 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Oriented Randomized Neural Networks for Poisson-Nernst-Planck and Poisson-Nernst-Planck-Navier-Stokes Systems
Jun 18, 2026We develop a structure-oriented randomized neural network framework, termed SO-RaNN, for the Poisson-Nernst-Planck (PNP) system and the Poisson-Nernst-Planck-Navier-Stokes (PNP-NS) system. The decoupled linearized subproblems are solved iteratively by randomized neural networks in a space-time framework. For the concentration variables, a pointwise cut-off is used to enforce positivity at the value level, and discrete mass-scaling factors are computed at selected correction instants and interpolated in time, so as to ensure exact mass matching at those instants and to promote approximate mass preservation between them. To introduce an auxiliary discrete dissipation mechanism, we further employ an SAV-type post-processing correction, which yields monotonicity of the SAV auxiliary variable under the ideal SAV update. For the PNP-NS system, a structure-preserving randomized neural network (SP-RaNN) is used for the velocity field, so that the velocity approximation satisfies the incompressibility constraint pointwise by construction. On the theoretical side, we derive residual-based estimates for the raw, uncorrected RaNN solvers of the linearized subproblems, formulate a conditional local-in-time convergence result for the raw outer Picard iteration of the PNP system, and analyze the value-level positivity correction together with the mass-correction and SAV post-processing steps. For the PNP-NS system, we establish an approximation result for the SP-RaNN space and provide a conditional error statement for the corresponding linearized Oseen-type problem. Numerical experiments demonstrate approximation accuracy in the source-driven manufactured tests and illustrate the intended value-level positivity correction, selected-time mass matching, computed free-energy curves based on the final gauge-fixed potential, and divergence-free approximation in benchmark tests.
Structure-preserving Randomized Neural Networks for Incompressible Magnetohydrodynamics Equations
Mar 01, 2026The incompressible magnetohydrodynamic (MHD) equations are fundamental in many scientific and engineering applications. However, their strong nonlinearity and dual divergence-free constraints make them highly challenging for conventional numerical solvers. To overcome these difficulties, we propose a Structure-Preserving Randomized Neural Network (SP-RaNN) that automatically and exactly satisfies the divergence-free conditions. Unlike deep neural network (DNN) approaches that rely on expensive nonlinear and nonconvex optimization, SP-RaNN reformulates the training process into a linear least-squares system, thereby eliminating nonconvex optimization. The method linearizes the governing equations through Picard or Newton iterations, discretizes them at collocation points within the domain and on the boundaries using finite-difference schemes, and solves the resulting linear system via a linear least-squares procedure. By design, SP-RaNN preserves the intrinsic mathematical structure of the equations within a unified space-time framework, ensuring both stability and accuracy. Numerical experiments on the Navier-Stokes, Maxwell, and MHD equations demonstrate that SP-RaNN achieves higher accuracy, faster convergence, and exact enforcement of divergence-free constraints compared with both traditional numerical methods and DNN-based approaches. This structure-preserving framework provides an efficient and reliable tool for solving complex PDE systems while rigorously maintaining their underlying physical laws.
Traceable Cross-Source RAG for Chinese Tibetan Medicine Question Answering
Feb 05, 2026Retrieval-augmented generation (RAG) promises grounded question answering, yet domain settings with multiple heterogeneous knowledge bases (KBs) remain challenging. In Chinese Tibetan medicine, encyclopedia entries are often dense and easy to match, which can dominate retrieval even when classics or clinical papers provide more authoritative evidence. We study a practical setting with three KBs (encyclopedia, classics, and clinical papers) and a 500-query benchmark (cutoff $K{=}5$) covering both single-KB and cross-KB questions. We propose two complementary methods to improve traceability, reduce hallucinations, and enable cross-KB verification. First, DAKS performs KB routing and budgeted retrieval to mitigate density-driven bias and to prioritize authoritative sources when appropriate. Second, we use an alignment graph to guide evidence fusion and coverage-aware packing, improving cross-KB evidence coverage without relying on naive concatenation. All answers are generated by a lightweight generator, \textsc{openPangu-Embedded-7B}. Experiments show consistent gains in routing quality and cross-KB evidence coverage, with the full system achieving the best CrossEv@5 while maintaining strong faithfulness and citation correctness.
