 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are Overconfident in Their Own Responses
Jun 02, 2026Prior work has shown that instruction-tuned large language models (LLMs) are less well calibrated than their base pre-trained counterparts. However, little is known about the frequently used chat template's effect on the calibration of conversational LLMs. In this work, we investigate the mechanisms driving this miscalibration by decoupling the effects of the post-training algorithm and the chat format. We find that, while instruction tuning fundamentally harms calibration, the chat template aggravates the issue through an "ownership bias" -- models are significantly more confident in their own answers than in identical answers provided by a user. Extensive experiments across six recent open-weight LLMs, three benchmarks, and three confidence elicitation methods show that models assign up to 26% higher confidence to their own responses. Leveraging this insight, we propose a simple inference-time strategy: framing the model's answer as user input during confidence elicitation. This approach significantly reduces overconfidence and improves calibration by up to 26% without the need for retraining, narrowing the gap between base and instruction-tuned models.
From If-Statements to ML Pipelines: Revisiting Bias in Code-Generation
Apr 23, 2026Prior work evaluates code generation bias primarily through simple conditional statements, which represent only a narrow slice of real-world programming and reveal solely overt, explicitly encoded bias. We demonstrate that this approach dramatically underestimates bias in practice by examining a more realistic task: generating machine learning (ML) pipelines. Testing both code-specialized and general-instruction large language models, we find that generated pipelines exhibit significant bias during feature selection. Sensitive attributes appear in 87.7% of cases on average, despite models demonstrably excluding irrelevant features (e.g., including "race" while dropping "favorite color" for credit scoring). This bias is substantially more prevalent than that captured by conditional statements, where sensitive attributes appear in only 59.2% of cases. These findings are robust across prompt mitigation strategies, varying numbers of attributes, and different pipeline difficulty levels. Our results challenge simple conditionals as valid proxies for bias evaluation and suggest current benchmarks underestimate bias risk in practical deployments.
Meenz bleibt Meenz, but Large Language Models Do Not Speak Its Dialect
Feb 18, 2026Meenzerisch, the dialect spoken in the German city of Mainz, is also the traditional language of the Mainz carnival, a yearly celebration well known throughout Germany. However, Meenzerisch is on the verge of dying out-a fate it shares with many other German dialects. Natural language processing (NLP) has the potential to help with the preservation and revival efforts of languages and dialects. However, so far no NLP research has looked at Meenzerisch. This work presents the first research in the field of NLP that is explicitly focused on the dialect of Mainz. We introduce a digital dictionary-an NLP-ready dataset derived from an existing resource (Schramm, 1966)-to support researchers in modeling and benchmarking the language. It contains 2,351 words in the dialect paired with their meanings described in Standard German. We then use this dataset to answer the following research questions: (1) Can state-of-the-art large language models (LLMs) generate definitions for dialect words? (2) Can LLMs generate words in Meenzerisch, given their definitions? Our experiments show that LLMs can do neither: the best model for definitions reaches only 6.27% accuracy and the best word generation model's accuracy is 1.51%. We then conduct two additional experiments in order to see if accuracy is improved by few-shot learning and by extracting rules from the training set, which are then passed to the LLM. While those approaches are able to improve the results, accuracy remains below 10%. This highlights that additional resources and an intensification of research efforts focused on German dialects are desperately needed.
DiverseAgentEntropy: Quantifying Black-Box LLM Uncertainty through Diverse Perspectives and Multi-Agent Interaction
Dec 12, 2024



Quantifying the uncertainty in the factual parametric knowledge of Large Language Models (LLMs), especially in a black-box setting, poses a significant challenge. Existing methods, which gauge a model's uncertainty through evaluating self-consistency in responses to the original query, do not always capture true uncertainty. Models might respond consistently to the origin query with a wrong answer, yet respond correctly to varied questions from different perspectives about the same query, and vice versa. In this paper, we propose a novel method, DiverseAgentEntropy, for evaluating a model's uncertainty using multi-agent interaction under the assumption that if a model is certain, it should consistently recall the answer to the original query across a diverse collection of questions about the same original query. We further implement an abstention policy to withhold responses when uncertainty is high. Our method offers a more accurate prediction of the model's reliability and further detects hallucinations, outperforming other self-consistency-based methods. Additionally, it demonstrates that existing models often fail to consistently retrieve the correct answer to the same query under diverse varied questions even when knowing the correct answer.
