeddings. The weights of the word embeddings are fitted by using Shannon's word entropies provided by the Term Frequency--Inverse Document Frequency (TF--IDF) transform. The hyperparameters of the model can be selected according to the properties of data (e.g. sentence length and textual gender). Hyperparameter selection involves word embedding methods and dimensionalities, as well as weighting schemata. Our method offers advantages over existing methods: identifiable modules, short-term training, online inference of (unseen) sentence representations, as well as independence from domain, external knowledge and language resources. Results showed that our model outperformed the state of the art in well-known Semantic Textual Similarity (STS) benchmarks. Moreover, our model reached state-of-the-art performance when compared to supervised and knowledge-based STS systems.
A German Corpus for Text Similarity Detection Tasks
Mar 11, 2017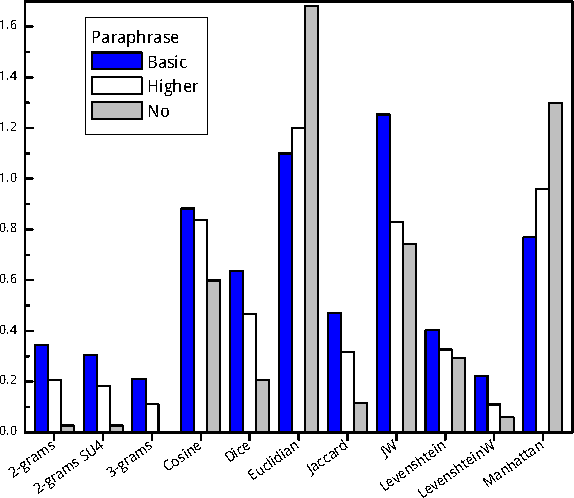
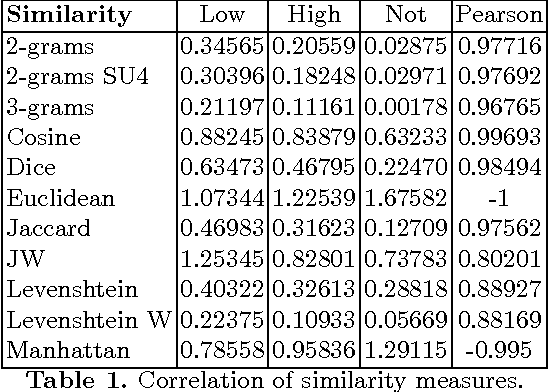
Text similarity detection aims at measuring the degree of similarity between a pair of texts. Corpora available for text similarity detection are designed to evaluate the algorithms to assess the paraphrase level among documents. In this paper we present a textual German corpus for similarity detection. The purpose of this corpus is to automatically assess the similarity between a pair of texts and to evaluate different similarity measures, both for whole documents or for individual sentences. Therefore we have calculated several simple measures on our corpus based on a library of similarity functions.
* 1 figure; 13 pages
Efficient Social Network Multilingual Classification using Character, POS n-grams and Dynamic Normalization
Feb 21, 2017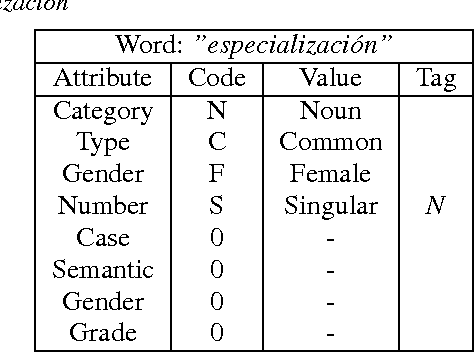
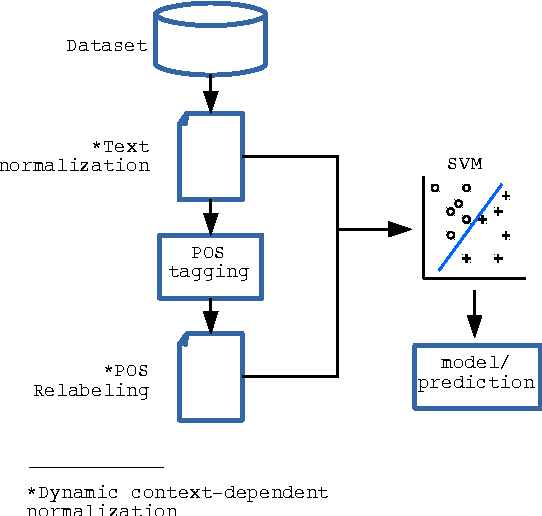

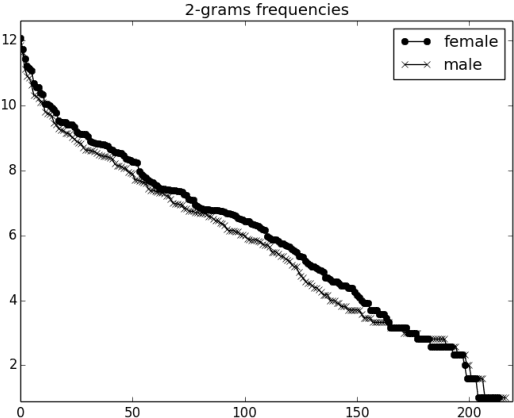
In this paper we describe a dynamic normalization process applied to social network multilingual documents (Facebook and Twitter) to improve the performance of the Author profiling task for short texts. After the normalization process, $n$-grams of characters and n-grams of POS tags are obtained to extract all the possible stylistic information encoded in the documents (emoticons, character flooding, capital letters, references to other users, hyperlinks, hashtags, etc.). Experiments with SVM showed up to 90% of performance.