TGP: Two-modal occupancy prediction with 3D Gaussian and sparse points for 3D Environment Awareness
Mar 13, 20253D semantic occupancy has rapidly become a research focus in the fields of robotics and autonomous driving environment perception due to its ability to provide more realistic geometric perception and its closer integration with downstream tasks. By performing occupancy prediction of the 3D space in the environment, the ability and robustness of scene understanding can be effectively improved. However, existing occupancy prediction tasks are primarily modeled using voxel or point cloud-based approaches: voxel-based network structures often suffer from the loss of spatial information due to the voxelization process, while point cloud-based methods, although better at retaining spatial location information, face limitations in representing volumetric structural details. To address this issue, we propose a dual-modal prediction method based on 3D Gaussian sets and sparse points, which balances both spatial location and volumetric structural information, achieving higher accuracy in semantic occupancy prediction. Specifically, our method adopts a Transformer-based architecture, taking 3D Gaussian sets, sparse points, and queries as inputs. Through the multi-layer structure of the Transformer, the enhanced queries and 3D Gaussian sets jointly contribute to the semantic occupancy prediction, and an adaptive fusion mechanism integrates the semantic outputs of both modalities to generate the final prediction results. Additionally, to further improve accuracy, we dynamically refine the point cloud at each layer, allowing for more precise location information during occupancy prediction. We conducted experiments on the Occ3DnuScenes dataset, and the experimental results demonstrate superior performance of the proposed method on IoU based metrics.
DMPA: Model Poisoning Attacks on Decentralized Federated Learning for Model Differences
Feb 07, 2025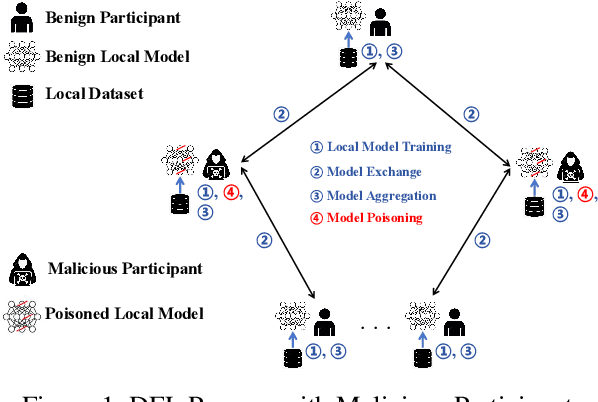
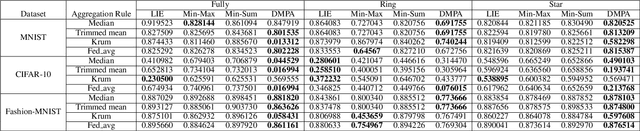
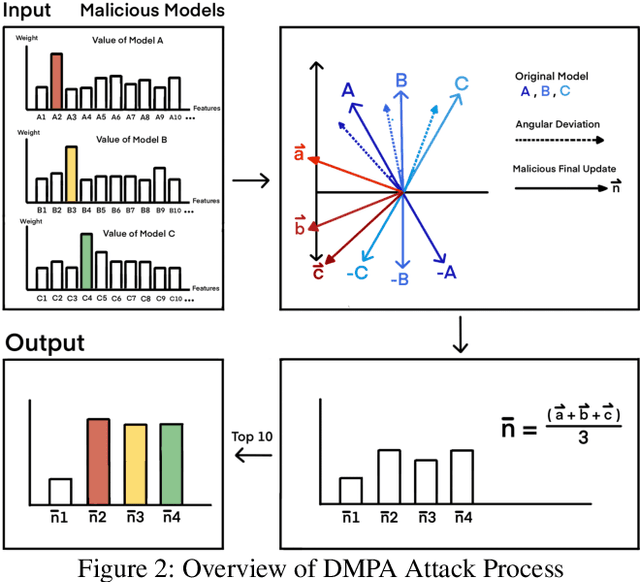
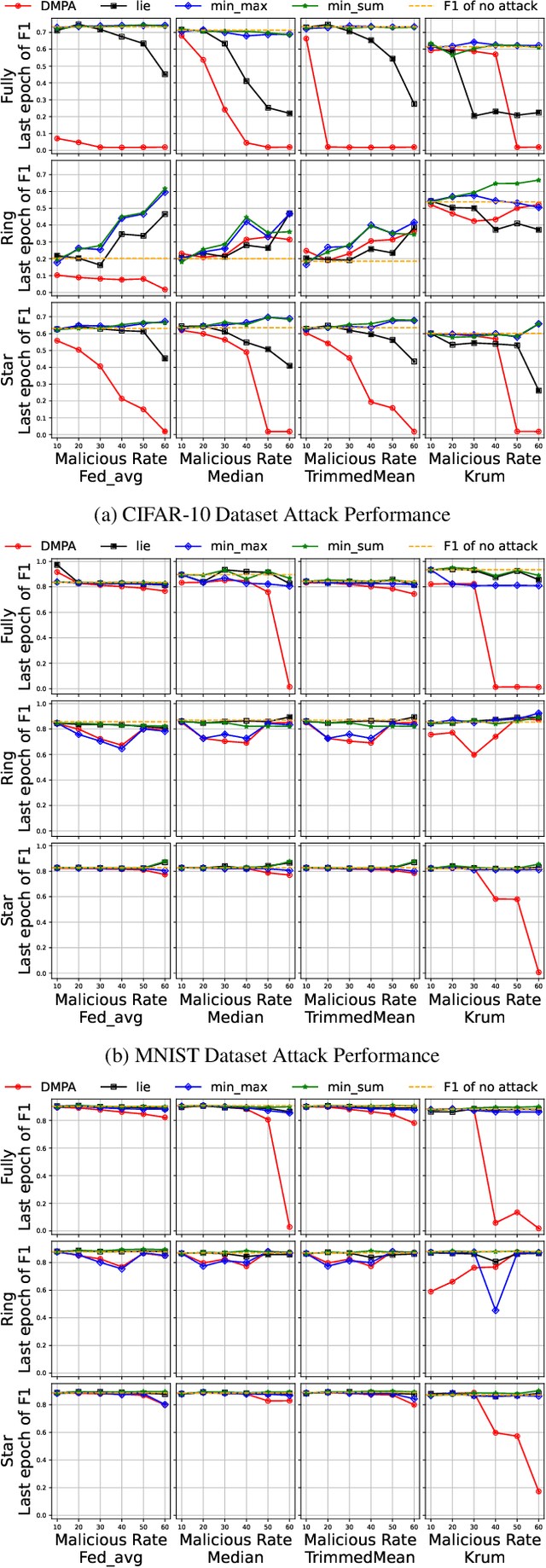
