 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSPECT: Invariant Spectral Features Preservation of Diffusion Models
Dec 19, 2025Modern diffusion models (DMs) have achieved state-of-the-art image generation. However, the fundamental design choice of diffusing data all the way to white noise and then reconstructing it leads to an extremely difficult and computationally intractable prediction task. To overcome this limitation, we propose InSPECT (Invariant Spectral Feature-Preserving Diffusion Model), a novel diffusion model that keeps invariant spectral features during both the forward and backward processes. At the end of the forward process, the Fourier coefficients smoothly converge to a specified random noise, enabling features preservation while maintaining diversity and randomness. By preserving invariant features, InSPECT demonstrates enhanced visual diversity, faster convergence rate, and a smoother diffusion process. Experiments on CIFAR-10, Celeb-A, and LSUN demonstrate that InSPECT achieves on average a 39.23% reduction in FID and 45.80% improvement in IS against DDPM for 10K iterations under specified parameter settings, which demonstrates the significant advantages of preserving invariant features: achieving superior generation quality and diversity, while enhancing computational efficiency and enabling faster convergence rate. To the best of our knowledge, this is the first attempt to analyze and preserve invariant spectral features in diffusion models.
LLM-based Realistic Safety-Critical Driving Video Generation
Jul 02, 2025Designing diverse and safety-critical driving scenarios is essential for evaluating autonomous driving systems. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) for few-shot code generation to automatically synthesize driving scenarios within the CARLA simulator, which has flexibility in scenario scripting, efficient code-based control of traffic participants, and enforcement of realistic physical dynamics. Given a few example prompts and code samples, the LLM generates safety-critical scenario scripts that specify the behavior and placement of traffic participants, with a particular focus on collision events. To bridge the gap between simulation and real-world appearance, we integrate a video generation pipeline using Cosmos-Transfer1 with ControlNet, which converts rendered scenes into realistic driving videos. Our approach enables controllable scenario generation and facilitates the creation of rare but critical edge cases, such as pedestrian crossings under occlusion or sudden vehicle cut-ins. Experimental results demonstrate the effectiveness of our method in generating a wide range of realistic, diverse, and safety-critical scenarios, offering a promising tool for simulation-based testing of autonomous vehicles.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Federated Hierarchical Reinforcement Learning for Adaptive Traffic Signal Control
Apr 07, 2025Multi-agent reinforcement learning (MARL) has shown promise for adaptive traffic signal control (ATSC), enabling multiple intersections to coordinate signal timings in real time. However, in large-scale settings, MARL faces constraints due to extensive data sharing and communication requirements. Federated learning (FL) mitigates these challenges by training shared models without directly exchanging raw data, yet traditional FL methods such as FedAvg struggle with highly heterogeneous intersections. Different intersections exhibit varying traffic patterns, demands, and road structures, so performing FedAvg across all agents is inefficient. To address this gap, we propose Hierarchical Federated Reinforcement Learning (HFRL) for ATSC. HFRL employs clustering-based or optimization-based techniques to dynamically group intersections and perform FedAvg independently within groups of intersections with similar characteristics, enabling more effective coordination and scalability than standard FedAvg. Our experiments on synthetic and real-world traffic networks demonstrate that HFRL not only outperforms both decentralized and standard federated RL approaches but also identifies suitable grouping patterns based on network structure or traffic demand, resulting in a more robust framework for distributed, heterogeneous systems.
SafeAug: Safety-Critical Driving Data Augmentation from Naturalistic Datasets
Jan 03, 2025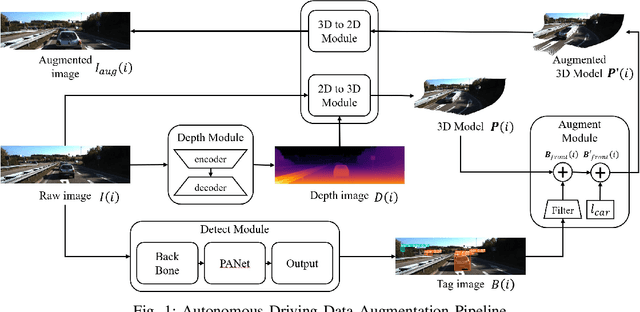

