 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFRNet: Cycle-Consistent Fixed-Point Training for Real-Time Blind Face Restoration on Consumer Embedded NPUs
Jun 05, 2026Blind face restoration on consumer devices has to balance image quality against speed and memory. Strong methods such as GFPGAN and CodeFormer give good perceptual quality, but they rely on large pretrained generative priors and on operators such as attention, codebook lookup, and style modulation that are hard to compile and quantize on the small neural processing units (NPUs) used in consumer hardware. Small convolutional restorers run fast enough, but they tend to over-smooth and to leave artifacts around the eyes, nose, and mouth. We present CFRNet, a 2.0,M-parameter ResNet-style restorer for on-device use at $256\times256$, the common face-crop size on consumer NPUs. The main idea is Cycle-Consistent Fixed-Point Training (CCFP). Instead of training the network for one pass and then running it several times by hand, we train it to act as a fixed-point operator, so that applying it again to a restored face does not change the face. CCFP uses three training losses, namely progressive multi-cycle supervision, an idempotence loss, and a re-degradation cycle loss, and it adds no cost at inference. To compare fairly under our deployment limits, we retrain all baselines from scratch at the same $256\times256$ resolution. On a 300-image test set, CFRNet reaches the best perceptual score (LPIPS 0.250 at three cycles, which is 31% lower than one cycle) and also the best PSNR and SSIM at two cycles. It runs in about 23,ms per cycle in INT8 on a HiSilicon Hi3402 NPU, while the same baselines cannot be compiled to that chip. The cycle count $k$ acts as a simple quality knob that needs no retraining: PSNR is best at $k\!=\!2$ and LPIPS keeps improving up to $k\!=\!3$. We further show that the same idea works with a plain CNN that is even easier to deploy, and we run the model in real time on an in-car driver-monitoring board.
MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
May 29, 2026Multimodal Large Language Models (MLLMs) have demonstrated significant achievements in general visual question answering (VQA) tasks. However, they remain brittle on mechanical engineering drawings, where high annotation density and weak domain knowledge, compounded by unreliable spatial relation reasoning under strict projection rules and geometric constraints, make decisive cues easy to miss and frequently lead to wrong answers. To bridge this gap, we introduce the first comprehensive mechanical drawing understanding dataset, MechVQA, created through a semi-automated construction and quality-control pipeline. MechVQA contains 3.3k high-density pictures with 21K question-answer pairs, spanning 10 different fine-grained tasks across three capability levels: Recognition, Reasoning, and Judging, providing a testbed to evaluate and improve MLLM understanding on real-world mechanical drawings. On top of MechVQA, we then develop the MechVL model through a multi-stage training paradigm, building a strong domain-specialized baseline. Extensive experimental results demonstrate that MechVL outperforms the strongest closed-source baseline by 7.57 percentage points on the MechVQA total score, significantly enhancing mechanical drawing understanding ability and providing a reusable foundation for deploying MLLMs in mechanical design and inspection scenarios.
ASTRA-QA: A Benchmark for Abstract Question Answering over Documents
May 11, 2026Document-based question answering (QA) increasingly includes abstract questions that require synthesizing scattered information from long documents or across multiple documents into coherent answers. However, this setting is still poorly supported by existing benchmarks and evaluation methods, which often lack stable abstract references or rely on coarse similarity metrics and unstable head-to-head comparisons. To alleviate this issue, we introduce ASTRA-QA, a benchmark for AbSTRAct Question Answering over documents. ASTRA-QA contains 869 QA instances over academic papers and news documents, covering five abstract question types and three controlled retrieval scopes. Each instance is equipped with explicit evaluation annotations, including answer topic sets, curated unsupported topics, and aligned evidence. Building on these annotations, ASTRA-QA assesses whether answers cover required key points and avoid unsupported content by directly scoring topic coverage and curated unsupported content, enabling scalable evaluation without exhaustive head-to-head comparisons. Experiments with representative Retrieval-Augmented Generation (RAG) methods spanning vanilla, graph-based, and hierarchical retrieval settings show that ASTRA-QA provides reference-grounded diagnostics for coverage, hallucination, and retrieval-scope robustness. Our dataset and code are available at https://xinyangsally.github.io/astra-benchmark.
