 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
Paper and Code
Aug 29, 2024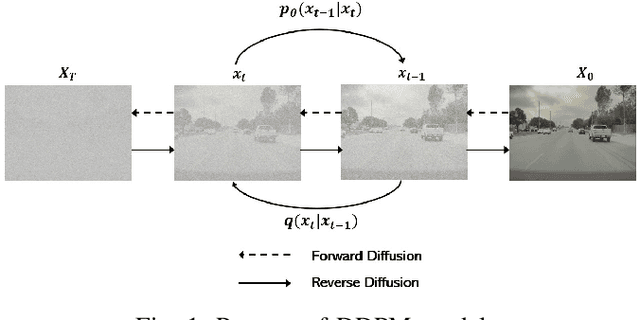
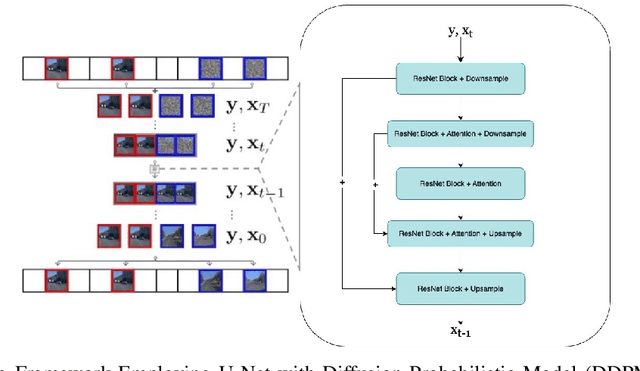
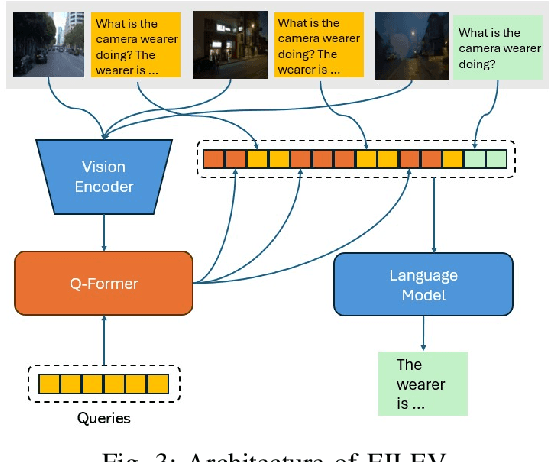

The advancement of autonomous driving technologies necessitates increasingly sophisticated methods for understanding and predicting real-world scenarios. Vision language models (VLMs) are emerging as revolutionary tools with significant potential to influence autonomous driving. In this paper, we propose the DriveGenVLM framework to generate driving videos and use VLMs to understand them. To achieve this, we employ a video generation framework grounded in denoising diffusion probabilistic models (DDPM) aimed at predicting real-world video sequences. We then explore the adequacy of our generated videos for use in VLMs by employing a pre-trained model known as Efficient In-context Learning on Egocentric Videos (EILEV). The diffusion model is trained with the Waymo open dataset and evaluated using the Fr\'echet Video Distance (FVD) score to ensure the quality and realism of the generated videos. Corresponding narrations are provided by EILEV for these generated videos, which may be beneficial in the autonomous driving domain. These narrations can enhance traffic scene understanding, aid in navigation, and improve planning capabilities. The integration of video generation with VLMs in the DriveGenVLM framework represents a significant step forward in leveraging advanced AI models to address complex challenges in autonomous driving.