Federated learning (FL) has garnered significant attention as a prominent privacy-preserving Machine Learning (ML) paradigm. Decentralized FL (DFL) eschews traditional FL's centralized server architecture, enhancing the system's robustness and scalability. However, these advantages of DFL also create new vulnerabilities for malicious participants to execute adversarial attacks, especially model poisoning attacks. In model poisoning attacks, malicious participants aim to diminish the performance of benign models by creating and disseminating the compromised model. Existing research on model poisoning attacks has predominantly concentrated on undermining global models within the Centralized FL (CFL) paradigm, while there needs to be more research in DFL. To fill the research gap, this paper proposes an innovative model poisoning attack called DMPA. This attack calculates the differential characteristics of multiple malicious client models and obtains the most effective poisoning strategy, thereby orchestrating a collusive attack by multiple participants. The effectiveness of this attack is validated across multiple datasets, with results indicating that the DMPA approach consistently surpasses existing state-of-the-art FL model poisoning attack strategies.
SafeAug: Safety-Critical Driving Data Augmentation from Naturalistic Datasets
Jan 03, 2025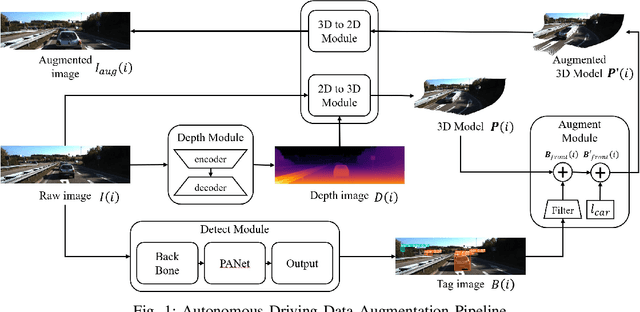

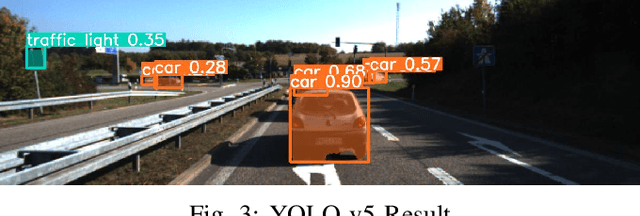

Safety-critical driving data is crucial for developing safe and trustworthy self-driving algorithms. Due to the scarcity of safety-critical data in naturalistic datasets, current approaches primarily utilize simulated or artificially generated images. However, there remains a gap in authenticity between these generated images and naturalistic ones. We propose a novel framework to augment the safety-critical driving data from the naturalistic dataset to address this issue. In this framework, we first detect vehicles using YOLOv5, followed by depth estimation and 3D transformation to simulate vehicle proximity and critical driving scenarios better. This allows for targeted modification of vehicle dynamics data to reflect potentially hazardous situations. Compared to the simulated or artificially generated data, our augmentation methods can generate safety-critical driving data with minimal compromise on image authenticity. Experiments using KITTI datasets demonstrate that a downstream self-driving algorithm trained on this augmented dataset performs superiorly compared to the baselines, which include SMOGN and importance sampling.