HaS: Accelerating RAG through Homology-Aware Speculative Retrieval
Apr 22, 2026Retrieval-Augmented Generation (RAG) expands the knowledge boundary of large language models (LLMs) at inference by retrieving external documents as context. However, retrieval becomes increasingly time-consuming as the knowledge databases grow in size. Existing acceleration strategies either compromise accuracy through approximate retrieval, or achieve marginal gains by reusing results of strictly identical queries. We propose HaS, a homology-aware speculative retrieval framework that performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains. Extensive experiments demonstrate that HaS reduces retrieval latency by 23.74% and 36.99% across datasets with only a 1-2% marginal accuracy drop. As a plug-and-play solution, HaS also significantly accelerates complex multi-hop queries in modern agentic RAG pipelines. Source code is available at: https://github.com/ErrEqualsNil/HaS.
Transcending Classical Neural Network Boundaries: A Quantum-Classical Synergistic Paradigm for Seismic Data Processing
Mar 25, 2026In recent years, a number of neural-network (NN) methods have exhibited good performance in seismic data processing, such as denoising, interpolation, and frequency-band extension. However, these methods rely on stacked perceptrons and standard activation functions, which imposes a bottleneck on the representational capacity of deep-learning models, making it difficult to capture the complex and non-stationary dynamics of seismic wavefields. Different from the classical perceptron-stacked NNs which are fundamentally confined to real-valued Euclidean spaces, the quantum NNs leverage the exponential state space of quantum mechanics to map the features into high-dimensional Hilbert spaces, transcending the representational boundary of classical NNs. Based on this insight, we propose a quantum-classical synergistic generative adversarial network (QC-GAN) for seismic data processing, serving as the first application of quantum NNs in seismic exploration. In QC-GAN, a quantum pathway is used to exploit the high-order feature correlations, while the convolutional pathway specializes in extracting the waveform structures of seismic wavefields. Furthermore, we design a QC feature complementarity loss to enforce the feature orthogonality in the proposed QC-GAN. This novel loss function can ensure that the two pathways encode non-overlapping information to enrich the capacity of feature representation. On the whole, by synergistically integrating the quantum and convolutional pathways, the proposed QC-GAN breaks the representational bottleneck inherent in classical GAN. Experimental results on denoising and interpolation tasks demonstrate that QC-GAN preserves wavefield continuity and amplitude-phase information under complex noise conditions.
Unifying Language-Action Understanding and Generation for Autonomous Driving
Mar 02, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for end-to-end autonomous driving, valued for their potential to leverage world knowledge and reason about complex driving scenes. However, existing methods suffer from two critical limitations: a persistent misalignment between language instructions and action outputs, and the inherent inefficiency of typical auto-regressive action generation. In this paper, we introduce LinkVLA, a novel architecture that directly addresses these challenges to enhance both alignment and efficiency. First, we establish a structural link by unifying language and action tokens into a shared discrete codebook, processed within a single multi-modal model. This structurally enforces cross-modal consistency from the ground up. Second, to create a deep semantic link, we introduce an auxiliary action understanding objective that trains the model to generate descriptive captions from trajectories, fostering a bidirectional language-action mapping. Finally, we replace the slow, step-by-step generation with a two-step coarse-to-fine generation method C2F that efficiently decodes the action sequence, saving 86% inference time. Experiments on closed-loop driving benchmarks show consistent gains in instruction following accuracy and driving performance, alongside reduced inference latency.
A Consistency-Improved LiDAR-Inertial Bundle Adjustment
Feb 06, 2026Simultaneous Localization and Mapping (SLAM) using 3D LiDAR has emerged as a cornerstone for autonomous navigation in robotics. While feature-based SLAM systems have achieved impressive results by leveraging edge and planar structures, they often suffer from the inconsistent estimator associated with feature parameterization and estimated covariance. In this work, we present a consistency-improved LiDAR-inertial bundle adjustment (BA) with tailored parameterization and estimator. First, we propose a stereographic-projection representation parameterizing the planar and edge features, and conduct a comprehensive observability analysis to support its integrability with consistent estimator. Second, we implement a LiDAR-inertial BA with Maximum a Posteriori (MAP) formulation and First-Estimate Jacobians (FEJ) to preserve the accurate estimated covariance and observability properties of the system. Last, we apply our proposed BA method to a LiDAR-inertial odometry.