* 8 pages, 6 figures, Conference paper
Regroupement sémantique de définitions en espagnol
Jan 20, 2015
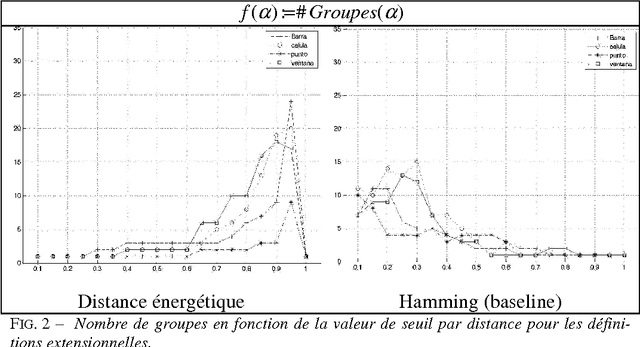
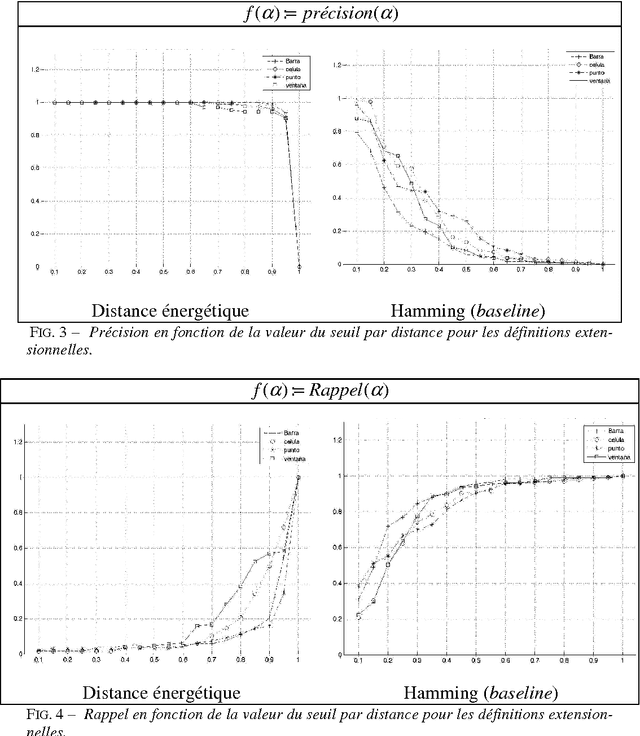
This article focuses on the description and evaluation of a new unsupervised learning method of clustering of definitions in Spanish according to their semantic. Textual Energy was used as a clustering measure, and we study an adaptation of the Precision and Recall to evaluate our method.
Sentence Compression in Spanish driven by Discourse Segmentation and Language Models
Dec 17, 2012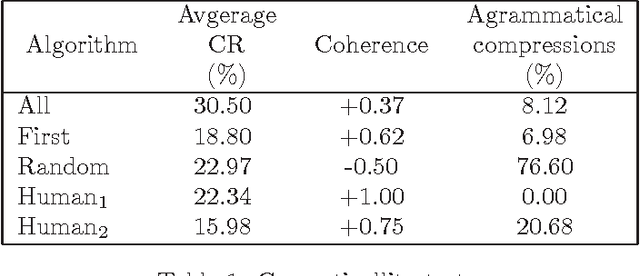

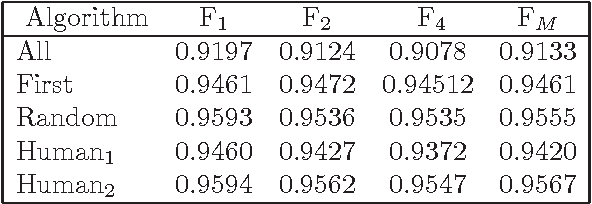
Previous works demonstrated that Automatic Text Summarization (ATS) by sentences extraction may be improved using sentence compression. In this work we present a sentence compressions approach guided by level-sentence discourse segmentation and probabilistic language models (LM). The results presented here show that the proposed solution is able to generate coherent summaries with grammatical compressed sentences. The approach is simple enough to be transposed into other languages.