SASE: A Searching Architecture for Squeeze and Excitation Operations
Nov 13, 2024In the past few years, channel-wise and spatial-wise attention blocks have been widely adopted as supplementary modules in deep neural networks, enhancing network representational abilities while introducing low complexity. Most attention modules follow a squeeze-and-excitation paradigm. However, to design such attention modules, requires a substantial amount of experiments and computational resources. Neural Architecture Search (NAS), meanwhile, is able to automate the design of neural networks and spares the numerous experiments required for an optimal architecture. This motivates us to design a search architecture that can automatically find near-optimal attention modules through NAS. We propose SASE, a Searching Architecture for Squeeze and Excitation operations, to form a plug-and-play attention block by searching within certain search space. The search space is separated into 4 different sets, each corresponds to the squeeze or excitation operation along the channel or spatial dimension. Additionally, the search sets include not only existing attention blocks but also other operations that have not been utilized in attention mechanisms before. To the best of our knowledge, SASE is the first attempt to subdivide the attention search space and search for architectures beyond currently known attention modules. The searched attention module is tested with extensive experiments across a range of visual tasks. Experimental results indicate that visual backbone networks (ResNet-50/101) using the SASE attention module achieved the best performance compared to those using the current state-of-the-art attention modules. Codes are included in the supplementary material, and they will be made public later.
GenDDS: Generating Diverse Driving Video Scenarios with Prompt-to-Video Generative Model
Aug 28, 2024

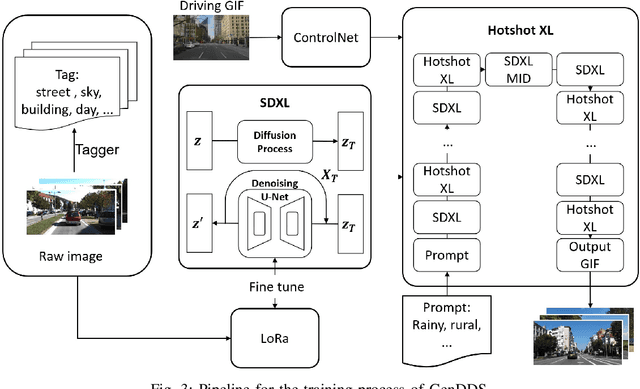

Autonomous driving training requires a diverse range of datasets encompassing various traffic conditions, weather scenarios, and road types. Traditional data augmentation methods often struggle to generate datasets that represent rare occurrences. To address this challenge, we propose GenDDS, a novel approach for generating driving scenarios generation by leveraging the capabilities of Stable Diffusion XL (SDXL), an advanced latent diffusion model. Our methodology involves the use of descriptive prompts to guide the synthesis process, aimed at producing realistic and diverse driving scenarios. With the power of the latest computer vision techniques, such as ControlNet and Hotshot-XL, we have built a complete pipeline for video generation together with SDXL. We employ the KITTI dataset, which includes real-world driving videos, to train the model. Through a series of experiments, we demonstrate that our model can generate high-quality driving videos that closely replicate the complexity and variability of real-world driving scenarios. This research contributes to the development of sophisticated training data for autonomous driving systems and opens new avenues for creating virtual environments for simulation and validation purposes.
