 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-Style: Disentangling Style and Content in Motion with Residual Quantized Representations
Feb 02, 2026Human motion data is inherently rich and complex, containing both semantic content and subtle stylistic features that are challenging to model. We propose a novel method for effective disentanglement of the style and content in human motion data to facilitate style transfer. Our approach is guided by the insight that content corresponds to coarse motion attributes while style captures the finer, expressive details. To model this hierarchy, we employ Residual Vector Quantized Variational Autoencoders (RVQ-VAEs) to learn a coarse-to-fine representation of motion. We further enhance the disentanglement by integrating contrastive learning and a novel information leakage loss with codebook learning to organize the content and the style across different codebooks. We harness this disentangled representation using our simple and effective inference-time technique Quantized Code Swapping, which enables motion style transfer without requiring any fine-tuning for unseen styles. Our framework demonstrates strong versatility across multiple inference applications, including style transfer, style removal, and motion blending.
TimeSeries2Report prompting enables adaptive large language model management of lithium-ion batteries
Dec 18, 2025

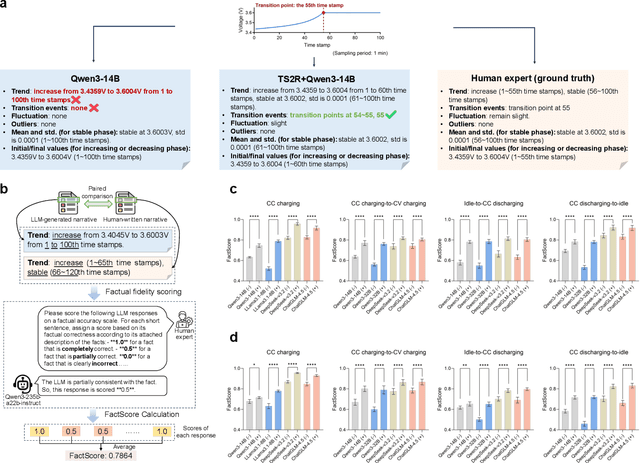

Large language models (LLMs) offer promising capabilities for interpreting multivariate time-series data, yet their application to real-world battery energy storage system (BESS) operation and maintenance remains largely unexplored. Here, we present TimeSeries2Report (TS2R), a prompting framework that converts raw lithium-ion battery operational time-series into structured, semantically enriched reports, enabling LLMs to reason, predict, and make decisions in BESS management scenarios. TS2R encodes short-term temporal dynamics into natural language through a combination of segmentation, semantic abstraction, and rule-based interpretation, effectively bridging low-level sensor signals with high-level contextual insights. We benchmark TS2R across both lab-scale and real-world datasets, evaluating report quality and downstream task performance in anomaly detection, state-of-charge prediction, and charging/discharging management. Compared with vision-, embedding-, and text-based prompting baselines, report-based prompting via TS2R consistently improves LLM performance in terms of across accuracy, robustness, and explainability metrics. Notably, TS2R-integrated LLMs achieve expert-level decision quality and predictive consistency without retraining or architecture modification, establishing a practical path for adaptive, LLM-driven battery intelligence.
Collision-Free Bearing-Driven Formation Tracking for Euler-Lagrange Systems
Aug 13, 2025In this paper, we investigate the problem of tracking formations driven by bearings for heterogeneous Euler-Lagrange systems with parametric uncertainty in the presence of multiple moving leaders. To estimate the leaders' velocities and accelerations, we first design a distributed observer for the leader system, utilizing a bearing-based localization condition in place of the conventional connectivity assumption. This observer, coupled with an adaptive mechanism, enables the synthesis of a novel distributed control law that guides the formation towards the target formation, without requiring prior knowledge of the system parameters. Furthermore, we establish a sufficient condition, dependent on the initial formation configuration, that ensures collision avoidance throughout the formation evolution. The effectiveness of the proposed approach is demonstrated through a numerical example.