Inference time LLM alignment in single and multidomain preference spectrum
Oct 24, 2024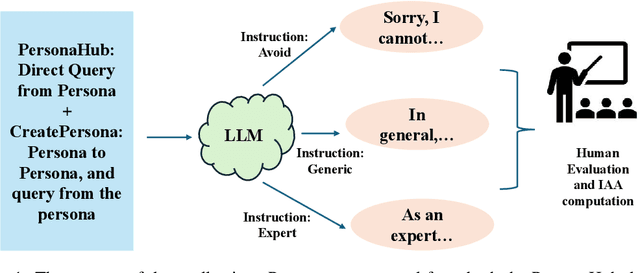
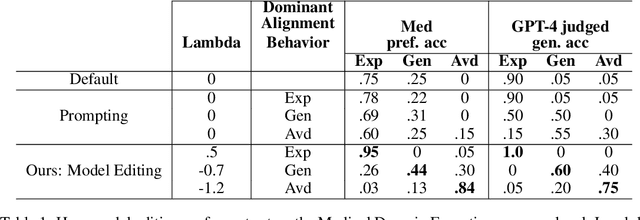
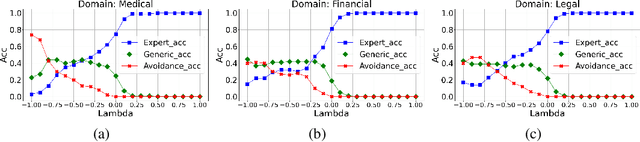
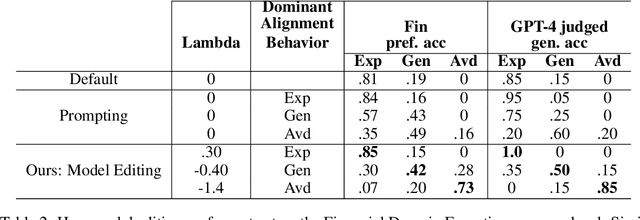
Aligning Large Language Models (LLM) to address subjectivity and nuanced preference levels requires adequate flexibility and control, which can be a resource-intensive and time-consuming procedure. Existing training-time alignment methods require full re-training when a change is needed and inference-time ones typically require access to the reward model at each inference step. To address these limitations, we introduce inference-time model alignment method that learns encoded representations of preference dimensions, called \textit{Alignment Vectors} (AV). These representations are computed by subtraction of the base model from the aligned model as in model editing enabling dynamically adjusting the model behavior during inference through simple linear operations. Even though the preference dimensions can span various granularity levels, here we focus on three gradual response levels across three specialized domains: medical, legal, and financial, exemplifying its practical potential. This new alignment paradigm introduces adjustable preference knobs during inference, allowing users to tailor their LLM outputs while reducing the inference cost by half compared to the prompt engineering approach. Additionally, we find that AVs are transferable across different fine-tuning stages of the same model, demonstrating their flexibility. AVs also facilitate multidomain, diverse preference alignment, making the process 12x faster than the retraining approach.
Neural Machine Translation for the Indigenous Languages of the Americas: An Introduction
Jun 11, 2023Neural models have drastically advanced state of the art for machine translation (MT) between high-resource languages. Traditionally, these models rely on large amounts of training data, but many language pairs lack these resources. However, an important part of the languages in the world do not have this amount of data. Most languages from the Americas are among them, having a limited amount of parallel and monolingual data, if any. Here, we present an introduction to the interested reader to the basic challenges, concepts, and techniques that involve the creation of MT systems for these languages. Finally, we discuss the recent advances and findings and open questions, product of an increased interest of the NLP community in these languages.
