 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWild-Drive: Off-Road Scene Captioning and Path Planning via Robust Multi-modal Routing and Efficient Large Language Model
Feb 28, 2026Explainability and transparent decision-making are essential for the safe deployment of autonomous driving systems. Scene captioning summarizes environmental conditions and risk factors in natural language, improving transparency, safety, and human--robot interaction. However, most existing approaches target structured urban scenarios; in off-road environments, they are vulnerable to single-modality degradations caused by rain, fog, snow, and darkness, and they lack a unified framework that jointly models structured scene captioning and path planning. To bridge this gap, we propose Wild-Drive, an efficient framework for off-road scene captioning and path planning. Wild-Drive adopts modern multimodal encoders and introduces a task-conditioned modality-routing bridge, MoRo-Former, to adaptively aggregate reliable information under degraded sensing. It then integrates an efficient large language model (LLM), together with a planning token and a gate recurrent unit (GRU) decoder, to generate structured captions and predict future trajectories. We also build the OR-C2P Benchmark, which covers structured off-road scene captioning and path planning under diverse sensor corruption conditions. Experiments on OR-C2P dataset and a self-collected dataset show that Wild-Drive outperforms prior LLM-based methods and remains more stable under degraded sensing. The code and benchmark will be publicly available at https://github.com/wangzihanggg/Wild-Drive.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
LVD-GS: Gaussian Splatting SLAM for Dynamic Scenes via Hierarchical Explicit-Implicit Representation Collaboration Rendering