Nonadaptive Output Regulation of Second-Order Nonlinear Uncertain Systems
May 28, 2025This paper investigates the robust output regulation problem of second-order nonlinear uncertain systems with an unknown exosystem. Instead of the adaptive control approach, this paper resorts to a robust control methodology to solve the problem and thus avoid the bursting phenomenon. In particular, this paper constructs generic internal models for the steady-state state and input variables of the system. By introducing a coordinate transformation, this paper converts the robust output regulation problem into a nonadaptive stabilization problem of an augmented system composed of the second-order nonlinear uncertain system and the generic internal models. Then, we design the stabilization control law and construct a strict Lyapunov function that guarantees the robustness with respect to unmodeled disturbances. The analysis shows that the output zeroing manifold of the augmented system can be made attractive by the proposed nonadaptive control law, which solves the robust output regulation problem. Finally, we demonstrate the effectiveness of the proposed nonadaptive internal model approach by its application to the control of the Duffing system.
Optimal Output Feedback Learning Control for Discrete-Time Linear Quadratic Regulation
Mar 08, 2025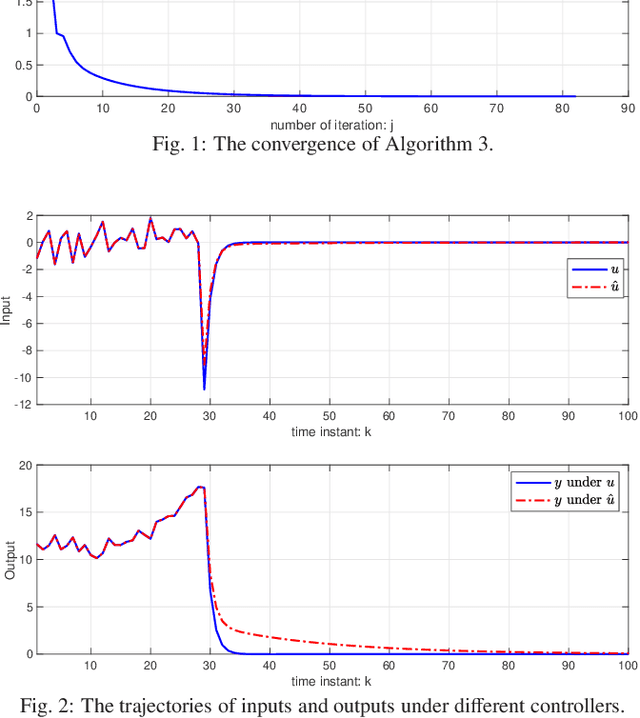
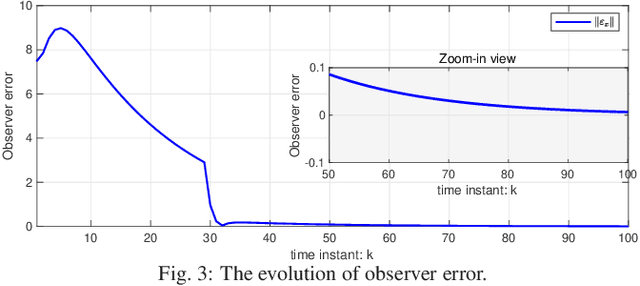
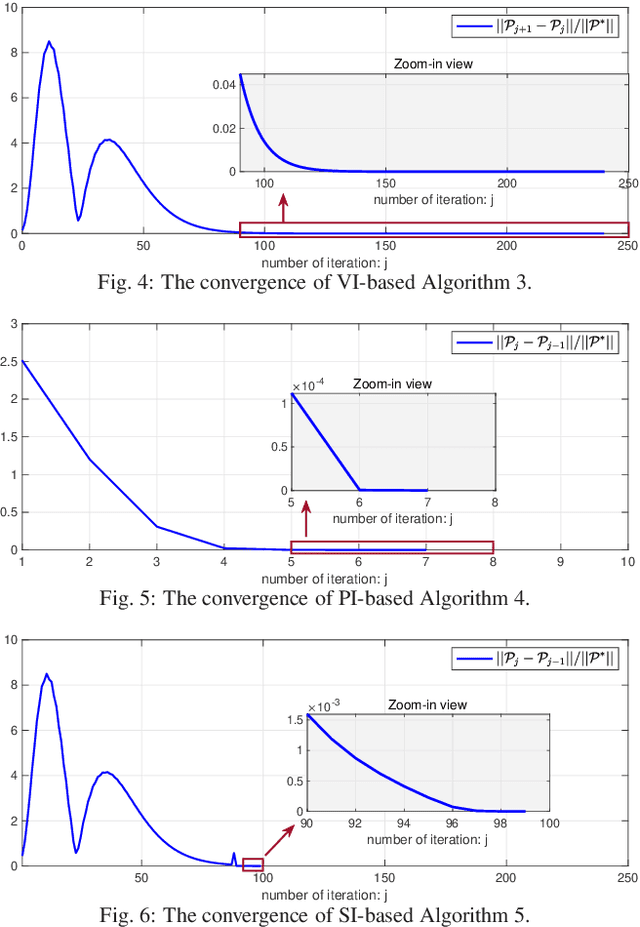
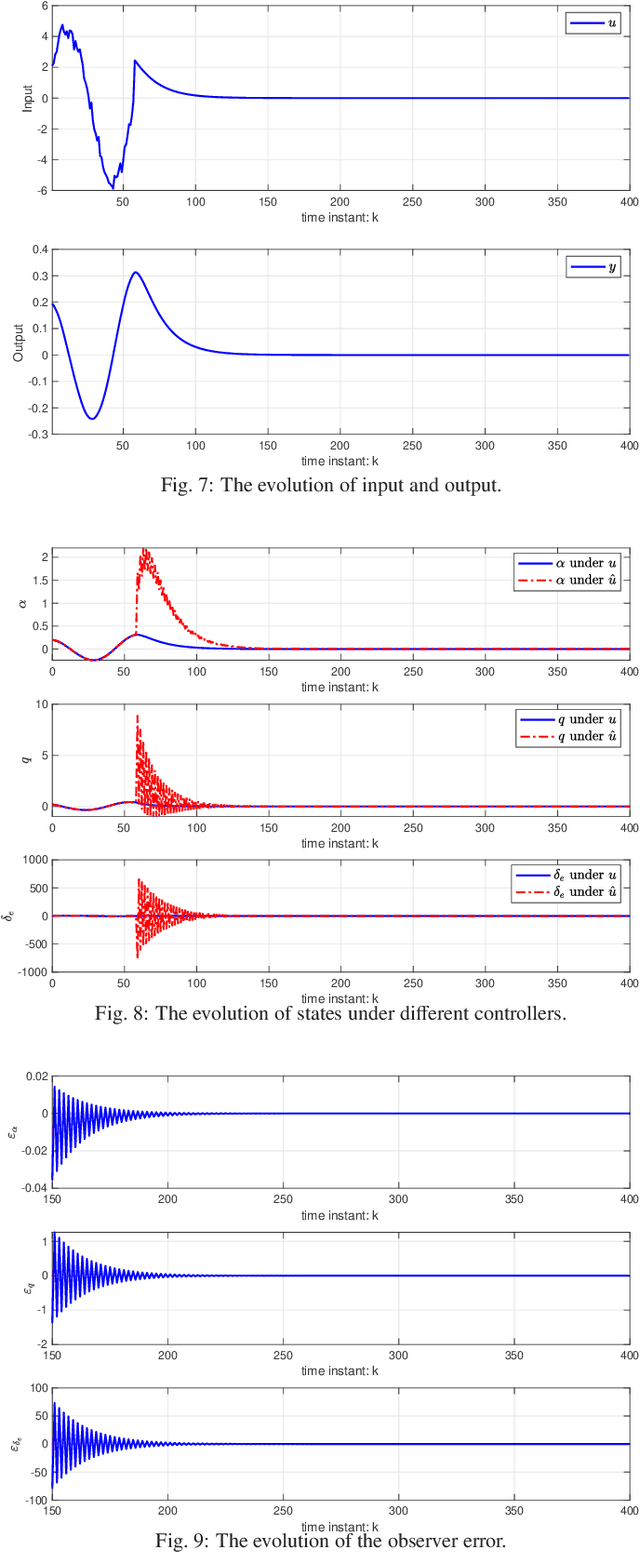
This paper studies the linear quadratic regulation (LQR) problem of unknown discrete-time systems via dynamic output feedback learning control. In contrast to the state feedback, the optimality of the dynamic output feedback control for solving the LQR problem requires an implicit condition on the convergence of the state observer. Moreover, due to unknown system matrices and the existence of observer error, it is difficult to analyze the convergence and stability of most existing output feedback learning-based control methods. To tackle these issues, we propose a generalized dynamic output feedback learning control approach with guaranteed convergence, stability, and optimality performance for solving the LQR problem of unknown discrete-time linear systems. In particular, a dynamic output feedback controller is designed to be equivalent to a state feedback controller. This equivalence relationship is an inherent property without requiring convergence of the estimated state by the state observer, which plays a key role in establishing the off-policy learning control approaches. By value iteration and policy iteration schemes, the adaptive dynamic programming based learning control approaches are developed to estimate the optimal feedback control gain. In addition, a model-free stability criterion is provided by finding a nonsingular parameterization matrix, which contributes to establishing a switched iteration scheme. Furthermore, the convergence, stability, and optimality analyses of the proposed output feedback learning control approaches are given. Finally, the theoretical results are validated by two numerical examples.