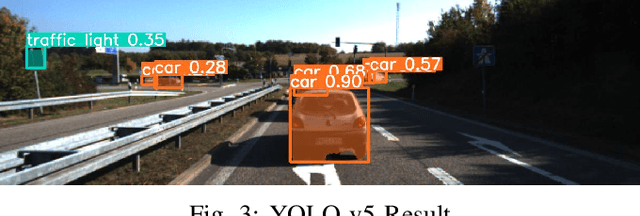

Safety-critical driving data is crucial for developing safe and trustworthy self-driving algorithms. Due to the scarcity of safety-critical data in naturalistic datasets, current approaches primarily utilize simulated or artificially generated images. However, there remains a gap in authenticity between these generated images and naturalistic ones. We propose a novel framework to augment the safety-critical driving data from the naturalistic dataset to address this issue. In this framework, we first detect vehicles using YOLOv5, followed by depth estimation and 3D transformation to simulate vehicle proximity and critical driving scenarios better. This allows for targeted modification of vehicle dynamics data to reflect potentially hazardous situations. Compared to the simulated or artificially generated data, our augmentation methods can generate safety-critical driving data with minimal compromise on image authenticity. Experiments using KITTI datasets demonstrate that a downstream self-driving algorithm trained on this augmented dataset performs superiorly compared to the baselines, which include SMOGN and importance sampling.
diffIRM: A Diffusion-Augmented Invariant Risk Minimization Framework for Spatiotemporal Prediction over Graphs
Dec 31, 2024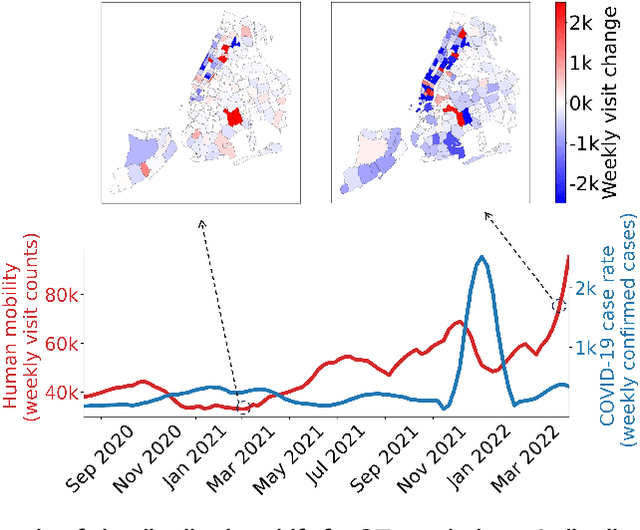

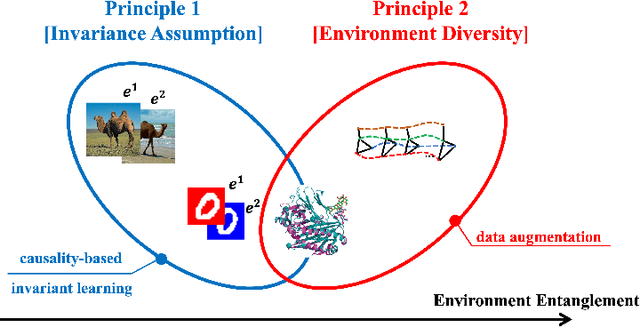
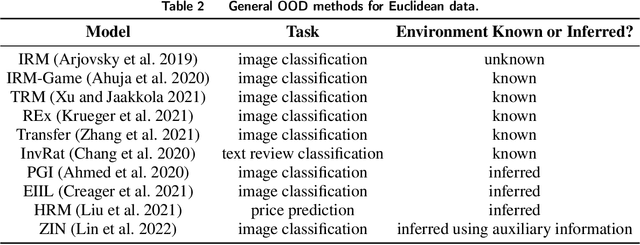
Spatiotemporal prediction over graphs (STPG) is challenging, because real-world data suffers from the Out-of-Distribution (OOD) generalization problem, where test data follow different distributions from training ones. To address this issue, Invariant Risk Minimization (IRM) has emerged as a promising approach for learning invariant representations across different environments. However, IRM and its variants are originally designed for Euclidean data like images, and may not generalize well to graph-structure data such as spatiotemporal graphs due to spatial correlations in graphs. To overcome the challenge posed by graph-structure data, the existing graph OOD methods adhere to the principles of invariance existence, or environment diversity. However, there is little research that combines both principles in the STPG problem. A combination of the two is crucial for efficiently distinguishing between invariant features and spurious ones. In this study, we fill in this research gap and propose a diffusion-augmented invariant risk minimization (diffIRM) framework that combines these two principles for the STPG problem. Our diffIRM contains two processes: i) data augmentation and ii) invariant learning. In the data augmentation process, a causal mask generator identifies causal features and a graph-based diffusion model acts as an environment augmentor to generate augmented spatiotemporal graph data. In the invariant learning process, an invariance penalty is designed using the augmented data, and then serves as a regularizer for training the spatiotemporal prediction model. The real-world experiment uses three human mobility datasets, i.e. SafeGraph, PeMS04, and PeMS08. Our proposed diffIRM outperforms baselines.
Causal Adjacency Learning for Spatiotemporal Prediction Over Graphs
Nov 25, 2024



