 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Realistic Safety-Critical Driving Video Generation
Jul 02, 2025Designing diverse and safety-critical driving scenarios is essential for evaluating autonomous driving systems. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) for few-shot code generation to automatically synthesize driving scenarios within the CARLA simulator, which has flexibility in scenario scripting, efficient code-based control of traffic participants, and enforcement of realistic physical dynamics. Given a few example prompts and code samples, the LLM generates safety-critical scenario scripts that specify the behavior and placement of traffic participants, with a particular focus on collision events. To bridge the gap between simulation and real-world appearance, we integrate a video generation pipeline using Cosmos-Transfer1 with ControlNet, which converts rendered scenes into realistic driving videos. Our approach enables controllable scenario generation and facilitates the creation of rare but critical edge cases, such as pedestrian crossings under occlusion or sudden vehicle cut-ins. Experimental results demonstrate the effectiveness of our method in generating a wide range of realistic, diverse, and safety-critical scenarios, offering a promising tool for simulation-based testing of autonomous vehicles.
Federated Hierarchical Reinforcement Learning for Adaptive Traffic Signal Control
Apr 07, 2025Multi-agent reinforcement learning (MARL) has shown promise for adaptive traffic signal control (ATSC), enabling multiple intersections to coordinate signal timings in real time. However, in large-scale settings, MARL faces constraints due to extensive data sharing and communication requirements. Federated learning (FL) mitigates these challenges by training shared models without directly exchanging raw data, yet traditional FL methods such as FedAvg struggle with highly heterogeneous intersections. Different intersections exhibit varying traffic patterns, demands, and road structures, so performing FedAvg across all agents is inefficient. To address this gap, we propose Hierarchical Federated Reinforcement Learning (HFRL) for ATSC. HFRL employs clustering-based or optimization-based techniques to dynamically group intersections and perform FedAvg independently within groups of intersections with similar characteristics, enabling more effective coordination and scalability than standard FedAvg. Our experiments on synthetic and real-world traffic networks demonstrate that HFRL not only outperforms both decentralized and standard federated RL approaches but also identifies suitable grouping patterns based on network structure or traffic demand, resulting in a more robust framework for distributed, heterogeneous systems.
DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
Aug 29, 2024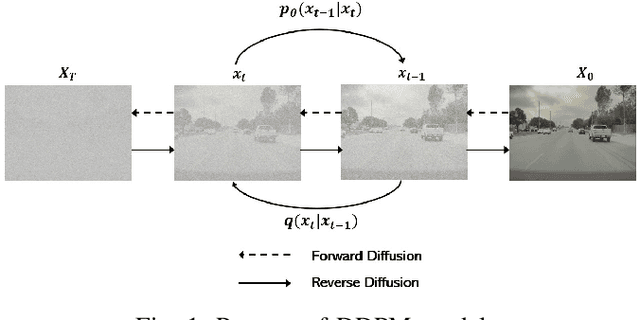
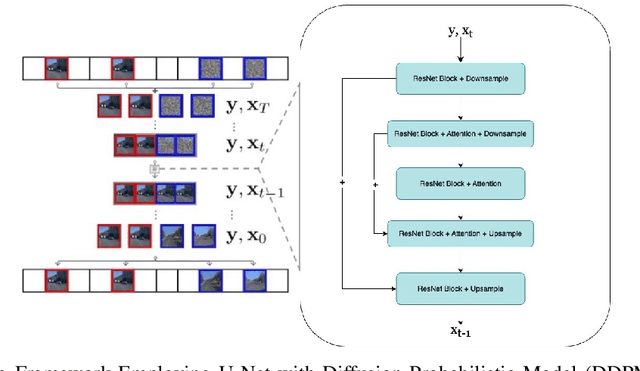
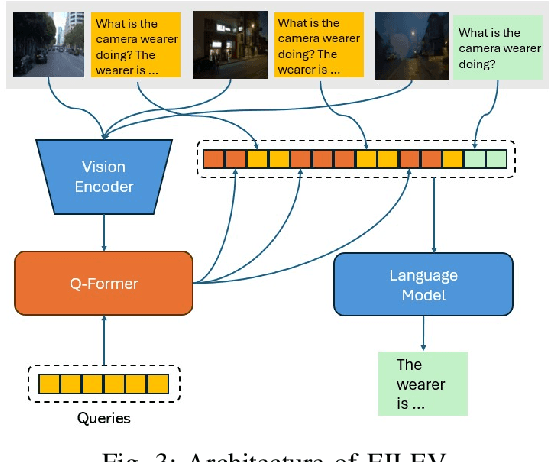

