 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains
Jun 09, 2026Recent advances in reasoning and tool-calling capabilities of large language models (LLMs) have enabled increasingly capable agentic systems. However, existing benchmarks remain limited in task complexity, realism, and domain diversity, and often fail to capture interactions that span multiple domains, limiting their ability to evaluate agents in realistic multi-step settings that require sustained reasoning and coordination. To address these limitations, we introduce T1-Bench, a high-fidelity, comprehensive benchmark for evaluating agentic systems in realistic customer-facing, multi-domain environments, featuring interleaved scenarios that require structured reasoning across multi-turn user-assistant interactions and substantially increasing both compositional complexity and evaluative rigor across 25 domains of varying difficulty. We evaluate T1-Bench using 12 proprietary and open-weight models, providing a reproducible and standardized framework for assessing agent behavior, tool utilization, and conversational quality in complex, multi-step environments. We further complement automatic evaluation with human judgments to strengthen the assessment of qualitative performance. Overall, T1-Bench substantially advances prior benchmarks by increasing task complexity, interaction depth, and domain coverage in simulated multi-domain environments. To facilitate future research on agentic systems, we will publicly release data and evaluation code as open source.
T1: A Tool-Oriented Conversational Dataset for Multi-Turn Agentic Planning
May 22, 2025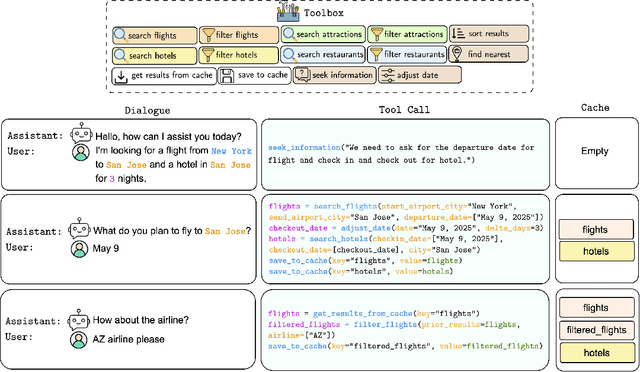


Large Language Models (LLMs) have demonstrated impressive capabilities as intelligent agents capable of solving complex problems. However, effective planning in scenarios involving dependencies between API or tool calls-particularly in multi-turn conversations-remains a significant challenge. To address this, we introduce T1, a tool-augmented, multi-domain, multi-turn conversational dataset specifically designed to capture and manage inter-tool dependencies across diverse domains. T1 enables rigorous evaluation of agents' ability to coordinate tool use across nine distinct domains (4 single domain and 5 multi-domain) with the help of an integrated caching mechanism for both short- and long-term memory, while supporting dynamic replanning-such as deciding whether to recompute or reuse cached results. Beyond facilitating research on tool use and planning, T1 also serves as a benchmark for evaluating the performance of open-source language models. We present results powered by T1-Agent, highlighting their ability to plan and reason in complex, tool-dependent scenarios.
DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
Aug 29, 2024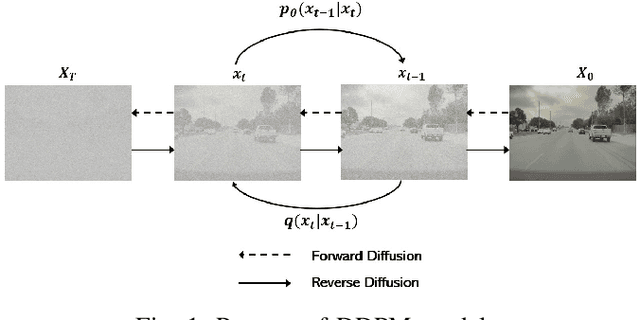
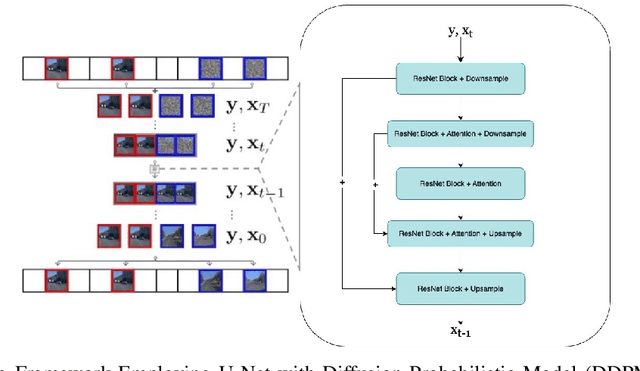
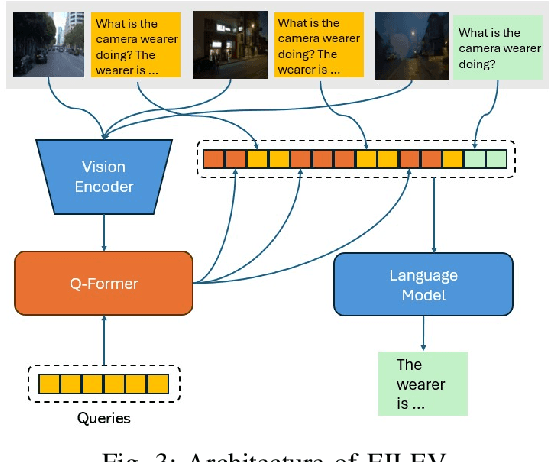

