 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Exploration for Deep Reinforcement Learning via Bootstrapped Q-Ensembles under Tsallis Entropy Regularization
Paper and Code
Sep 05, 2018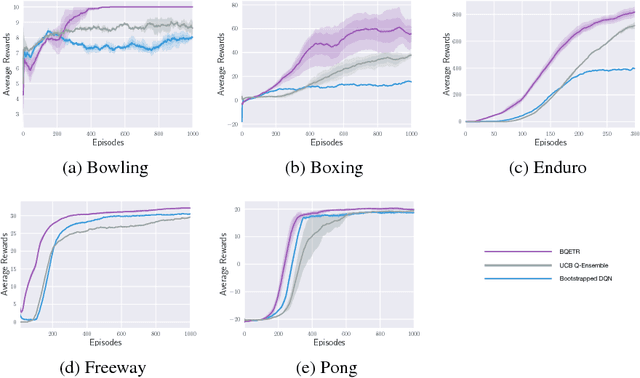

Recently deep reinforcement learning (DRL) has achieved outstanding success on solving many difficult and large-scale RL problems. However the high sample cost required for effective learning often makes DRL unaffordable in resource-limited applications. With the aim of improving sample efficiency and learning performance, we will develop a new DRL algorithm in this paper that seamless integrates entropy-induced and bootstrap-induced techniques for efficient and deep exploration of the learning environment. Specifically, a general form of Tsallis entropy regularizer will be utilized to drive entropy-induced exploration based on efficient approximation of optimal action-selection policies. Different from many existing works that rely on action dithering strategies for exploration, our algorithm is efficient in exploring actions with clear exploration value. Meanwhile, by employing an ensemble of Q-networks under varied Tsallis entropy regularization, the diversity of the ensemble can be further enhanced to enable effective bootstrap-induced exploration. Experiments on Atari game playing tasks clearly demonstrate that our new algorithm can achieve more efficient and effective exploration for DRL, in comparison to recently proposed exploration methods including Bootstrapped Deep Q-Network and UCB Q-Ensemble.