 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonadaptive Output Regulation of Second-Order Nonlinear Uncertain Systems
May 28, 2025This paper investigates the robust output regulation problem of second-order nonlinear uncertain systems with an unknown exosystem. Instead of the adaptive control approach, this paper resorts to a robust control methodology to solve the problem and thus avoid the bursting phenomenon. In particular, this paper constructs generic internal models for the steady-state state and input variables of the system. By introducing a coordinate transformation, this paper converts the robust output regulation problem into a nonadaptive stabilization problem of an augmented system composed of the second-order nonlinear uncertain system and the generic internal models. Then, we design the stabilization control law and construct a strict Lyapunov function that guarantees the robustness with respect to unmodeled disturbances. The analysis shows that the output zeroing manifold of the augmented system can be made attractive by the proposed nonadaptive control law, which solves the robust output regulation problem. Finally, we demonstrate the effectiveness of the proposed nonadaptive internal model approach by its application to the control of the Duffing system.
Optimal Output Feedback Learning Control for Discrete-Time Linear Quadratic Regulation
Mar 08, 2025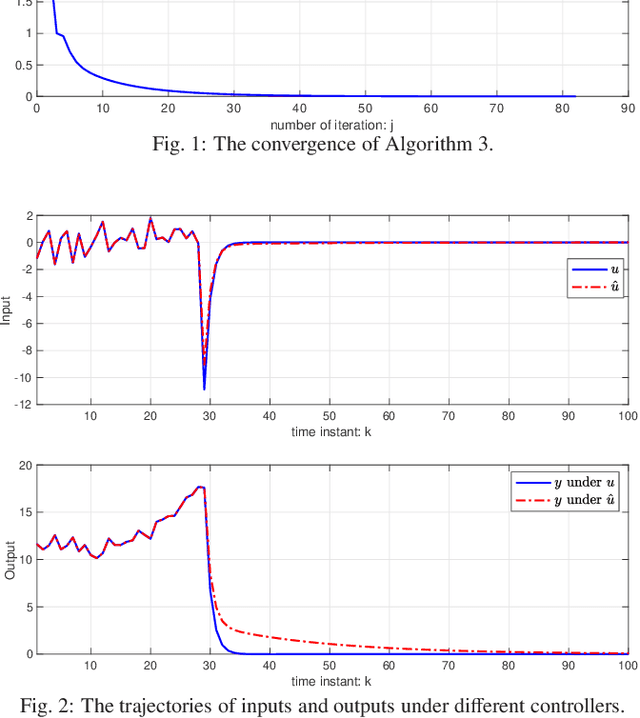
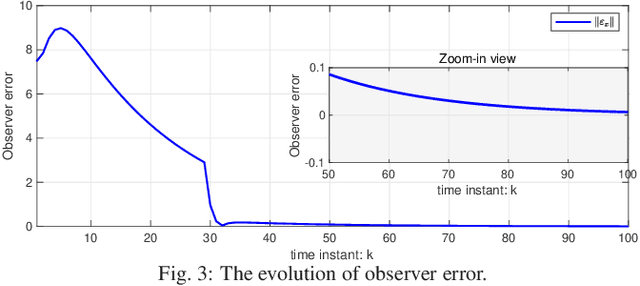
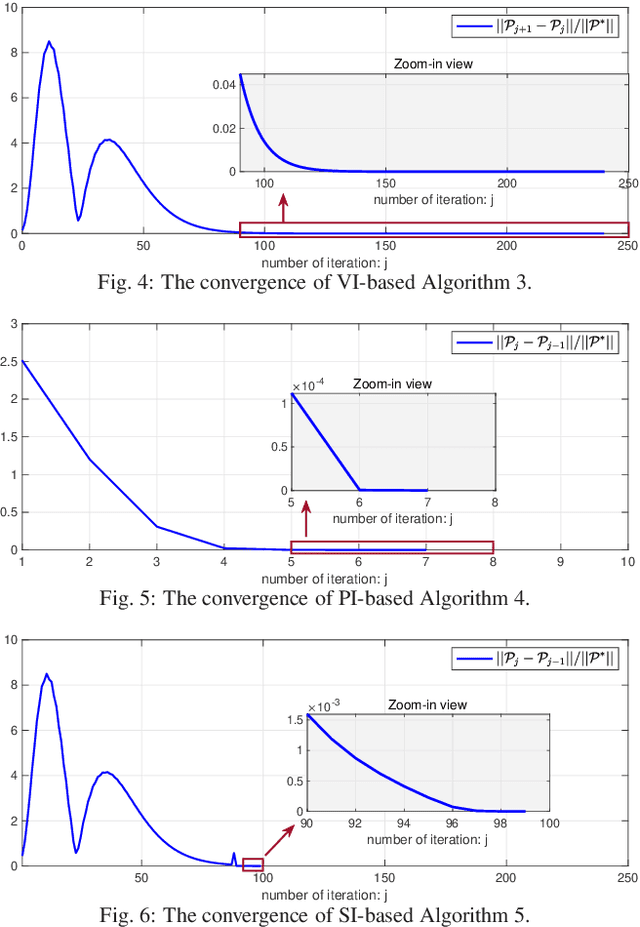
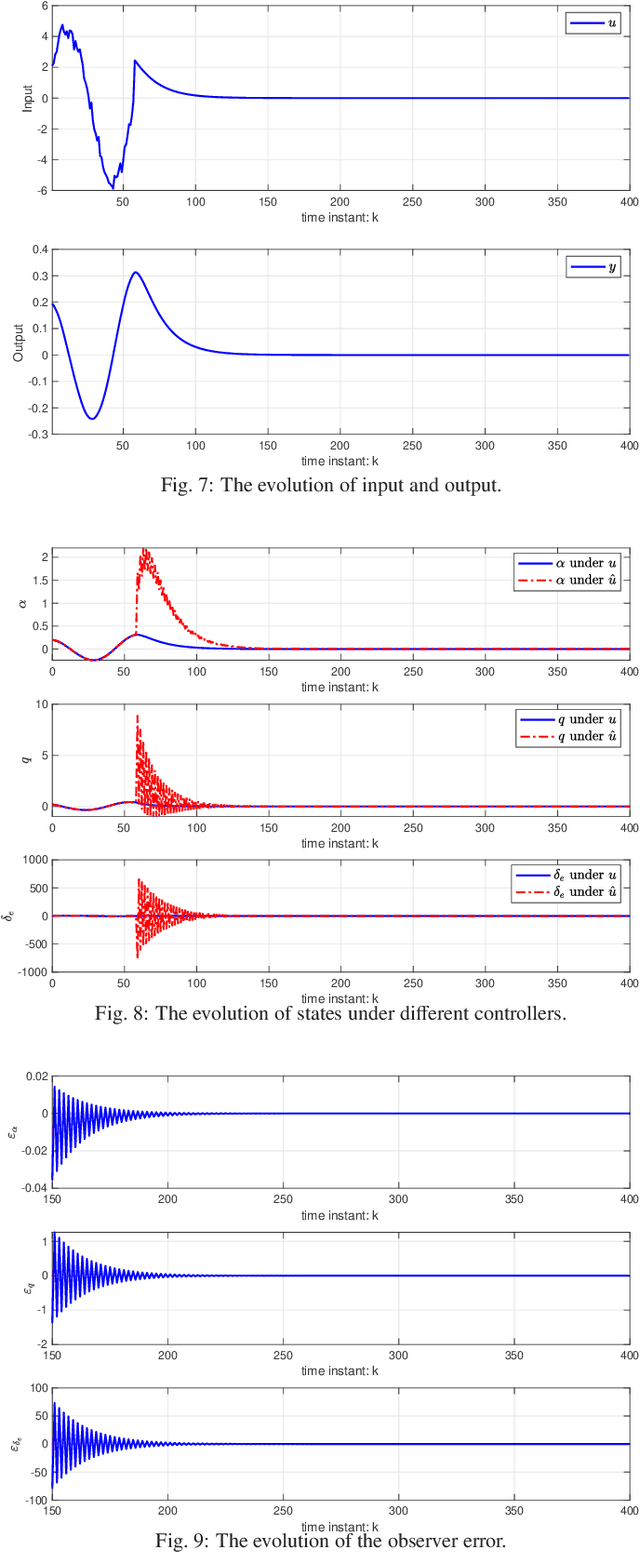
This paper studies the linear quadratic regulation (LQR) problem of unknown discrete-time systems via dynamic output feedback learning control. In contrast to the state feedback, the optimality of the dynamic output feedback control for solving the LQR problem requires an implicit condition on the convergence of the state observer. Moreover, due to unknown system matrices and the existence of observer error, it is difficult to analyze the convergence and stability of most existing output feedback learning-based control methods. To tackle these issues, we propose a generalized dynamic output feedback learning control approach with guaranteed convergence, stability, and optimality performance for solving the LQR problem of unknown discrete-time linear systems. In particular, a dynamic output feedback controller is designed to be equivalent to a state feedback controller. This equivalence relationship is an inherent property without requiring convergence of the estimated state by the state observer, which plays a key role in establishing the off-policy learning control approaches. By value iteration and policy iteration schemes, the adaptive dynamic programming based learning control approaches are developed to estimate the optimal feedback control gain. In addition, a model-free stability criterion is provided by finding a nonsingular parameterization matrix, which contributes to establishing a switched iteration scheme. Furthermore, the convergence, stability, and optimality analyses of the proposed output feedback learning control approaches are given. Finally, the theoretical results are validated by two numerical examples.