Oct 26, 20253D Gaussian Splatting SLAM has emerged as a widely used technique for high-fidelity mapping in spatial intelligence. However, existing methods often rely on a single representation scheme, which limits their performance in large-scale dynamic outdoor scenes and leads to cumulative pose errors and scale ambiguity. To address these challenges, we propose \textbf{LVD-GS}, a novel LiDAR-Visual 3D Gaussian Splatting SLAM system. Motivated by the human chain-of-thought process for information seeking, we introduce a hierarchical collaborative representation module that facilitates mutual reinforcement for mapping optimization, effectively mitigating scale drift and enhancing reconstruction robustness. Furthermore, to effectively eliminate the influence of dynamic objects, we propose a joint dynamic modeling module that generates fine-grained dynamic masks by fusing open-world segmentation with implicit residual constraints, guided by uncertainty estimates from DINO-Depth features. Extensive evaluations on KITTI, nuScenes, and self-collected datasets demonstrate that our approach achieves state-of-the-art performance compared to existing methods.
XGBoost energy consumption prediction based on multi-system data HVAC
May 20, 2021
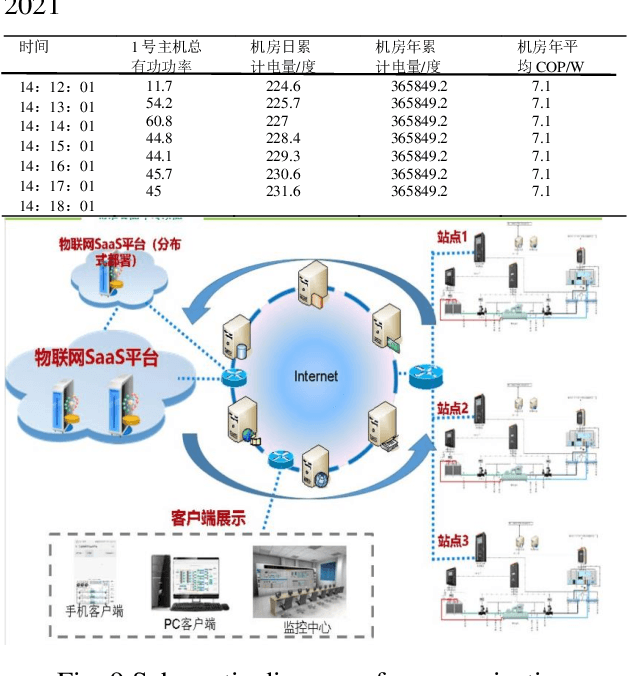
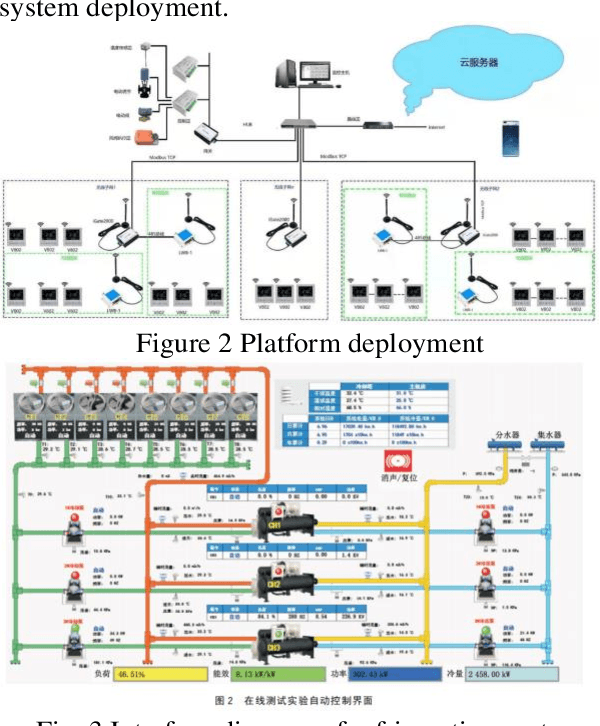
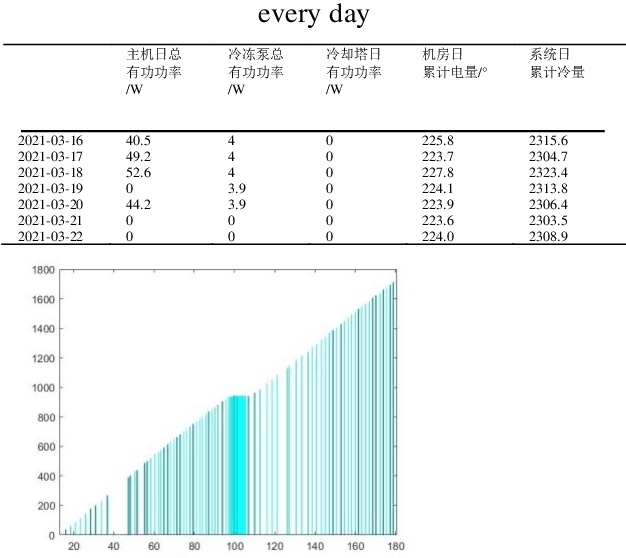
The energy consumption of the HVAC system accounts for a significant portion of the energy consumption of the public building system, and using an efficient energy consumption prediction model can assist it in carrying out effective energy-saving transformation. Unlike the traditional energy consumption prediction model, this paper extracts features from large data sets using XGBoost, trains them separately to obtain multiple models, then fuses them with LightGBM's independent prediction results using MAE, infers energy consumption related variables, and successfully applies this model to the self-developed Internet of Things platform.
Niching Diversity Estimation for Multi-modal Multi-objective Optimization
Jan 31, 2021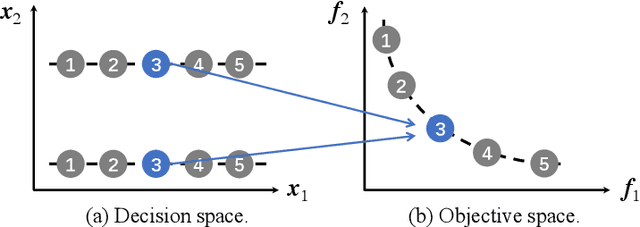
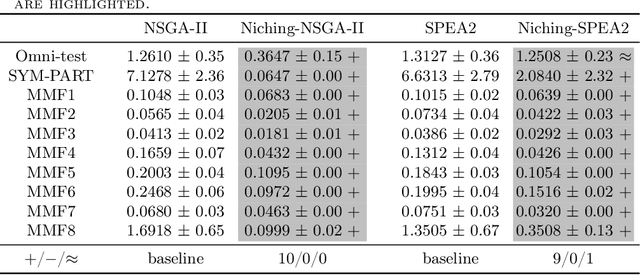
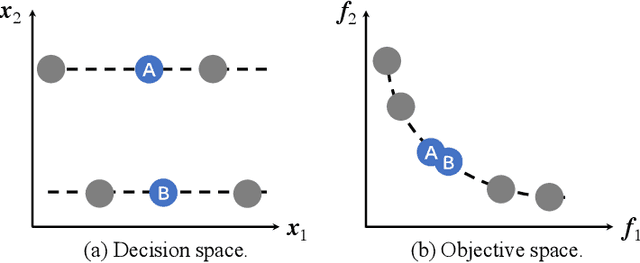
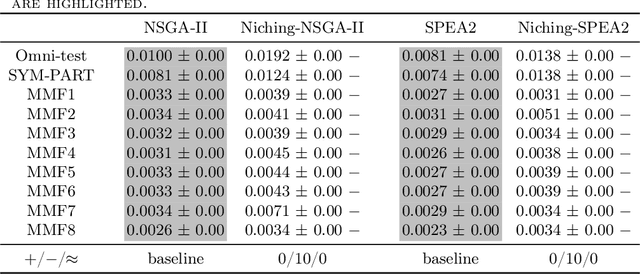