Enhancing Cross-Document Event Coreference Resolution by Discourse Structure and Semantic Information
Jun 23, 2024



Existing cross-document event coreference resolution models, which either compute mention similarity directly or enhance mention representation by extracting event arguments (such as location, time, agent, and patient), lacking the ability to utilize document-level information. As a result, they struggle to capture long-distance dependencies. This shortcoming leads to their underwhelming performance in determining coreference for the events where their argument information relies on long-distance dependencies. In light of these limitations, we propose the construction of document-level Rhetorical Structure Theory (RST) trees and cross-document Lexical Chains to model the structural and semantic information of documents. Subsequently, cross-document heterogeneous graphs are constructed and GAT is utilized to learn the representations of events. Finally, a pair scorer calculates the similarity between each pair of events and co-referred events can be recognized using standard clustering algorithm. Additionally, as the existing cross-document event coreference datasets are limited to English, we have developed a large-scale Chinese cross-document event coreference dataset to fill this gap, which comprises 53,066 event mentions and 4,476 clusters. After applying our model on the English and Chinese datasets respectively, it outperforms all baselines by large margins.
A Multi-grained based Attention Network for Semi-supervised Sound Event Detection
Jun 21, 2022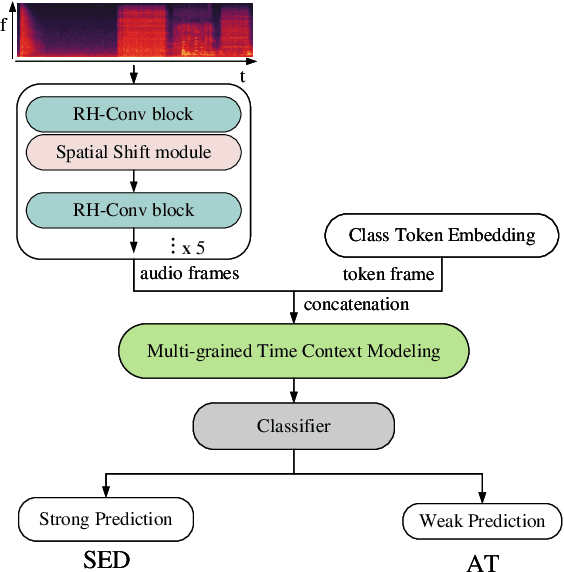
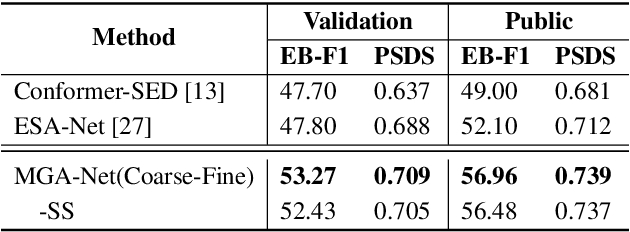
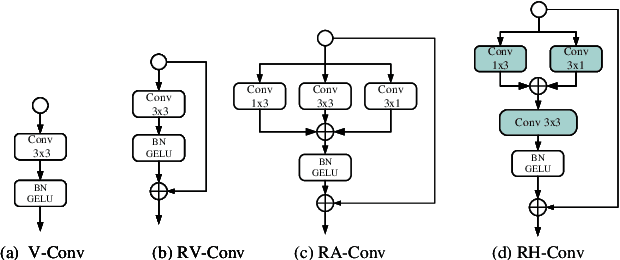
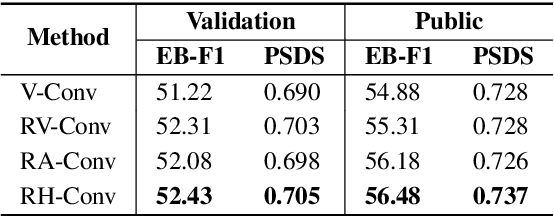
Sound event detection (SED) is an interesting but challenging task due to the scarcity of data and diverse sound events in real life. This paper presents a multi-grained based attention network (MGA-Net) for semi-supervised sound event detection. To obtain the feature representations related to sound events, a residual hybrid convolution (RH-Conv) block is designed to boost the vanilla convolution's ability to extract the time-frequency features. Moreover, a multi-grained attention (MGA) module is designed to learn temporal resolution features from coarse-level to fine-level. With the MGA module,the network could capture the characteristics of target events with short- or long-duration, resulting in more accurately determining the onset and offset of sound events. Furthermore, to effectively boost the performance of the Mean Teacher (MT) method, a spatial shift (SS) module as a data perturbation mechanism is introduced to increase the diversity of data. Experimental results show that the MGA-Net outperforms the published state-of-the-art competitors, achieving 53.27% and 56.96% event-based macro F1 (EB-F1) score, 0.709 and 0.739 polyphonic sound detection score (PSDS) on the validation and public set respectively.