The advancement of autonomous driving technologies necessitates increasingly sophisticated methods for understanding and predicting real-world scenarios. Vision language models (VLMs) are emerging as revolutionary tools with significant potential to influence autonomous driving. In this paper, we propose the DriveGenVLM framework to generate driving videos and use VLMs to understand them. To achieve this, we employ a video generation framework grounded in denoising diffusion probabilistic models (DDPM) aimed at predicting real-world video sequences. We then explore the adequacy of our generated videos for use in VLMs by employing a pre-trained model known as Efficient In-context Learning on Egocentric Videos (EILEV). The diffusion model is trained with the Waymo open dataset and evaluated using the Fr\'echet Video Distance (FVD) score to ensure the quality and realism of the generated videos. Corresponding narrations are provided by EILEV for these generated videos, which may be beneficial in the autonomous driving domain. These narrations can enhance traffic scene understanding, aid in navigation, and improve planning capabilities. The integration of video generation with VLMs in the DriveGenVLM framework represents a significant step forward in leveraging advanced AI models to address complex challenges in autonomous driving.
GenDDS: Generating Diverse Driving Video Scenarios with Prompt-to-Video Generative Model
Aug 28, 2024

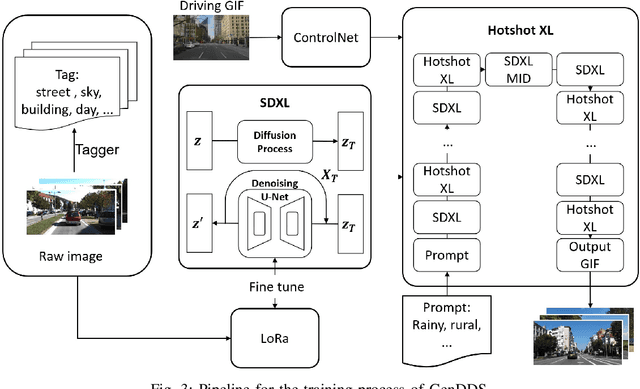

Autonomous driving training requires a diverse range of datasets encompassing various traffic conditions, weather scenarios, and road types. Traditional data augmentation methods often struggle to generate datasets that represent rare occurrences. To address this challenge, we propose GenDDS, a novel approach for generating driving scenarios generation by leveraging the capabilities of Stable Diffusion XL (SDXL), an advanced latent diffusion model. Our methodology involves the use of descriptive prompts to guide the synthesis process, aimed at producing realistic and diverse driving scenarios. With the power of the latest computer vision techniques, such as ControlNet and Hotshot-XL, we have built a complete pipeline for video generation together with SDXL. We employ the KITTI dataset, which includes real-world driving videos, to train the model. Through a series of experiments, we demonstrate that our model can generate high-quality driving videos that closely replicate the complexity and variability of real-world driving scenarios. This research contributes to the development of sophisticated training data for autonomous driving systems and opens new avenues for creating virtual environments for simulation and validation purposes.
Can LLMs Understand Social Norms in Autonomous Driving Games?
Aug 22, 2024



Social norm is defined as a shared standard of acceptable behavior in a society. The emergence of social norms fosters coordination among agents without any hard-coded rules, which is crucial for the large-scale deployment of AVs in an intelligent transportation system. This paper explores the application of LLMs in understanding and modeling social norms in autonomous driving games. We introduce LLMs into autonomous driving games as intelligent agents who make decisions according to text prompts. These agents are referred to as LLM-based agents. Our framework involves LLM-based agents playing Markov games in a multi-agent system (MAS), allowing us to investigate the emergence of social norms among individual agents. We aim to identify social norms by designing prompts and utilizing LLMs on textual information related to the environment setup and the observations of LLM-based agents. Using the OpenAI Chat API powered by GPT-4.0, we conduct experiments to simulate interactions and evaluate the performance of LLM-based agents in two driving scenarios: unsignalized intersection and highway platoon. The results show that LLM-based agents can handle dynamically changing environments in Markov games, and social norms evolve among LLM-based agents in both scenarios. In the intersection game, LLM-based agents tend to adopt a conservative driving policy when facing a potential car crash. The advantage of LLM-based agents in games lies in their strong operability and analyzability, which facilitate experimental design.
Physics-Informed Deep Learning For Traffic State Estimation: A Survey and the Outlook
Mar 03, 2023For its robust predictive power (compared to pure physics-based models) and sample-efficient training (compared to pure deep learning models), physics-informed deep learning (PIDL), a paradigm hybridizing physics-based models and deep neural networks (DNN), has been booming in science and engineering fields. One key challenge of applying PIDL to various domains and problems lies in the design of a computational graph that integrates physics and DNNs. In other words, how physics are encoded into DNNs and how the physics and data components are represented. In this paper, we provide a variety of architecture designs of PIDL computational graphs and how these structures are customized to traffic state estimation (TSE), a central problem in transportation engineering. When observation data, problem type, and goal vary, we demonstrate potential architectures of PIDL computational graphs and compare these variants using the same real-world dataset.
Quantifying Uncertainty In Traffic State Estimation Using Generative Adversarial Networks
Jun 19, 2022

