 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Understand, Reason About, and Generate Code-Switched Text?
Jan 12, 2026Code-switching is a pervasive phenomenon in multilingual communication, yet the robustness of large language models (LLMs) in mixed-language settings remains insufficiently understood. In this work, we present a comprehensive evaluation of LLM capabilities in understanding, reasoning over, and generating code-switched text. We introduce CodeMixQA a novel benchmark with high-quality human annotations, comprising 16 diverse parallel code-switched language-pair variants that span multiple geographic regions and code-switching patterns, and include both original scripts and their transliterated forms. Using this benchmark, we analyze the reasoning behavior of LLMs on code-switched question-answering tasks, shedding light on how models process and reason over mixed-language inputs. We further conduct a systematic evaluation of LLM-generated synthetic code-switched text, focusing on both naturalness and semantic fidelity, and uncover key limitations in current generation capabilities. Our findings reveal persistent challenges in both reasoning and generation under code-switching conditions and provide actionable insights for building more robust multilingual LLMs. We release the dataset and code as open source.
T1: A Tool-Oriented Conversational Dataset for Multi-Turn Agentic Planning
May 22, 2025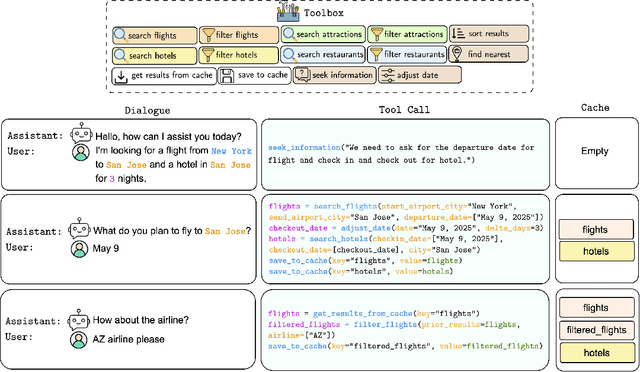
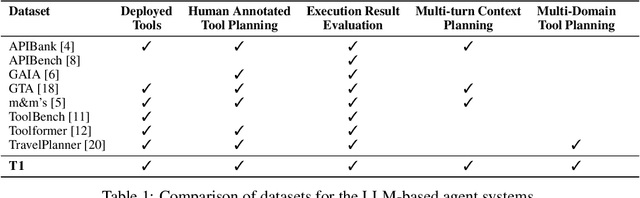


Large Language Models (LLMs) have demonstrated impressive capabilities as intelligent agents capable of solving complex problems. However, effective planning in scenarios involving dependencies between API or tool calls-particularly in multi-turn conversations-remains a significant challenge. To address this, we introduce T1, a tool-augmented, multi-domain, multi-turn conversational dataset specifically designed to capture and manage inter-tool dependencies across diverse domains. T1 enables rigorous evaluation of agents' ability to coordinate tool use across nine distinct domains (4 single domain and 5 multi-domain) with the help of an integrated caching mechanism for both short- and long-term memory, while supporting dynamic replanning-such as deciding whether to recompute or reuse cached results. Beyond facilitating research on tool use and planning, T1 also serves as a benchmark for evaluating the performance of open-source language models. We present results powered by T1-Agent, highlighting their ability to plan and reason in complex, tool-dependent scenarios.
Continual Pre-training of MoEs: How robust is your router?