Niching is an important and widely used technique in evolutionary multi-objective optimization. Its applications mainly focus on maintaining diversity and avoiding early convergence to local optimum. Recently, a special class of multi-objective optimization problems, namely, multi-modal multi-objective optimization problems (MMOPs), started to receive increasing attention. In MMOPs, a solution in the objective space may have multiple inverse images in the decision space, which are termed as equivalent solutions. Since equivalent solutions are overlapping (i.e., occupying the same position) in the objective space, standard diversity estimators such as crowding distance are likely to select one of them and discard the others, which may cause diversity loss in the decision space. In this study, a general niching mechanism is proposed to make standard diversity estimators more efficient when handling MMOPs. In our experiments, we integrate our proposed niching diversity estimation method into SPEA2 and NSGA-II and evaluate their performance on several MMOPs. Experimental results show that the proposed niching mechanism notably enhances the performance of SPEA2 and NSGA-II on various MMOPs.
A Decomposition-based Large-scale Multi-modal Multi-objective Optimization Algorithm
Apr 21, 2020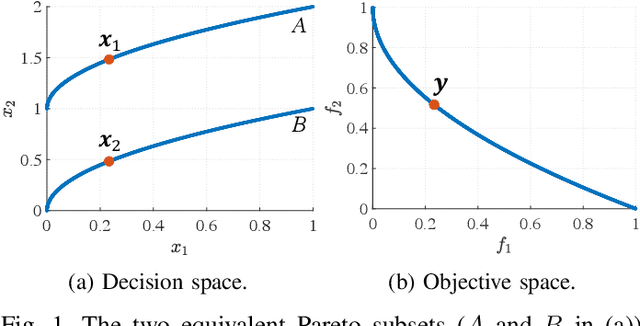
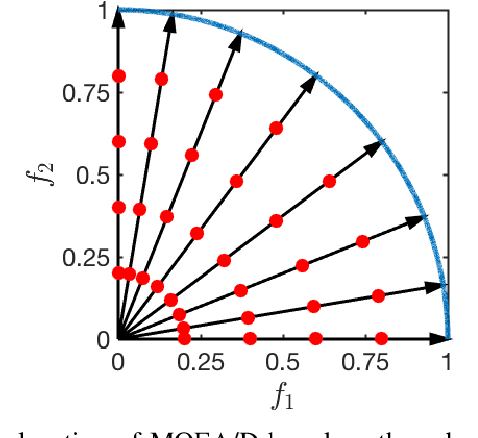
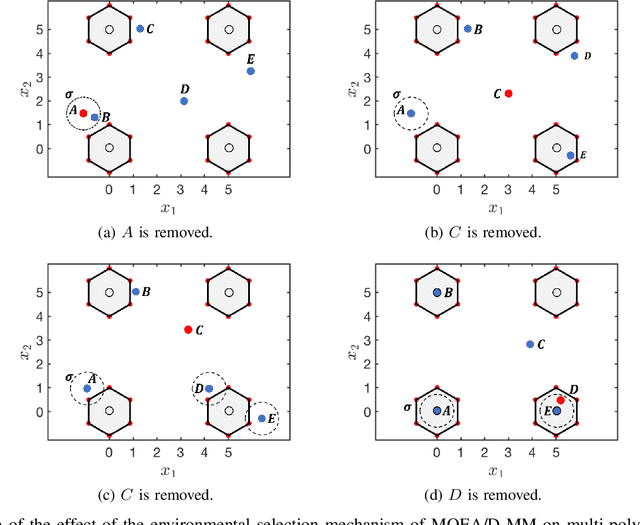
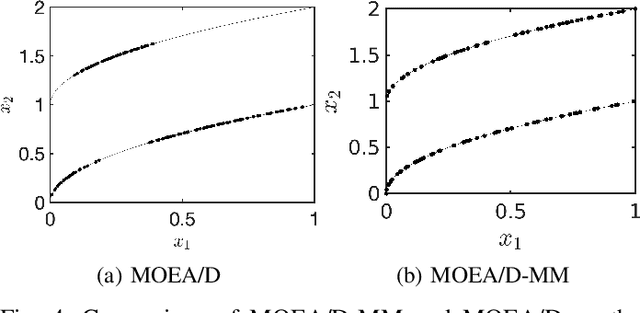
A multi-modal multi-objective optimization problem is a special kind of multi-objective optimization problem with multiple Pareto subsets. In this paper, we propose an efficient multi-modal multi-objective optimization algorithm based on the widely used MOEA/D algorithm. In our proposed algorithm, each weight vector has its own sub-population. With a clearing mechanism and a greedy removal strategy, our proposed algorithm can effectively preserve equivalent Pareto optimal solutions (i.e., different Pareto optimal solutions with same objective values). Experimental results show that our proposed algorithm can effectively preserve the diversity of solutions in the decision space when handling large-scale multi-modal multi-objective optimization problems.