Spatiotemporal prediction over graphs (STPG) is crucial for transportation systems. In existing STPG models, an adjacency matrix is an important component that captures the relations among nodes over graphs. However, most studies calculate the adjacency matrix by directly memorizing the data, such as distance- and correlation-based matrices. These adjacency matrices do not consider potential pattern shift for the test data, and may result in suboptimal performance if the test data has a different distribution from the training one. This issue is known as the Out-of-Distribution generalization problem. To address this issue, in this paper we propose a Causal Adjacency Learning (CAL) method to discover causal relations over graphs. The learned causal adjacency matrix is evaluated on a downstream spatiotemporal prediction task using real-world graph data. Results demonstrate that our proposed adjacency matrix can capture the causal relations, and using our learned adjacency matrix can enhance prediction performance on the OOD test data, even though causal learning is not conducted in the downstream task.
From Twitter to Reasoner: Understand Mobility Travel Modes and Sentiment Using Large Language Models
Nov 04, 2024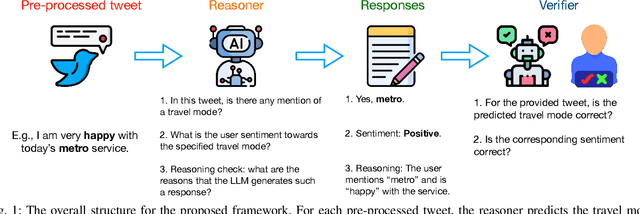
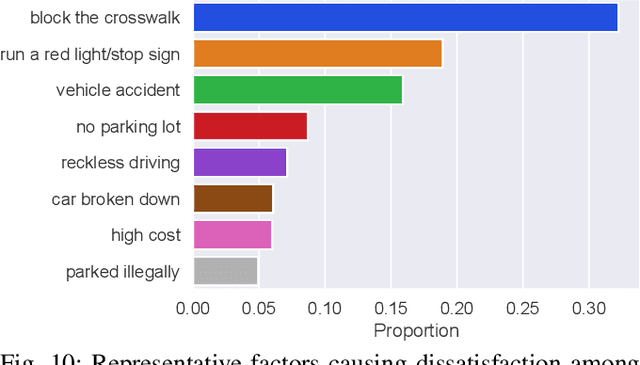
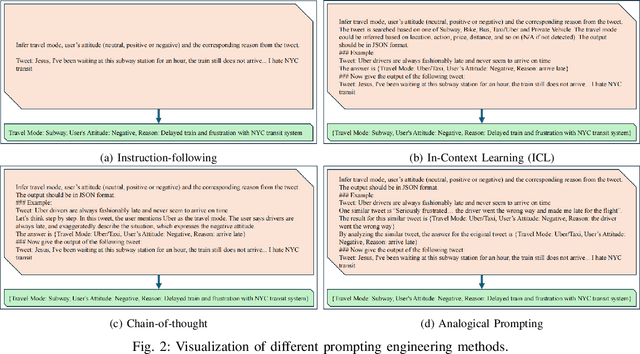

