 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenDDS: Generating Diverse Driving Video Scenarios with Prompt-to-Video Generative Model
Paper and Code
Aug 28, 2024

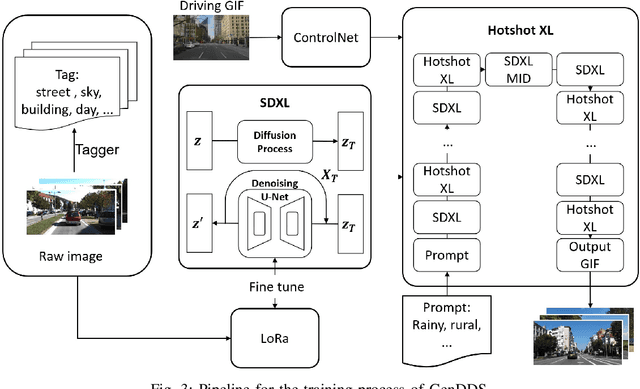

Autonomous driving training requires a diverse range of datasets encompassing various traffic conditions, weather scenarios, and road types. Traditional data augmentation methods often struggle to generate datasets that represent rare occurrences. To address this challenge, we propose GenDDS, a novel approach for generating driving scenarios generation by leveraging the capabilities of Stable Diffusion XL (SDXL), an advanced latent diffusion model. Our methodology involves the use of descriptive prompts to guide the synthesis process, aimed at producing realistic and diverse driving scenarios. With the power of the latest computer vision techniques, such as ControlNet and Hotshot-XL, we have built a complete pipeline for video generation together with SDXL. We employ the KITTI dataset, which includes real-world driving videos, to train the model. Through a series of experiments, we demonstrate that our model can generate high-quality driving videos that closely replicate the complexity and variability of real-world driving scenarios. This research contributes to the development of sophisticated training data for autonomous driving systems and opens new avenues for creating virtual environments for simulation and validation purposes.