Off-Policy Actor-Critic in an Ensemble: Achieving Maximum General Entropy and Effective Environment Exploration in Deep Reinforcement Learning
Feb 14, 2019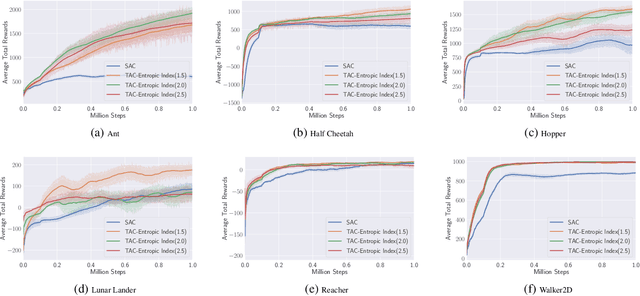
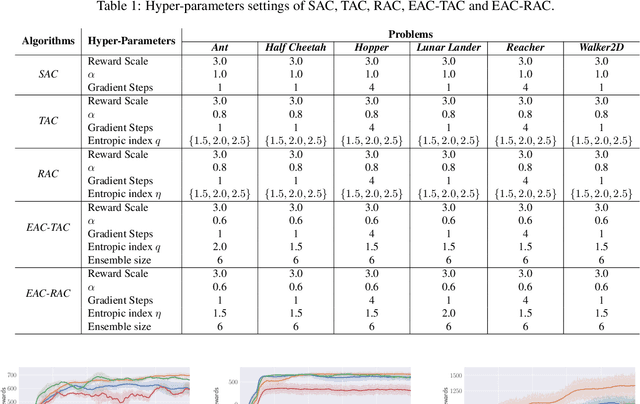
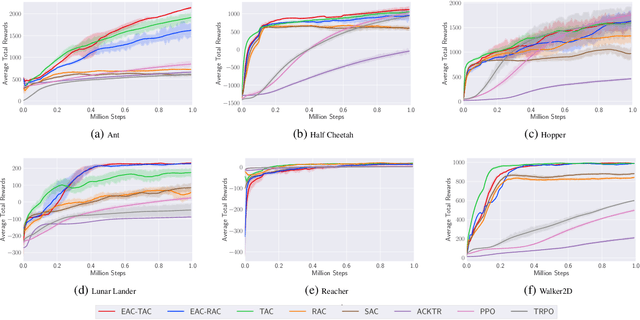
We propose a new policy iteration theory as an important extension of soft policy iteration and Soft Actor-Critic (SAC), one of the most efficient model free algorithms for deep reinforcement learning. Supported by the new theory, arbitrary entropy measures that generalize Shannon entropy, such as Tsallis entropy and Renyi entropy, can be utilized to properly randomize action selection while fulfilling the goal of maximizing expected long-term rewards. Our theory gives birth to two new algorithms, i.e., Tsallis entropy Actor-Critic (TAC) and Renyi entropy Actor-Critic (RAC). Theoretical analysis shows that these algorithms can be more effective than SAC. Moreover, they pave the way for us to develop a new Ensemble Actor-Critic (EAC) algorithm in this paper that features the use of a bootstrap mechanism for deep environment exploration as well as a new value-function based mechanism for high-level action selection. Empirically we show that TAC, RAC and EAC can achieve state-of-the-art performance on a range of benchmark control tasks, outperforming SAC and several cutting-edge learning algorithms in terms of both sample efficiency and effectiveness.