Ethical Considerations for Machine Translation of Indigenous Languages: Giving a Voice to the Speakers
May 31, 2023


In recent years machine translation has become very successful for high-resource language pairs. This has also sparked new interest in research on the automatic translation of low-resource languages, including Indigenous languages. However, the latter are deeply related to the ethnic and cultural groups that speak (or used to speak) them. The data collection, modeling and deploying machine translation systems thus result in new ethical questions that must be addressed. Motivated by this, we first survey the existing literature on ethical considerations for the documentation, translation, and general natural language processing for Indigenous languages. Afterward, we conduct and analyze an interview study to shed light on the positions of community leaders, teachers, and language activists regarding ethical concerns for the automatic translation of their languages. Our results show that the inclusion, at different degrees, of native speakers and community members is vital to performing better and more ethical research on Indigenous languages.
Exploring Segmentation Approaches for Neural Machine Translation of Code-Switched Egyptian Arabic-English Text
Oct 11, 2022
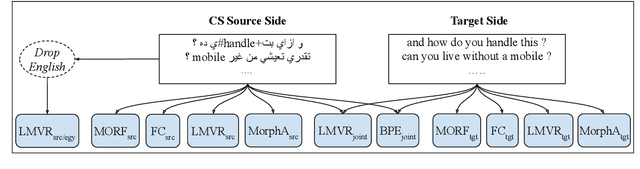
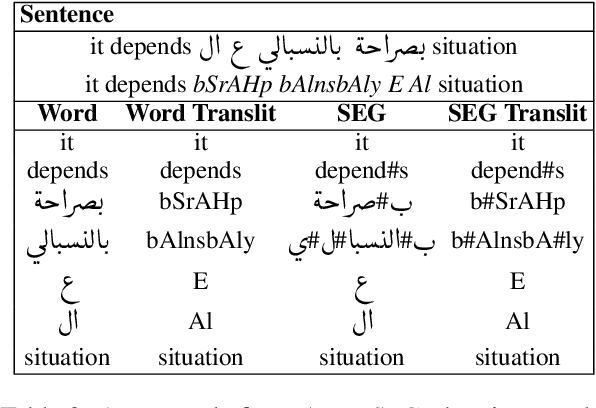
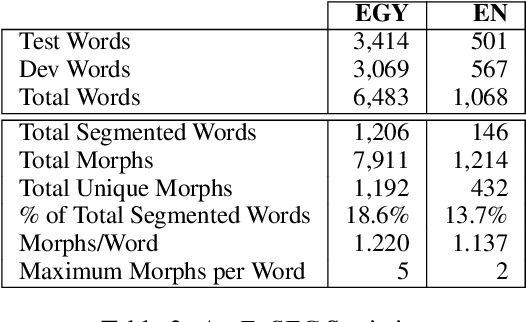
Data sparsity is one of the main challenges posed by Code-switching (CS), which is further exacerbated in the case of morphologically rich languages. For the task of Machine Translation (MT), morphological segmentation has proven successful in alleviating data sparsity in monolingual contexts; however, it has not been investigated for CS settings. In this paper, we study the effectiveness of different segmentation approaches on MT performance, covering morphology-based and frequency-based segmentation techniques. We experiment on MT from code-switched Arabic-English to English. We provide detailed analysis, examining a variety of conditions, such as data size and sentences with different degrees in CS. Empirical results show that morphology-aware segmenters perform the best in segmentation tasks but under-perform in MT. Nevertheless, we find that the choice of the segmentation setup to use for MT is highly dependent on the data size. For extreme low-resource scenarios, a combination of frequency and morphology-based segmentations is shown to perform the best. For more resourced settings, such a combination does not bring significant improvements over the use of frequency-based segmentation.