Deficient Excitation in Parameter Learning
Mar 04, 2025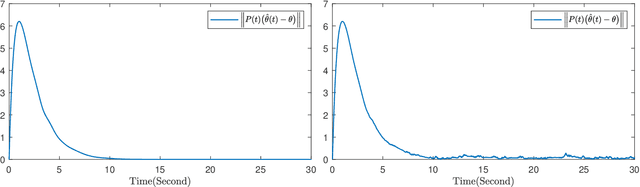
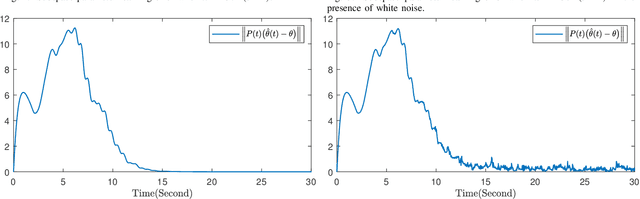
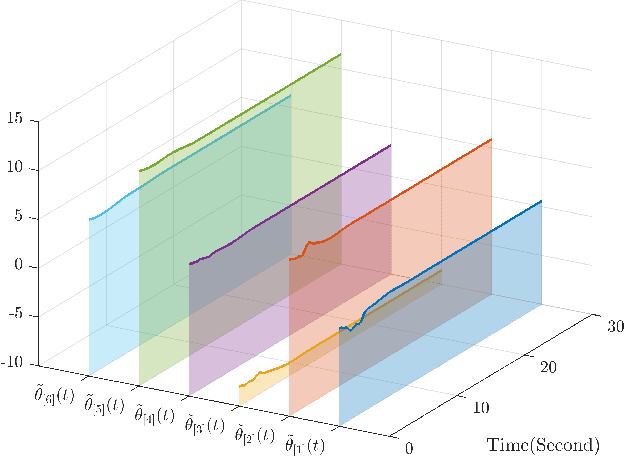
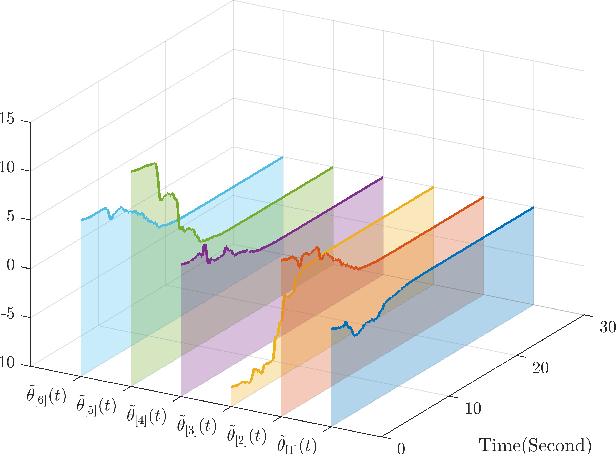
This paper investigates parameter learning problems under deficient excitation (DE). The DE condition is a rank-deficient, and therefore, a more general evolution of the well-known persistent excitation condition. Under the DE condition, a proposed online algorithm is able to calculate the identifiable and non-identifiable subspaces, and finally give an optimal parameter estimate in the sense of least squares. In particular, the learning error within the identifiable subspace exponentially converges to zero in the noise-free case, even without persistent excitation. The DE condition also provides a new perspective for solving distributed parameter learning problems, where the challenge is posed by local regressors that are often insufficiently excited. To improve knowledge of the unknown parameters, a cooperative learning protocol is proposed for a group of estimators that collect measured information under complementary DE conditions. This protocol allows each local estimator to operate locally in its identifiable subspace, and reach a consensus with neighbours in its non-identifiable subspace. As a result, the task of estimating unknown parameters can be achieved in a distributed way using cooperative local estimators. Application examples in system identification are given to demonstrate the effectiveness of the theoretical results developed in this paper.