Mar 06, 2025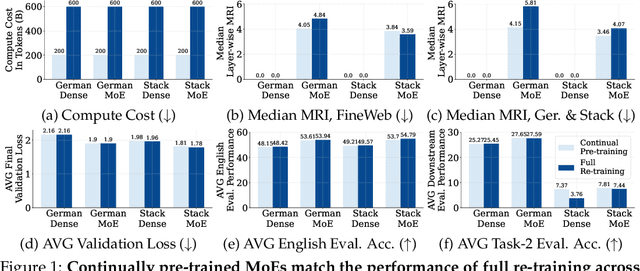
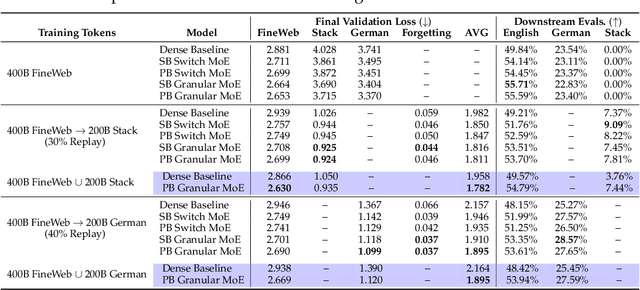
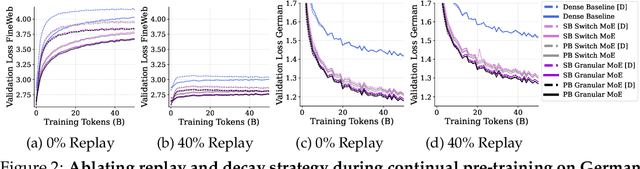
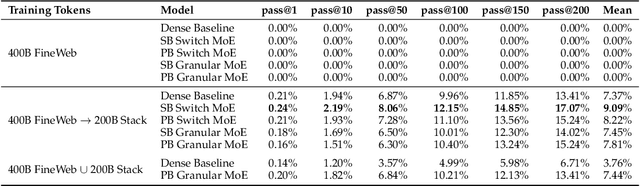
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay and learning rate re-warming and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale (>2B parameter switch and DeepSeek MoE LLMs trained for 600B tokens) empirical study across four MoE transformers to answer these questions. Our results establish a surprising robustness to distribution shifts for both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
RainbowPO: A Unified Framework for Combining Improvements in Preference Optimization
Oct 05, 2024



Recently, numerous preference optimization algorithms have been introduced as extensions to the Direct Preference Optimization (DPO) family. While these methods have successfully aligned models with human preferences, there is a lack of understanding regarding the contributions of their additional components. Moreover, fair and consistent comparisons are scarce, making it difficult to discern which components genuinely enhance downstream performance. In this work, we propose RainbowPO, a unified framework that demystifies the effectiveness of existing DPO methods by categorizing their key components into seven broad directions. We integrate these components into a single cohesive objective, enhancing the performance of each individual element. Through extensive experiments, we demonstrate that RainbowPO outperforms existing DPO variants. Additionally, we provide insights to guide researchers in developing new DPO methods and assist practitioners in their implementations.
Preference Tuning with Human Feedback on Language, Speech, and Vision Tasks: A Survey
Sep 17, 2024



Preference tuning is a crucial process for aligning deep generative models with human preferences. This survey offers a thorough overview of recent advancements in preference tuning and the integration of human feedback. The paper is organized into three main sections: 1) introduction and preliminaries: an introduction to reinforcement learning frameworks, preference tuning tasks, models, and datasets across various modalities: language, speech, and vision, as well as different policy approaches, 2) in-depth examination of each preference tuning approach: a detailed analysis of the methods used in preference tuning, and 3) applications, discussion, and future directions: an exploration of the applications of preference tuning in downstream tasks, including evaluation methods for different modalities, and an outlook on future research directions. Our objective is to present the latest methodologies in preference tuning and model alignment, enhancing the understanding of this field for researchers and practitioners. We hope to encourage further engagement and innovation in this area.