The advancement of autonomous driving technologies necessitates increasingly sophisticated methods for understanding and predicting real-world scenarios. Vision language models (VLMs) are emerging as revolutionary tools with significant potential to influence autonomous driving. In this paper, we propose the DriveGenVLM framework to generate driving videos and use VLMs to understand them. To achieve this, we employ a video generation framework grounded in denoising diffusion probabilistic models (DDPM) aimed at predicting real-world video sequences. We then explore the adequacy of our generated videos for use in VLMs by employing a pre-trained model known as Efficient In-context Learning on Egocentric Videos (EILEV). The diffusion model is trained with the Waymo open dataset and evaluated using the Fr\'echet Video Distance (FVD) score to ensure the quality and realism of the generated videos. Corresponding narrations are provided by EILEV for these generated videos, which may be beneficial in the autonomous driving domain. These narrations can enhance traffic scene understanding, aid in navigation, and improve planning capabilities. The integration of video generation with VLMs in the DriveGenVLM framework represents a significant step forward in leveraging advanced AI models to address complex challenges in autonomous driving.
Evaluating Deep Neural Network Ensembles by Majority Voting cum Meta-Learning scheme
May 09, 2021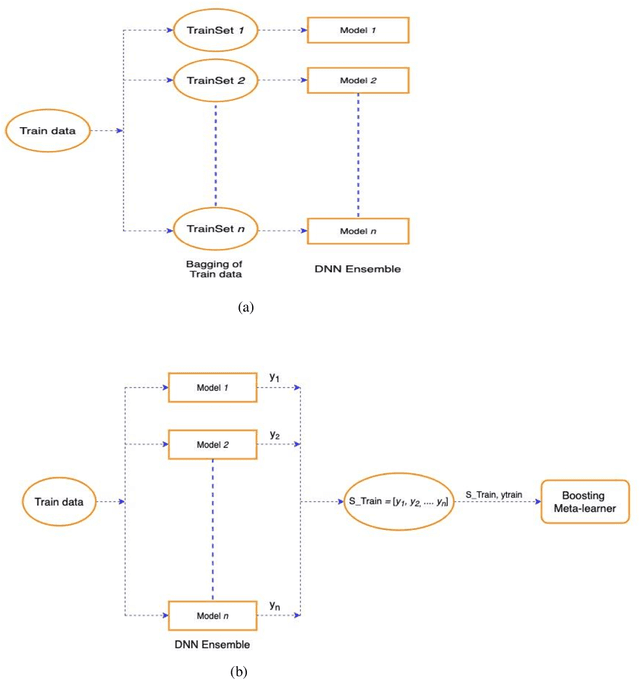



Deep Neural Networks (DNNs) are prone to overfitting and hence have high variance. Overfitted networks do not perform well for a new data instance. So instead of using a single DNN as classifier we propose an ensemble of seven independent DNN learners by varying only the input to these DNNs keeping their architecture and intrinsic properties same. To induce variety in the training input, for each of the seven DNNs, one-seventh of the data is deleted and replenished by bootstrap sampling from the remaining samples. We have proposed a novel technique for combining the prediction of the DNN learners in the ensemble. Our method is called pre-filtering by majority voting coupled with stacked meta-learner which performs a two-step confi-dence check for the predictions before assigning the final class labels. All the algorithms in this paper have been tested on five benchmark datasets name-ly, Human Activity Recognition (HAR), Gas sensor array drift, Isolet, Spam-base and Internet advertisements. Our ensemble approach achieves higher accuracy than a single DNN and the average individual accuracies of DNNs in the ensemble, as well as the baseline approaches of plurality voting and meta-learning.