Effective Exploration for Deep Reinforcement Learning via Bootstrapped Q-Ensembles under Tsallis Entropy Regularization
Sep 05, 2018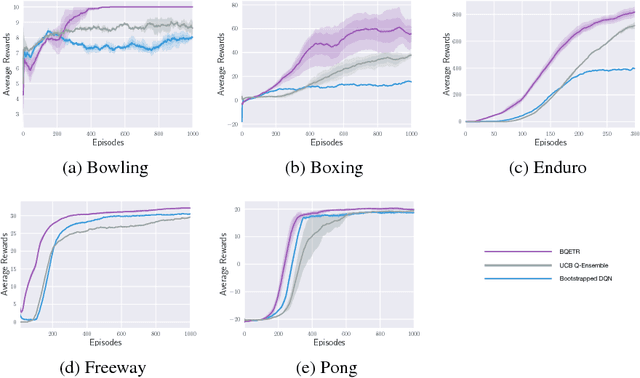

Recently deep reinforcement learning (DRL) has achieved outstanding success on solving many difficult and large-scale RL problems. However the high sample cost required for effective learning often makes DRL unaffordable in resource-limited applications. With the aim of improving sample efficiency and learning performance, we will develop a new DRL algorithm in this paper that seamless integrates entropy-induced and bootstrap-induced techniques for efficient and deep exploration of the learning environment. Specifically, a general form of Tsallis entropy regularizer will be utilized to drive entropy-induced exploration based on efficient approximation of optimal action-selection policies. Different from many existing works that rely on action dithering strategies for exploration, our algorithm is efficient in exploring actions with clear exploration value. Meanwhile, by employing an ensemble of Q-networks under varied Tsallis entropy regularization, the diversity of the ensemble can be further enhanced to enable effective bootstrap-induced exploration. Experiments on Atari game playing tasks clearly demonstrate that our new algorithm can achieve more efficient and effective exploration for DRL, in comparison to recently proposed exploration methods including Bootstrapped Deep Q-Network and UCB Q-Ensemble.
An Adaptive Clipping Approach for Proximal Policy Optimization
Apr 17, 2018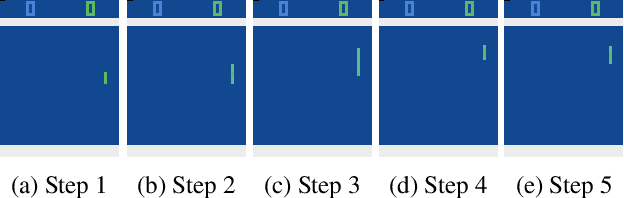

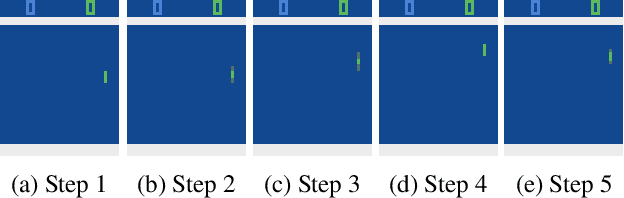

Very recently proximal policy optimization (PPO) algorithms have been proposed as first-order optimization methods for effective reinforcement learning. While PPO is inspired by the same learning theory that justifies trust region policy optimization (TRPO), PPO substantially simplifies algorithm design and improves data efficiency by performing multiple epochs of \emph{clipped policy optimization} from sampled data. Although clipping in PPO stands for an important new mechanism for efficient and reliable policy update, it may fail to adaptively improve learning performance in accordance with the importance of each sampled state. To address this issue, a new surrogate learning objective featuring an adaptive clipping mechanism is proposed in this paper, enabling us to develop a new algorithm, known as PPO-$\lambda$. PPO-$\lambda$ optimizes policies repeatedly based on a theoretical target for adaptive policy improvement. Meanwhile, destructively large policy update can be effectively prevented through both clipping and adaptive control of a hyperparameter $\lambda$ in PPO-$\lambda$, ensuring high learning reliability. PPO-$\lambda$ enjoys the same simple and efficient design as PPO. Empirically on several Atari game playing tasks and benchmark control tasks, PPO-$\lambda$ also achieved clearly better performance than PPO.