Learning-Enhanced Safeguard Control for High-Relative-Degree Systems: Robust Optimization under Disturbances and Faults
Jan 26, 2025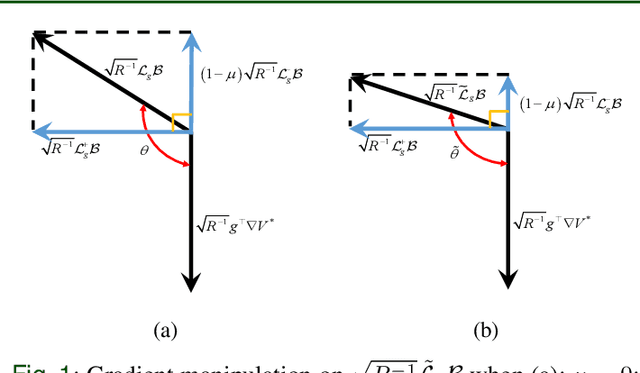
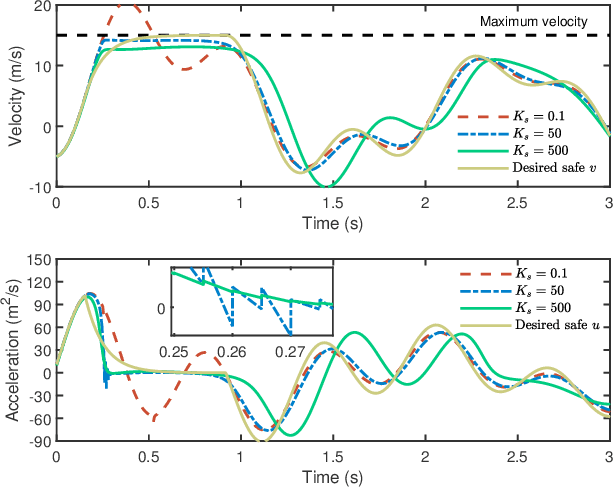
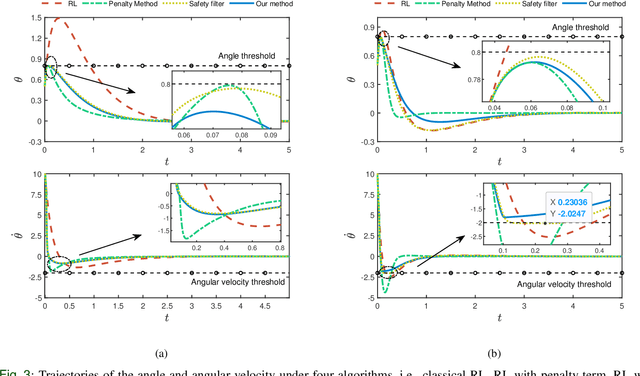
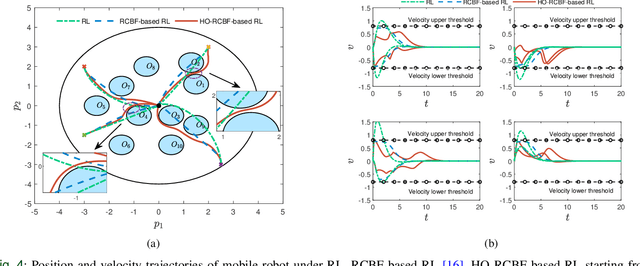
Merely pursuing performance may adversely affect the safety, while a conservative policy for safe exploration will degrade the performance. How to balance the safety and performance in learning-based control problems is an interesting yet challenging issue. This paper aims to enhance system performance with safety guarantee in solving the reinforcement learning (RL)-based optimal control problems of nonlinear systems subject to high-relative-degree state constraints and unknown time-varying disturbance/actuator faults. First, to combine control barrier functions (CBFs) with RL, a new type of CBFs, termed high-order reciprocal control barrier function (HO-RCBF) is proposed to deal with high-relative-degree constraints during the learning process. Then, the concept of gradient similarity is proposed to quantify the relationship between the gradient of safety and the gradient of performance. Finally, gradient manipulation and adaptive mechanisms are introduced in the safe RL framework to enhance the performance with a safety guarantee. Two simulation examples illustrate that the proposed safe RL framework can address high-relative-degree constraint, enhance safety robustness and improve system performance.
