 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-World Models: Scaling Multi-Task Reinforcement Learning with Modular Latent Dynamics
Feb 01, 2026A fundamental challenge in multi-task reinforcement learning (MTRL) is achieving sample efficiency in visual domains where tasks exhibit substantial heterogeneity in both observations and dynamics. Model-based reinforcement learning offers a promising path to improved sample efficiency through world models, but standard monolithic architectures struggle to capture diverse task dynamics, resulting in poor reconstruction and prediction accuracy. We introduce Mixture-of-World Models (MoW), a scalable architecture that combines modular variational autoencoders for task-adaptive visual compression, a hybrid Transformer-based dynamics model with task-conditioned experts and a shared backbone, and a gradient-based task clustering strategy for efficient parameter allocation. On the Atari 100k benchmark, a single MoW agent trained once on 26 Atari games achieves a mean human-normalized score of 110.4%, competitive with the score of 114.2% achieved by STORM, an ensemble of 26 task-specific models, while using 50% fewer parameters. On Meta-World, MoW achieves a 74.5% average success rate within 300 thousand environment steps, establishing a new state of the art. These results demonstrate that MoW provides a scalable and parameter-efficient foundation for generalist world models.
PoSafeNet: Safe Learning with Poset-Structured Neural Nets
Jan 29, 2026Safe learning is essential for deploying learningbased controllers in safety-critical robotic systems, yet existing approaches often enforce multiple safety constraints uniformly or via fixed priority orders, leading to infeasibility and brittle behavior. In practice, safety requirements are heterogeneous and admit only partial priority relations, where some constraints are comparable while others are inherently incomparable. We formalize this setting as poset-structured safety, modeling safety constraints as a partially ordered set and treating safety composition as a structural property of the policy class. Building on this formulation, we propose PoSafeNet, a differentiable neural safety layer that enforces safety via sequential closed-form projection under poset-consistent constraint orderings, enabling adaptive selection or mixing of valid safety executions while preserving priority semantics by construction. Experiments on multi-obstacle navigation, constrained robot manipulation, and vision-based autonomous driving demonstrate improved feasibility, robustness, and scalability over unstructured and differentiable quadratic program-based safety layers.
Taylor-Lagrange Control for Safety-Critical Systems
Dec 12, 2025This paper proposes a novel Taylor-Lagrange Control (TLC) method for nonlinear control systems to ensure the safety and stability through Taylor's theorem with Lagrange remainder. To achieve this, we expand a safety or stability function with respect to time along the system dynamics using the Lie derivative and Taylor's theorem. This expansion enables the control input to appear in the Taylor series at an order equivalent to the relative degree of the function. We show that the proposed TLC provides necessary and sufficient conditions for system safety and is applicable to systems and constraints of arbitrary relative degree. The TLC exhibits connections with existing Control Barrier Function (CBF) and Control Lyapunov Function (CLF) methods, and it further extends the CBF and CLF methods to the complex domain, especially for higher order cases. Compared to High-Order CBFs (HOCBFs), TLC is less restrictive as it does not require forward invariance of the intersection of a set of safe sets while HOCBFs do. We employ TLC to reformulate a constrained optimal control problem as a sequence of quadratic programs with a zero-order hold implementation method, and demonstrate the safety of zero-order hold TLC using an event-triggered control method to address inter-sampling effects. Finally, we illustrate the effectiveness of the proposed TLC method through an adaptive cruise control system and a robot control problem, and compare it with existing CBF methods.
Safe Motion Planning and Control Using Predictive and Adaptive Barrier Methods for Autonomous Surface Vessels
Oct 01, 2025Safe motion planning is essential for autonomous vessel operations, especially in challenging spaces such as narrow inland waterways. However, conventional motion planning approaches are often computationally intensive or overly conservative. This paper proposes a safe motion planning strategy combining Model Predictive Control (MPC) and Control Barrier Functions (CBFs). We introduce a time-varying inflated ellipse obstacle representation, where the inflation radius is adjusted depending on the relative position and attitude between the vessel and the obstacle. The proposed adaptive inflation reduces the conservativeness of the controller compared to traditional fixed-ellipsoid obstacle formulations. The MPC solution provides an approximate motion plan, and high-order CBFs ensure the vessel's safety using the varying inflation radius. Simulation and real-world experiments demonstrate that the proposed strategy enables the fully-actuated autonomous robot vessel to navigate through narrow spaces in real time and resolve potential deadlocks, all while ensuring safety.