Learning-Enhanced Safeguard Control for High-Relative-Degree Systems: Robust Optimization under Disturbances and Faults
Jan 26, 2025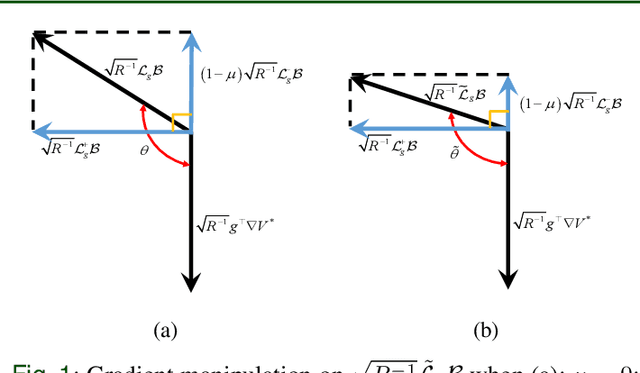
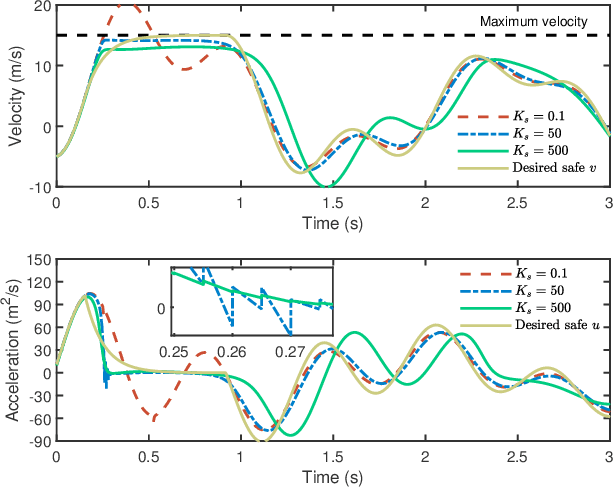
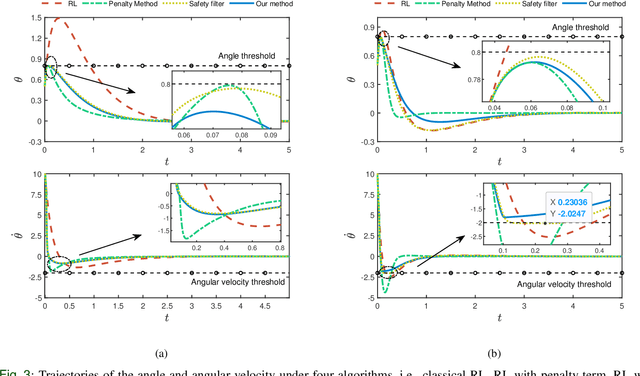
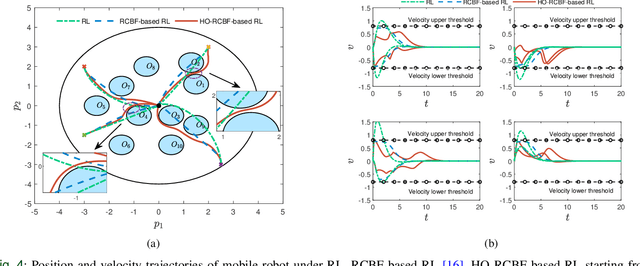
Merely pursuing performance may adversely affect the safety, while a conservative policy for safe exploration will degrade the performance. How to balance the safety and performance in learning-based control problems is an interesting yet challenging issue. This paper aims to enhance system performance with safety guarantee in solving the reinforcement learning (RL)-based optimal control problems of nonlinear systems subject to high-relative-degree state constraints and unknown time-varying disturbance/actuator faults. First, to combine control barrier functions (CBFs) with RL, a new type of CBFs, termed high-order reciprocal control barrier function (HO-RCBF) is proposed to deal with high-relative-degree constraints during the learning process. Then, the concept of gradient similarity is proposed to quantify the relationship between the gradient of safety and the gradient of performance. Finally, gradient manipulation and adaptive mechanisms are introduced in the safe RL framework to enhance the performance with a safety guarantee. Two simulation examples illustrate that the proposed safe RL framework can address high-relative-degree constraint, enhance safety robustness and improve system performance.
