 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Actor-Critic in an Ensemble: Achieving Maximum General Entropy and Effective Environment Exploration in Deep Reinforcement Learning
Paper and Code
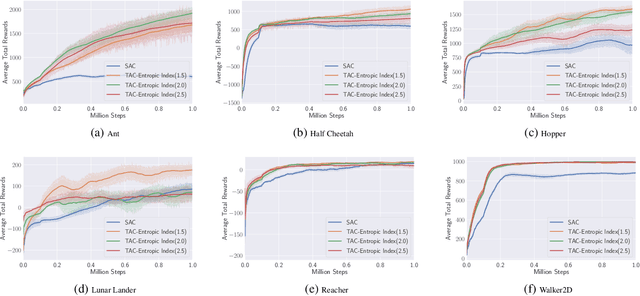
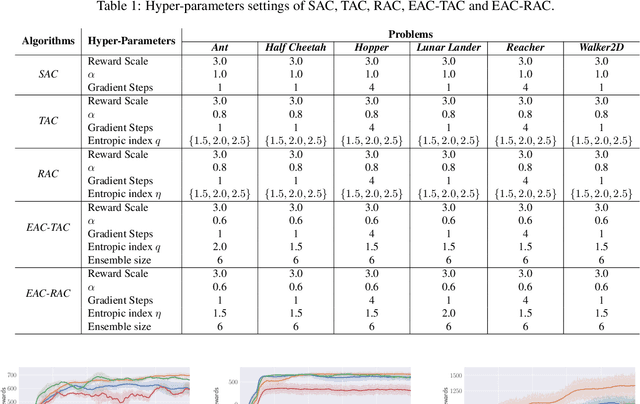
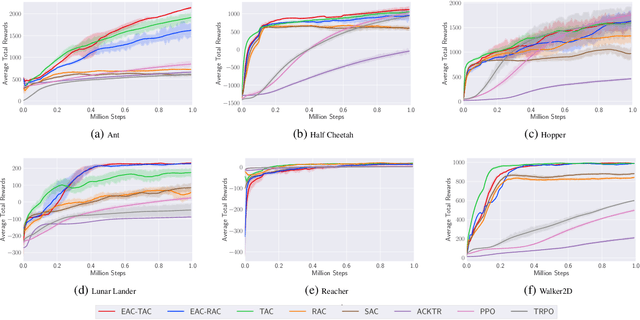
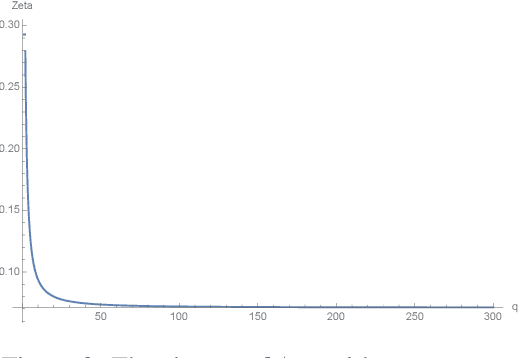
We propose a new policy iteration theory as an important extension of soft policy iteration and Soft Actor-Critic (SAC), one of the most efficient model free algorithms for deep reinforcement learning. Supported by the new theory, arbitrary entropy measures that generalize Shannon entropy, such as Tsallis entropy and Renyi entropy, can be utilized to properly randomize action selection while fulfilling the goal of maximizing expected long-term rewards. Our theory gives birth to two new algorithms, i.e., Tsallis entropy Actor-Critic (TAC) and Renyi entropy Actor-Critic (RAC). Theoretical analysis shows that these algorithms can be more effective than SAC. Moreover, they pave the way for us to develop a new Ensemble Actor-Critic (EAC) algorithm in this paper that features the use of a bootstrap mechanism for deep environment exploration as well as a new value-function based mechanism for high-level action selection. Empirically we show that TAC, RAC and EAC can achieve state-of-the-art performance on a range of benchmark control tasks, outperforming SAC and several cutting-edge learning algorithms in terms of both sample efficiency and effectiveness.