Robust Online Residual Refinement via Koopman-Guided Dynamics Modeling
Sep 16, 2025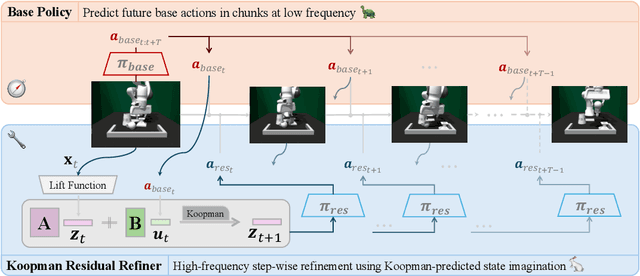
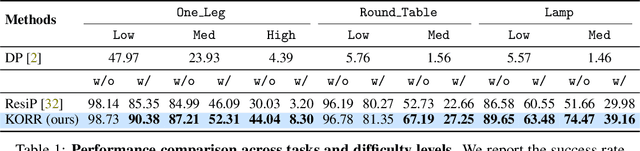


Imitation learning (IL) enables efficient skill acquisition from demonstrations but often struggles with long-horizon tasks and high-precision control due to compounding errors. Residual policy learning offers a promising, model-agnostic solution by refining a base policy through closed-loop corrections. However, existing approaches primarily focus on local corrections to the base policy, lacking a global understanding of state evolution, which limits robustness and generalization to unseen scenarios. To address this, we propose incorporating global dynamics modeling to guide residual policy updates. Specifically, we leverage Koopman operator theory to impose linear time-invariant structure in a learned latent space, enabling reliable state transitions and improved extrapolation for long-horizon prediction and unseen environments. We introduce KORR (Koopman-guided Online Residual Refinement), a simple yet effective framework that conditions residual corrections on Koopman-predicted latent states, enabling globally informed and stable action refinement. We evaluate KORR on long-horizon, fine-grained robotic furniture assembly tasks under various perturbations. Results demonstrate consistent gains in performance, robustness, and generalization over strong baselines. Our findings further highlight the potential of Koopman-based modeling to bridge modern learning methods with classical control theory.
Integrating Trajectory Optimization and Reinforcement Learning for Quadrupedal Jumping with Terrain-Adaptive Landing
Sep 16, 2025Jumping constitutes an essential component of quadruped robots' locomotion capabilities, which includes dynamic take-off and adaptive landing. Existing quadrupedal jumping studies mainly focused on the stance and flight phase by assuming a flat landing ground, which is impractical in many real world cases. This work proposes a safe landing framework that achieves adaptive landing on rough terrains by combining Trajectory Optimization (TO) and Reinforcement Learning (RL) together. The RL agent learns to track the reference motion generated by TO in the environments with rough terrains. To enable the learning of compliant landing skills on challenging terrains, a reward relaxation strategy is synthesized to encourage exploration during landing recovery period. Extensive experiments validate the accurate tracking and safe landing skills benefiting from our proposed method in various scenarios.
Efficient Online RL Fine Tuning with Offline Pre-trained Policy Only
May 22, 2025Improving the performance of pre-trained policies through online reinforcement learning (RL) is a critical yet challenging topic. Existing online RL fine-tuning methods require continued training with offline pretrained Q-functions for stability and performance. However, these offline pretrained Q-functions commonly underestimate state-action pairs beyond the offline dataset due to the conservatism in most offline RL methods, which hinders further exploration when transitioning from the offline to the online setting. Additionally, this requirement limits their applicability in scenarios where only pre-trained policies are available but pre-trained Q-functions are absent, such as in imitation learning (IL) pre-training. To address these challenges, we propose a method for efficient online RL fine-tuning using solely the offline pre-trained policy, eliminating reliance on pre-trained Q-functions. We introduce PORL (Policy-Only Reinforcement Learning Fine-Tuning), which rapidly initializes the Q-function from scratch during the online phase to avoid detrimental pessimism. Our method not only achieves competitive performance with advanced offline-to-online RL algorithms and online RL approaches that leverage data or policies prior, but also pioneers a new path for directly fine-tuning behavior cloning (BC) policies.
Contact-Aware Safety in Soft Robots Using High-Order Control Barrier and Lyapunov Functions
May 05, 2025Robots operating alongside people, particularly in sensitive scenarios such as aiding the elderly with daily tasks or collaborating with workers in manufacturing, must guarantee safety and cultivate user trust. Continuum soft manipulators promise safety through material compliance, but as designs evolve for greater precision, payload capacity, and speed, and increasingly incorporate rigid elements, their injury risk resurfaces. In this letter, we introduce a comprehensive High-Order Control Barrier Function (HOCBF) + High-Order Control Lyapunov Function (HOCLF) framework that enforces strict contact force limits across the entire soft-robot body during environmental interactions. Our approach combines a differentiable Piecewise Cosserat-Segment (PCS) dynamics model with a convex-polygon distance approximation metric, named Differentiable Conservative Separating Axis Theorem (DCSAT), based on the soft robot geometry to enable real-time, whole-body collision detection, resolution, and enforcement of the safety constraints. By embedding HOCBFs into our optimization routine, we guarantee safety and actively regulate environmental coupling, allowing, for instance, safe object manipulation under HOCLF-driven motion objectives. Extensive planar simulations demonstrate that our method maintains safety-bounded contacts while achieving precise shape and task-space regulation. This work thus lays a foundation for the deployment of soft robots in human-centric environments with provable safety and performance.