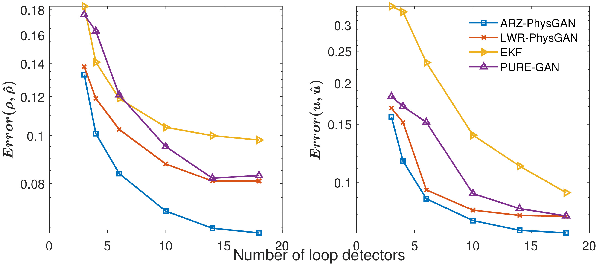

This paper aims to quantify uncertainty in traffic state estimation (TSE) using the generative adversarial network based physics-informed deep learning (PIDL). The uncertainty of the focus arises from fundamental diagrams, in other words, the mapping from traffic density to velocity. To quantify uncertainty for the TSE problem is to characterize the robustness of predicted traffic states. Since its inception, generative adversarial networks (GAN) have become a popular probabilistic machine learning framework. In this paper, we will inform the GAN based predictions using stochastic traffic flow models and develop a GAN based PIDL framework for TSE, named ``PhysGAN-TSE". By conducting experiments on a real-world dataset, the Next Generation SIMulation (NGSIM) dataset, this method is shown to be more robust for uncertainty quantification than the pure GAN model or pure traffic flow models. Two physics models, the Lighthill-Whitham-Richards (LWR) and the Aw-Rascle-Zhang (ARZ) models, are compared as the physics components for the PhysGAN, and results show that the ARZ-based PhysGAN achieves a better performance than the LWR-based one.
TrafficFlowGAN: Physics-informed Flow based Generative Adversarial Network for Uncertainty Quantification
Jun 19, 2022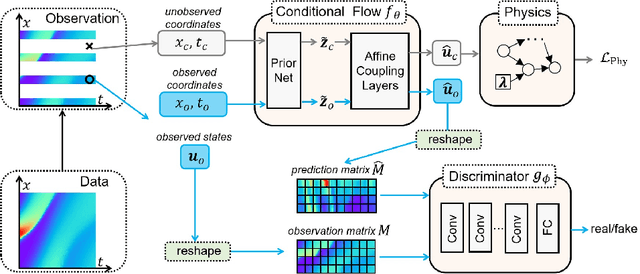
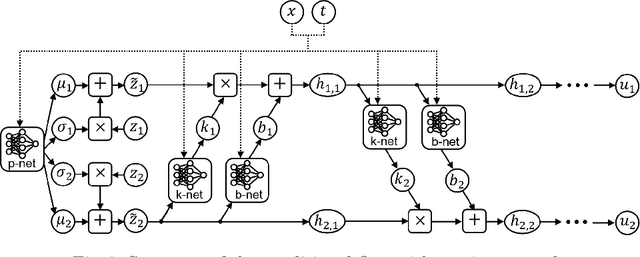
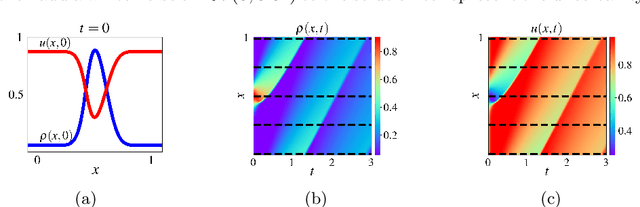
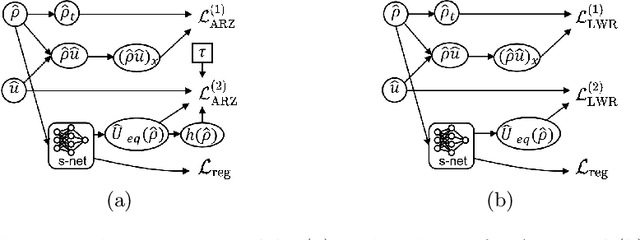
This paper proposes the TrafficFlowGAN, a physics-informed flow based generative adversarial network (GAN), for uncertainty quantification (UQ) of dynamical systems. TrafficFlowGAN adopts a normalizing flow model as the generator to explicitly estimate the data likelihood. This flow model is trained to maximize the data likelihood and to generate synthetic data that can fool a convolutional discriminator. We further regularize this training process using prior physics information, so-called physics-informed deep learning (PIDL). To the best of our knowledge, we are the first to propose an integration of flow, GAN and PIDL for the UQ problems. We take the traffic state estimation (TSE), which aims to estimate the traffic variables (e.g. traffic density and velocity) using partially observed data, as an example to demonstrate the performance of our proposed model. We conduct numerical experiments where the proposed model is applied to learn the solutions of stochastic differential equations. The results demonstrate the robustness and accuracy of the proposed model, together with the ability to learn a machine learning surrogate model. We also test it on a real-world dataset, the Next Generation SIMulation (NGSIM), to show that the proposed TrafficFlowGAN can outperform the baselines, including the pure flow model, the physics-informed flow model, and the flow based GAN model.
CVLight: Deep Reinforcement Learning for Adaptive Traffic Signal Control with Connected Vehicles
Apr 21, 2021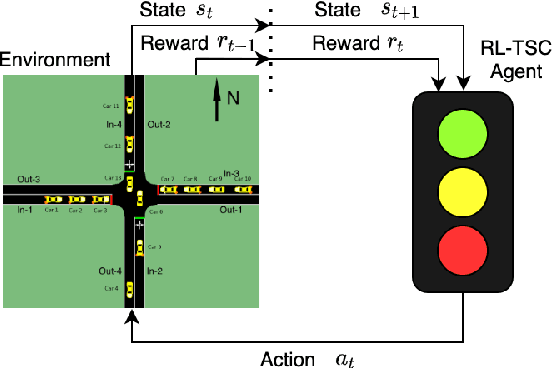
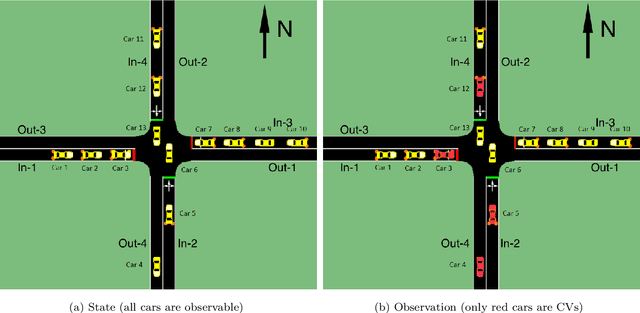

