 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
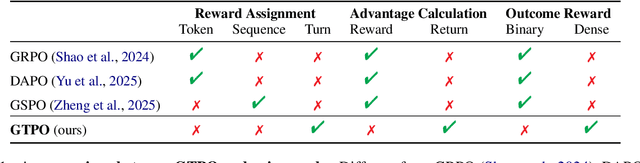
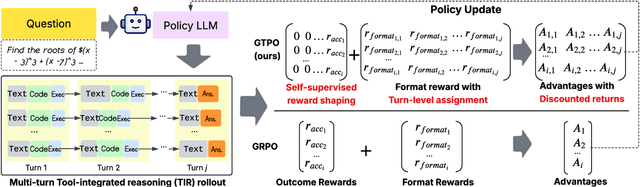
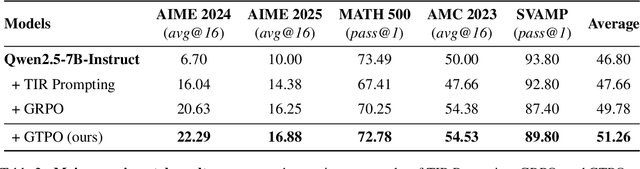
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
From Twitter to Reasoner: Understand Mobility Travel Modes and Sentiment Using Large Language Models
Nov 04, 2024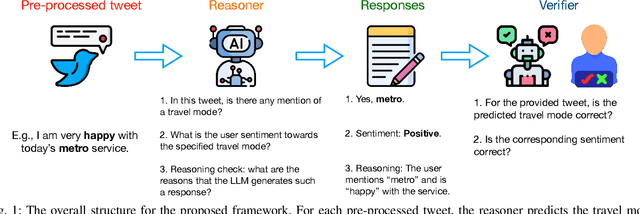
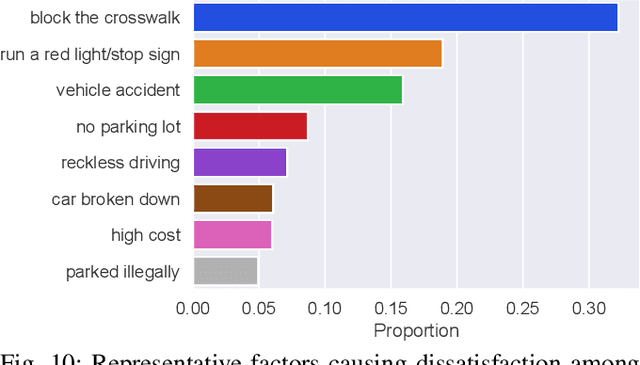
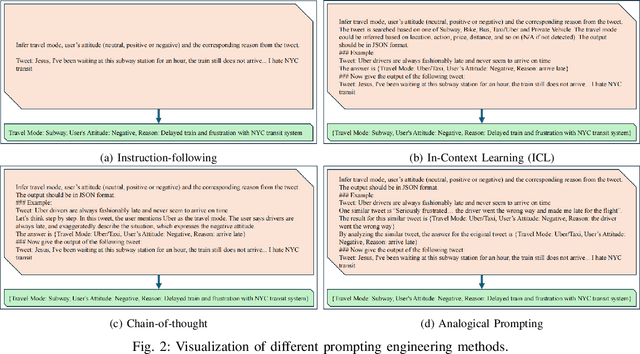

Social media has become an important platform for people to express their opinions towards transportation services and infrastructure, which holds the potential for researchers to gain a deeper understanding of individuals' travel choices, for transportation operators to improve service quality, and for policymakers to regulate mobility services. A significant challenge, however, lies in the unstructured nature of social media data. In other words, textual data like social media is not labeled, and large-scale manual annotations are cost-prohibitive. In this study, we introduce a novel methodological framework utilizing Large Language Models (LLMs) to infer the mentioned travel modes from social media posts, and reason people's attitudes toward the associated travel mode, without the need for manual annotation. We compare different LLMs along with various prompting engineering methods in light of human assessment and LLM verification. We find that most social media posts manifest negative rather than positive sentiments. We thus identify the contributing factors to these negative posts and, accordingly, propose recommendations to traffic operators and policymakers.
R-LLaVA: Improving Med-VQA Understanding through Visual Region of Interest
Oct 27, 2024



Artificial intelligence has made significant strides in medical visual question answering (Med-VQA), yet prevalent studies often interpret images holistically, overlooking the visual regions of interest that may contain crucial information, potentially aligning with a doctor's prior knowledge that can be incorporated with minimal annotations (e.g., bounding boxes). To address this gap, this paper introduces R-LLaVA, designed to enhance biomedical VQA understanding by integrating simple medical annotations as prior knowledge directly into the image space through CLIP. These annotated visual regions of interest are then fed into the LLaVA model during training, aiming to enrich the model's understanding of biomedical queries. Experimental evaluation on four standard Med-VQA datasets demonstrates R-LLaVA's superiority over existing state-of-the-art (SoTA) methods. Additionally, to verify the model's capability in visual comprehension, a novel multiple-choice medical visual understanding dataset is introduced, confirming the positive impact of focusing on visual regions of interest in advancing biomedical VQA understanding.