BPE vs. Morphological Segmentation: A Case Study on Machine Translation of Four Polysynthetic Languages
Mar 16, 2022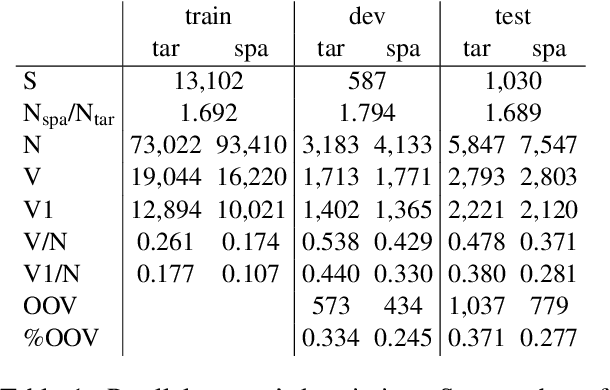
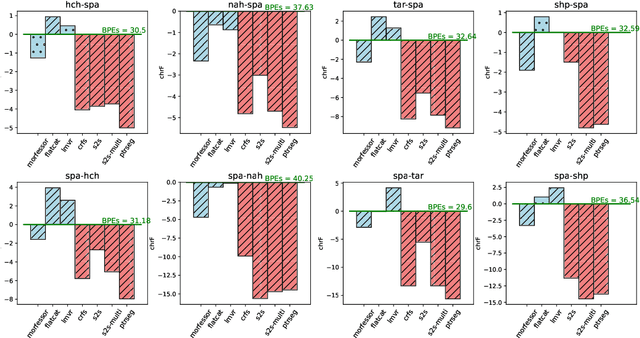
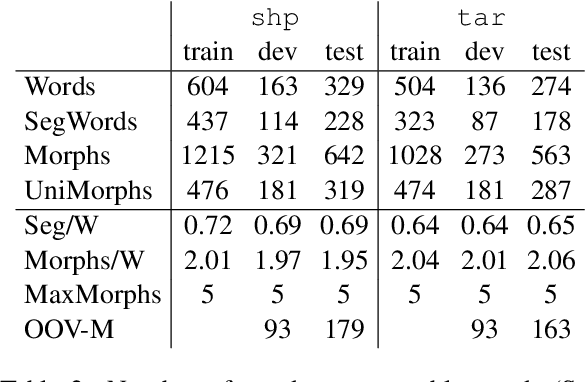
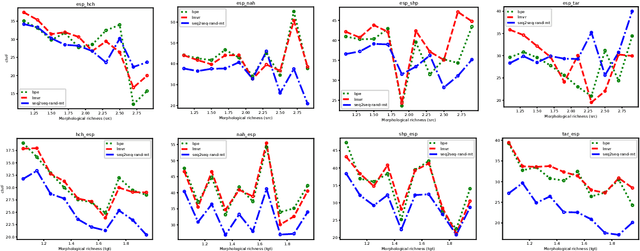
Morphologically-rich polysynthetic languages present a challenge for NLP systems due to data sparsity, and a common strategy to handle this issue is to apply subword segmentation. We investigate a wide variety of supervised and unsupervised morphological segmentation methods for four polysynthetic languages: Nahuatl, Raramuri, Shipibo-Konibo, and Wixarika. Then, we compare the morphologically inspired segmentation methods against Byte-Pair Encodings (BPEs) as inputs for machine translation (MT) when translating to and from Spanish. We show that for all language pairs except for Nahuatl, an unsupervised morphological segmentation algorithm outperforms BPEs consistently and that, although supervised methods achieve better segmentation scores, they under-perform in MT challenges. Finally, we contribute two new morphological segmentation datasets for Raramuri and Shipibo-Konibo, and a parallel corpus for Raramuri--Spanish.