Towards Long Context Hallucination Detection
Apr 28, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. However, they are prone to contextual hallucination, generating information that is either unsubstantiated or contradictory to the given context. Although many studies have investigated contextual hallucinations in LLMs, addressing them in long-context inputs remains an open problem. In this work, we take an initial step toward solving this problem by constructing a dataset specifically designed for long-context hallucination detection. Furthermore, we propose a novel architecture that enables pre-trained encoder models, such as BERT, to process long contexts and effectively detect contextual hallucinations through a decomposition and aggregation mechanism. Our experimental results show that the proposed architecture significantly outperforms previous models of similar size as well as LLM-based models across various metrics, while providing substantially faster inference.
Control Barrier Functions via Minkowski Operations for Safe Navigation among Polytopic Sets
Apr 01, 2025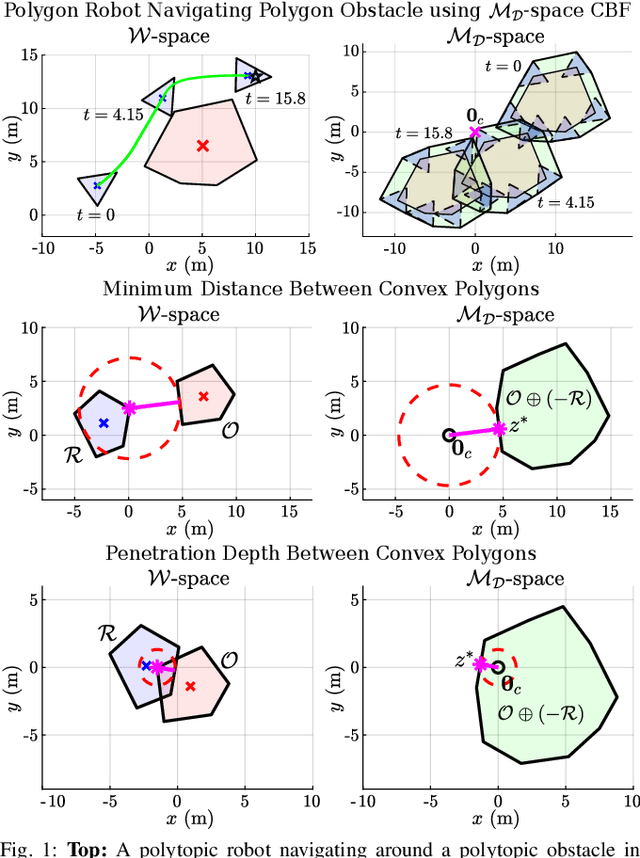
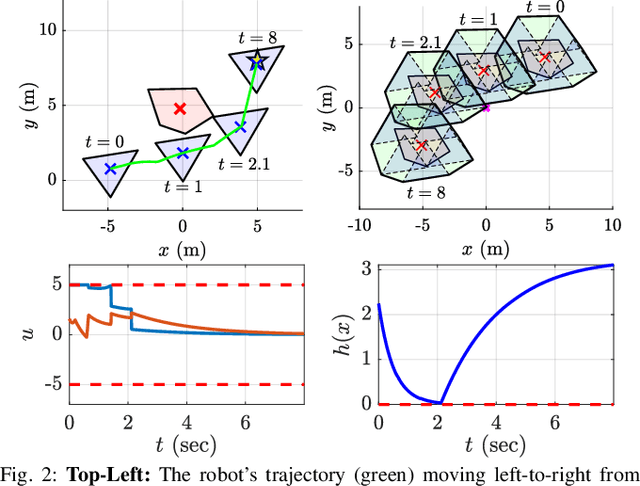
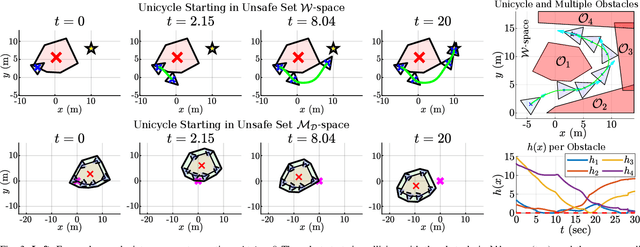

Safely navigating around obstacles while respecting the dynamics, control, and geometry of the underlying system is a key challenge in robotics. Control Barrier Functions (CBFs) generate safe control policies by considering system dynamics and geometry when calculating safe forward-invariant sets. Existing CBF-based methods often rely on conservative shape approximations, like spheres or ellipsoids, which have explicit and differentiable distance functions. In this paper, we propose an optimization-defined CBF that directly considers the exact Signed Distance Function (SDF) between a polytopic robot and polytopic obstacles. Inspired by the Gilbert-Johnson-Keerthi (GJK) algorithm, we formulate both (i) minimum distance and (ii) penetration depth between polytopic sets as convex optimization problems in the space of Minkowski difference operations (the MD-space). Convenient geometric properties of the MD-space enable the derivatives of implicit SDF between two polytopes to be computed via differentiable optimization. We demonstrate the proposed framework in three scenarios including pure translation, initialization inside an unsafe set, and multi-obstacle avoidance. These three scenarios highlight the generation of a non-conservative maneuver, a recovery after starting in collision, and the consideration of multiple obstacles via pairwise CBF constraint, respectively.