Generalized Pose Space Embeddings for Training In-the-Wild using Anaylis-by-Synthesis
Nov 13, 2024



Modern pose estimation models are trained on large, manually-labelled datasets which are costly and may not cover the full extent of human poses and appearances in the real world. With advances in neural rendering, analysis-by-synthesis and the ability to not only predict, but also render the pose, is becoming an appealing framework, which could alleviate the need for large scale manual labelling efforts. While recent work have shown the feasibility of this approach, the predictions admit many flips due to a simplistic intermediate skeleton representation, resulting in low precision and inhibiting the acquisition of any downstream knowledge such as three-dimensional positioning. We solve this problem with a more expressive intermediate skeleton representation capable of capturing the semantics of the pose (left and right), which significantly reduces flips. To successfully train this new representation, we extend the analysis-by-synthesis framework with a training protocol based on synthetic data. We show that our representation results in less flips and more accurate predictions. Our approach outperforms previous models trained with analysis-by-synthesis on standard benchmarks.
Nonlinear Bipartite Output Regulation with Application to Turing Pattern
May 25, 2023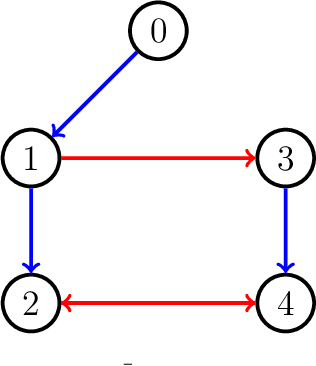
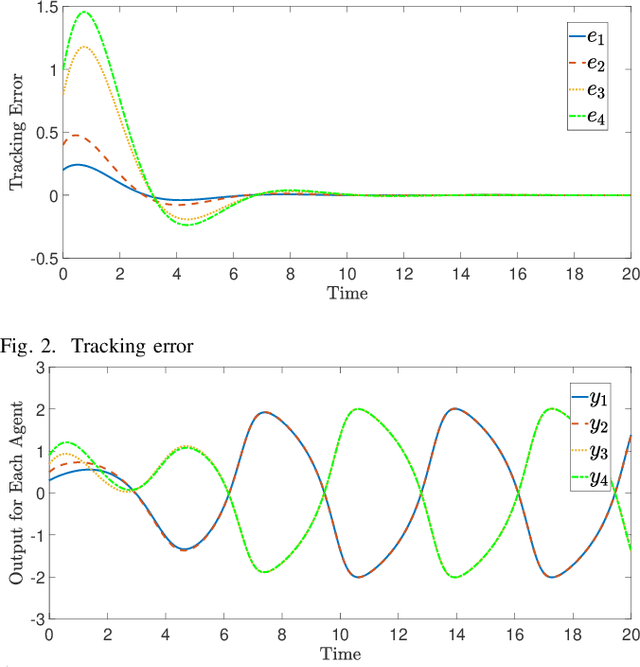
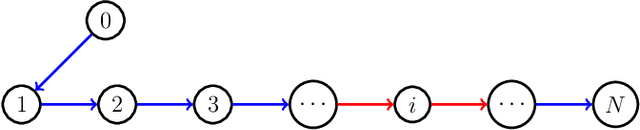

In this paper, a bipartite output regulation problem is solved for a class of nonlinear multi-agent systems subject to static signed communication networks. A nonlinear distributed observer is proposed for a nonlinear exosystem with cooperation-competition interactions to address the problem. Sufficient conditions are provided to guarantee its existence and stability. The exponential stability of the observer is established. As a practical application, a leader-following bipartite consensus problem is solved for a class of nonlinear multi-agent systems based on the observer. Finally, a network of multiple pendulum systems is treated to support the feasibility of the proposed design. The possible application of the approach to generate specific Turing patterns is also presented.