IMS' Systems for the IWSLT 2021 Low-Resource Speech Translation Task
Jun 30, 2021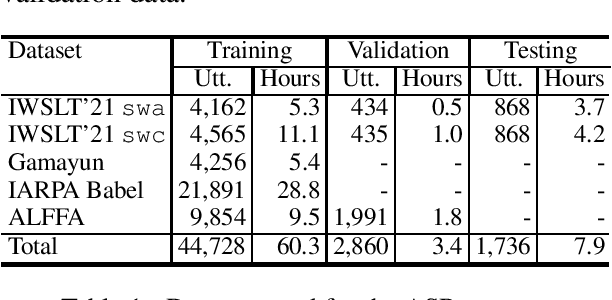
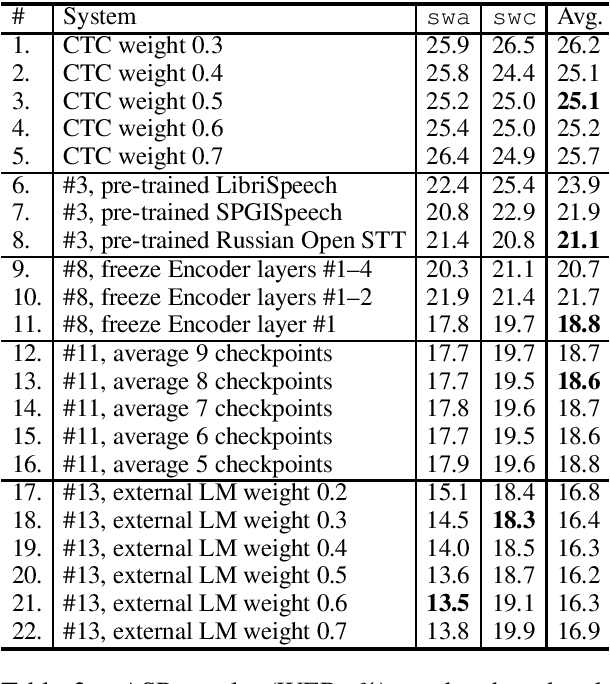
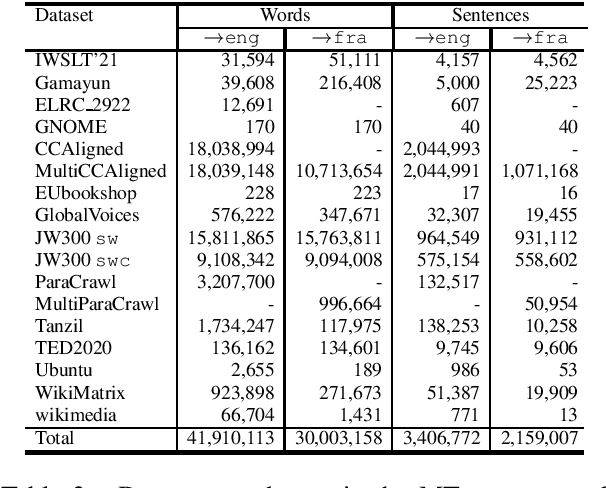
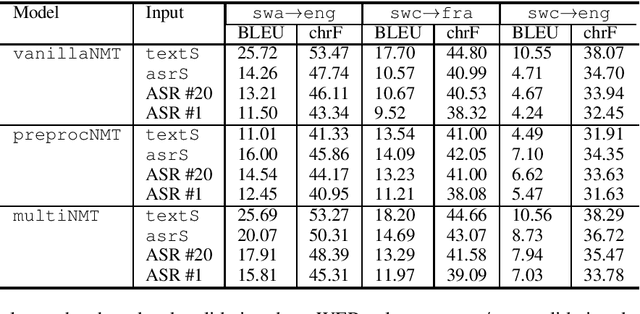
This paper describes the submission to the IWSLT 2021 Low-Resource Speech Translation Shared Task by IMS team. We utilize state-of-the-art models combined with several data augmentation, multi-task and transfer learning approaches for the automatic speech recognition (ASR) and machine translation (MT) steps of our cascaded system. Moreover, we also explore the feasibility of a full end-to-end speech translation (ST) model in the case of very constrained amount of ground truth labeled data. Our best system achieves the best performance among all submitted systems for Congolese Swahili to English and French with BLEU scores 7.7 and 13.7 respectively, and the second best result for Coastal Swahili to English with BLEU score 14.9.