From Twitter to Reasoner: Understand Mobility Travel Modes and Sentiment Using Large Language Models
Nov 04, 2024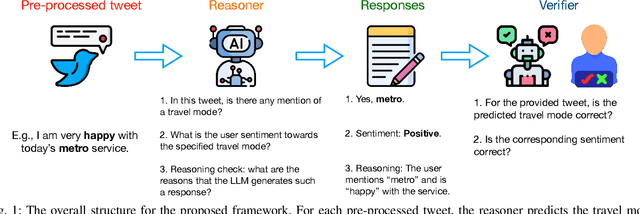
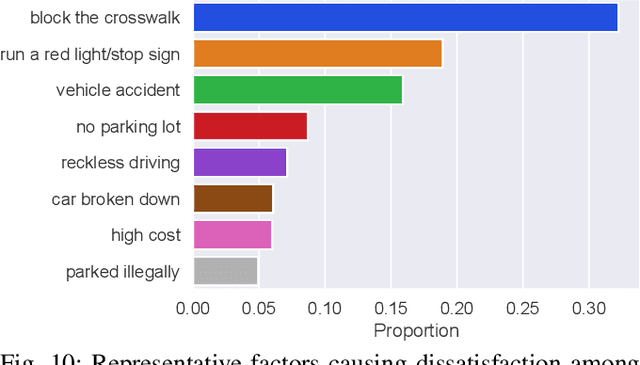
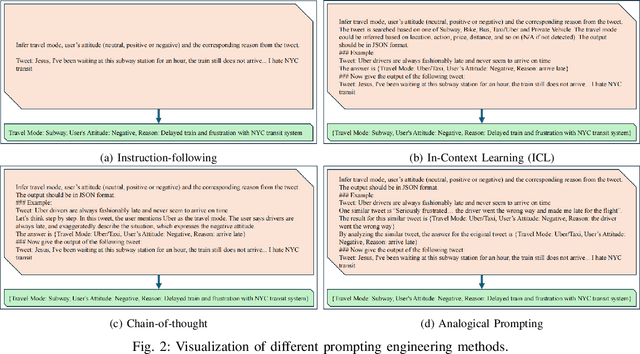

Social media has become an important platform for people to express their opinions towards transportation services and infrastructure, which holds the potential for researchers to gain a deeper understanding of individuals' travel choices, for transportation operators to improve service quality, and for policymakers to regulate mobility services. A significant challenge, however, lies in the unstructured nature of social media data. In other words, textual data like social media is not labeled, and large-scale manual annotations are cost-prohibitive. In this study, we introduce a novel methodological framework utilizing Large Language Models (LLMs) to infer the mentioned travel modes from social media posts, and reason people's attitudes toward the associated travel mode, without the need for manual annotation. We compare different LLMs along with various prompting engineering methods in light of human assessment and LLM verification. We find that most social media posts manifest negative rather than positive sentiments. We thus identify the contributing factors to these negative posts and, accordingly, propose recommendations to traffic operators and policymakers.