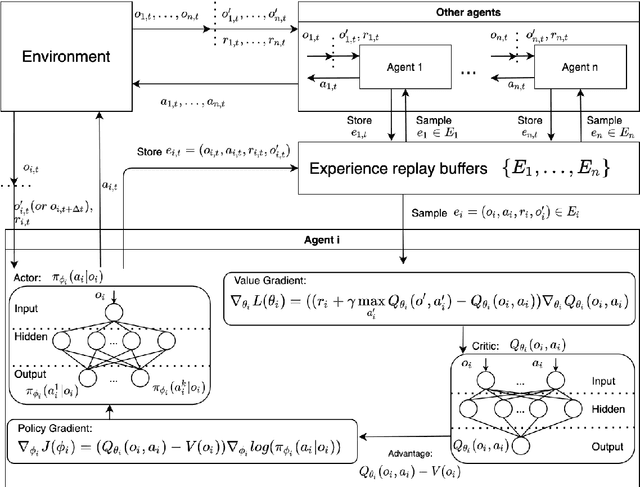
This paper develops a reinforcement learning (RL) scheme for adaptive traffic signal control (ATSC), called "CVLight", that leverages data collected only from connected vehicles (CV). Seven types of RL models are proposed within this scheme that contain various state and reward representations, including incorporation of CV delay and green light duration into state and the usage of CV delay as reward. To further incorporate information of both CV and non-CV into CVLight, an algorithm based on actor-critic, A2C-Full, is proposed where both CV and non-CV information is used to train the critic network, while only CV information is used to update the policy network and execute optimal signal timing. These models are compared at an isolated intersection under various CV market penetration rates. A full model with the best performance (i.e., minimum average travel delay per vehicle) is then selected and applied to compare with state-of-the-art benchmarks under different levels of traffic demands, turning proportions, and dynamic traffic demands, respectively. Two case studies are performed on an isolated intersection and a corridor with three consecutive intersections located in Manhattan, New York, to further demonstrate the effectiveness of the proposed algorithm under real-world scenarios. Compared to other baseline models that use all vehicle information, the trained CVLight agent can efficiently control multiple intersections solely based on CV data and can achieve a similar or even greater performance when the CV penetration rate is no less than 20%.