Social media has become an important platform for people to express their opinions towards transportation services and infrastructure, which holds the potential for researchers to gain a deeper understanding of individuals' travel choices, for transportation operators to improve service quality, and for policymakers to regulate mobility services. A significant challenge, however, lies in the unstructured nature of social media data. In other words, textual data like social media is not labeled, and large-scale manual annotations are cost-prohibitive. In this study, we introduce a novel methodological framework utilizing Large Language Models (LLMs) to infer the mentioned travel modes from social media posts, and reason people's attitudes toward the associated travel mode, without the need for manual annotation. We compare different LLMs along with various prompting engineering methods in light of human assessment and LLM verification. We find that most social media posts manifest negative rather than positive sentiments. We thus identify the contributing factors to these negative posts and, accordingly, propose recommendations to traffic operators and policymakers.
DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
Aug 29, 2024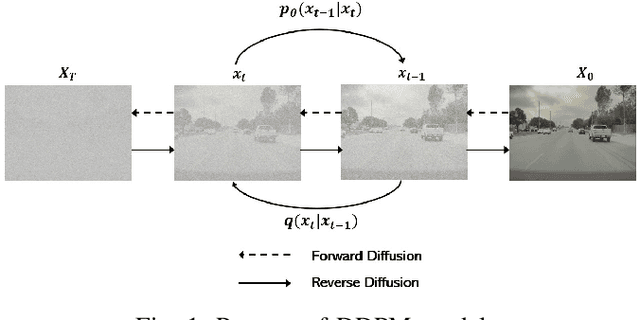
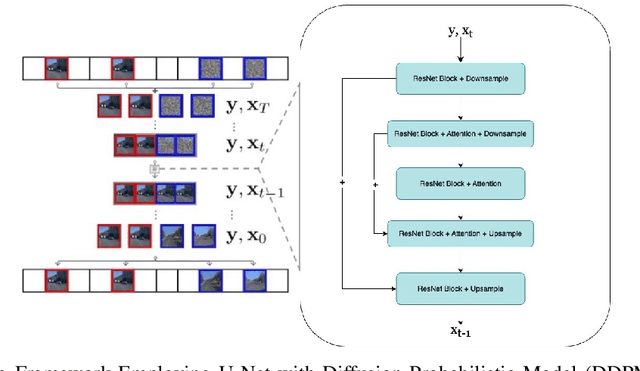
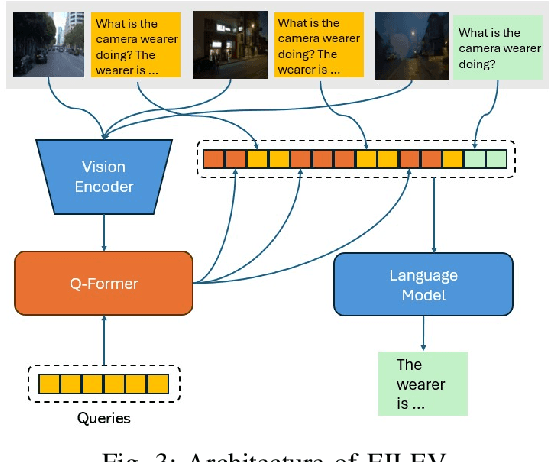

The advancement of autonomous driving technologies necessitates increasingly sophisticated methods for understanding and predicting real-world scenarios. Vision language models (VLMs) are emerging as revolutionary tools with significant potential to influence autonomous driving. In this paper, we propose the DriveGenVLM framework to generate driving videos and use VLMs to understand them. To achieve this, we employ a video generation framework grounded in denoising diffusion probabilistic models (DDPM) aimed at predicting real-world video sequences. We then explore the adequacy of our generated videos for use in VLMs by employing a pre-trained model known as Efficient In-context Learning on Egocentric Videos (EILEV). The diffusion model is trained with the Waymo open dataset and evaluated using the Fr\'echet Video Distance (FVD) score to ensure the quality and realism of the generated videos. Corresponding narrations are provided by EILEV for these generated videos, which may be beneficial in the autonomous driving domain. These narrations can enhance traffic scene understanding, aid in navigation, and improve planning capabilities. The integration of video generation with VLMs in the DriveGenVLM framework represents a significant step forward in leveraging advanced AI models to address complex challenges in autonomous driving.
GenDDS: Generating Diverse Driving Video Scenarios with Prompt-to-Video Generative Model
Aug 28, 2024

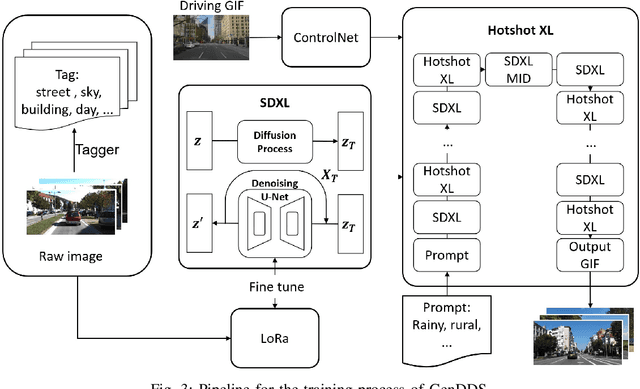

Autonomous driving training requires a diverse range of datasets encompassing various traffic conditions, weather scenarios, and road types. Traditional data augmentation methods often struggle to generate datasets that represent rare occurrences. To address this challenge, we propose GenDDS, a novel approach for generating driving scenarios generation by leveraging the capabilities of Stable Diffusion XL (SDXL), an advanced latent diffusion model. Our methodology involves the use of descriptive prompts to guide the synthesis process, aimed at producing realistic and diverse driving scenarios. With the power of the latest computer vision techniques, such as ControlNet and Hotshot-XL, we have built a complete pipeline for video generation together with SDXL. We employ the KITTI dataset, which includes real-world driving videos, to train the model. Through a series of experiments, we demonstrate that our model can generate high-quality driving videos that closely replicate the complexity and variability of real-world driving scenarios. This research contributes to the development of sophisticated training data for autonomous driving systems and opens new avenues for creating virtual environments for simulation and validation purposes.