MePT: Multi-Representation Guided Prompt Tuning for Vision-Language Model
Aug 19, 2024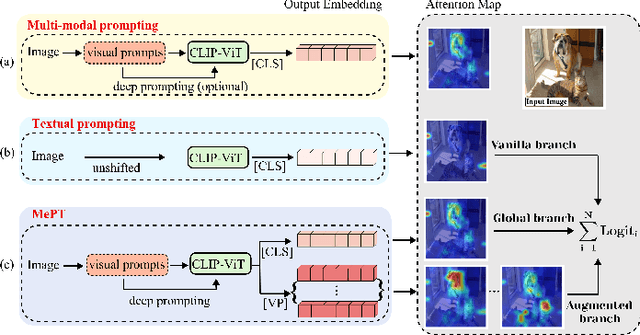
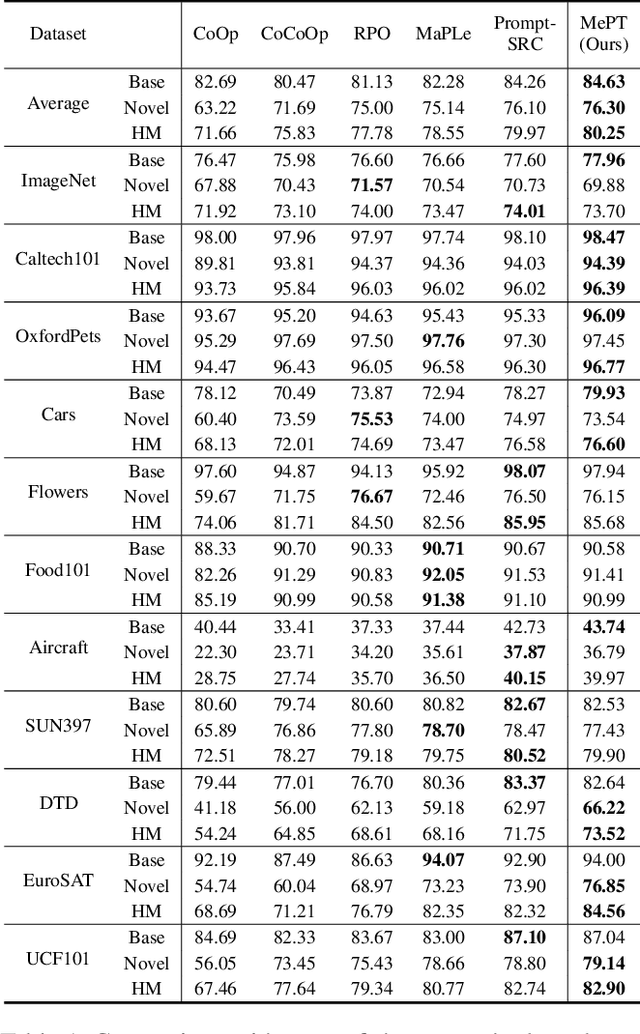
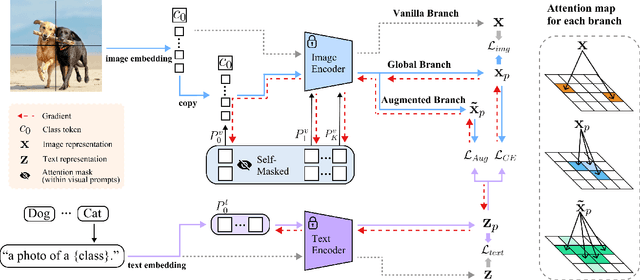
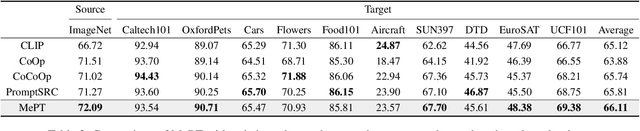
Recent advancements in pre-trained Vision-Language Models (VLMs) have highlighted the significant potential of prompt tuning for adapting these models to a wide range of downstream tasks. However, existing prompt tuning methods typically map an image to a single representation, limiting the model's ability to capture the diverse ways an image can be described. To address this limitation, we investigate the impact of visual prompts on the model's generalization capability and introduce a novel method termed Multi-Representation Guided Prompt Tuning (MePT). Specifically, MePT employs a three-branch framework that focuses on diverse salient regions, uncovering the inherent knowledge within images which is crucial for robust generalization. Further, we employ efficient self-ensemble techniques to integrate these versatile image representations, allowing MePT to learn all conditional, marginal, and fine-grained distributions effectively. We validate the effectiveness of MePT through extensive experiments, demonstrating significant improvements on both base-to-novel class prediction and domain generalization tasks.