UniPreCIS : A data pre-processing solution for collocated services on shared IoT
Aug 01, 2022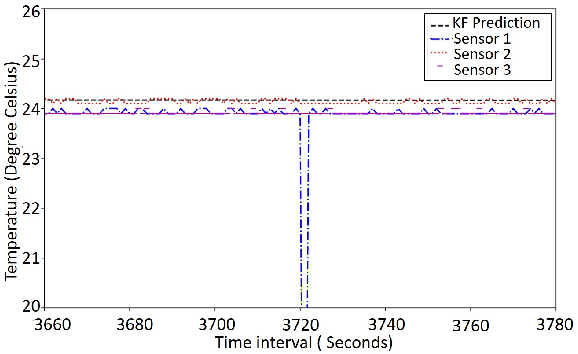
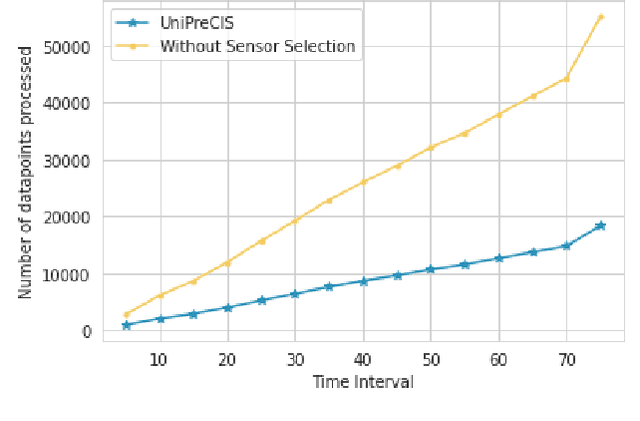
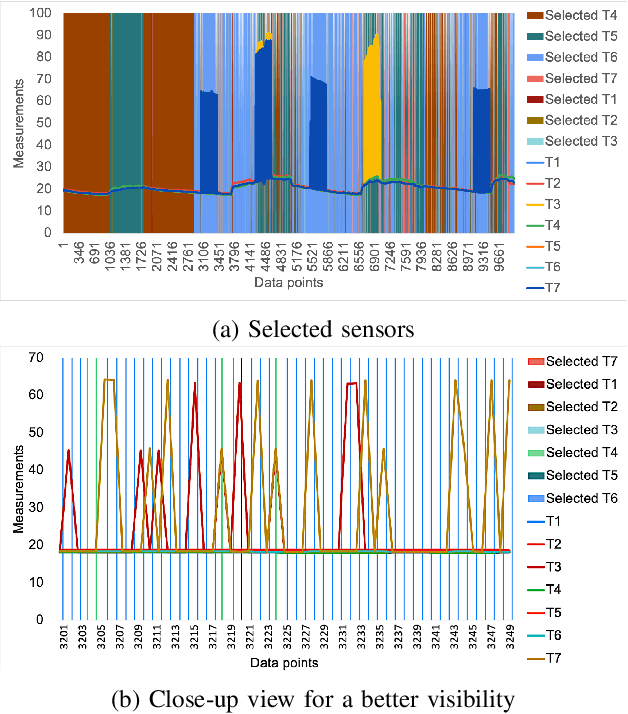
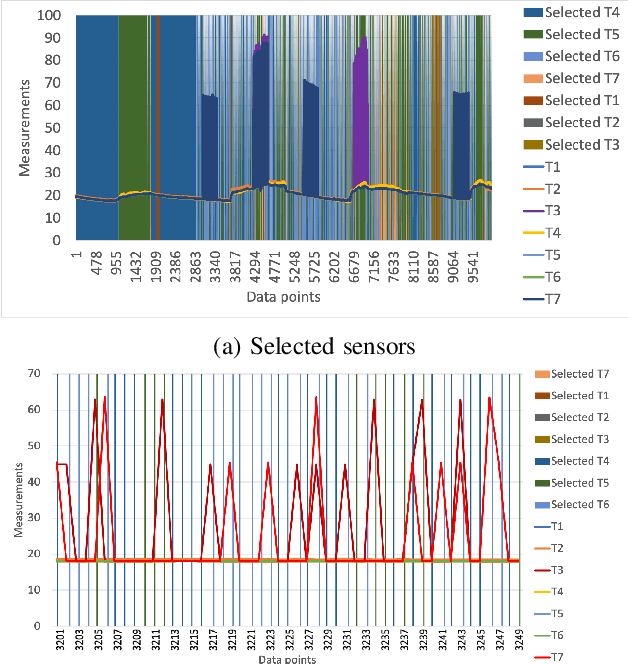
Next-generation smart city applications, attributed by the power of Internet of Things (IoT) and Cyber-Physical Systems (CPS), significantly rely on the quality of sensing data. With an exponential increase in intelligent applications for urban development and enterprises offering sensing-as-aservice these days, it is imperative to provision for a shared sensing infrastructure for better utilization of resources. However, a shared sensing infrastructure that leverages low-cost sensing devices for a cost effective solution, still remains an unexplored territory. A significant research effort is still needed to make edge based data shaping solutions, more reliable, feature-rich and costeffective while addressing the associated challenges in sharing the sensing infrastructure among multiple collocated services with diverse Quality of Service (QoS) requirements. Towards this, we propose a novel edge based data pre-processing solution, named UniPreCIS that accounts for the inherent characteristics of lowcost ambient sensors and the exhibited measurement dynamics with respect to application-specific QoS. UniPreCIS aims to identify and select quality data sources by performing sensor ranking and selection followed by multimodal data pre-processing in order to meet heterogeneous application QoS and at the same time reducing the resource consumption footprint for the resource constrained network edge. As observed, the processing time and memory utilization has been reduced in the proposed approach while achieving upto 90% accuracy which is arguably significant as compared to state-of-the-art techniques for sensing. The effectiveness of UniPreCIS has been evaluated on a testbed for a specific use case of indoor occupancy estimation that proves its effectiveness.
Compressed-VFL: Communication-Efficient Learning with Vertically Partitioned Data
Jun 16, 2022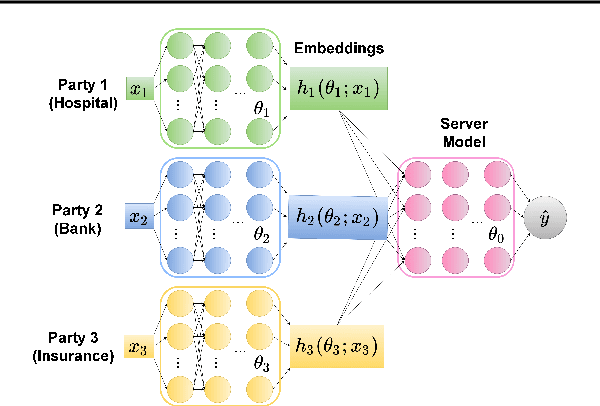

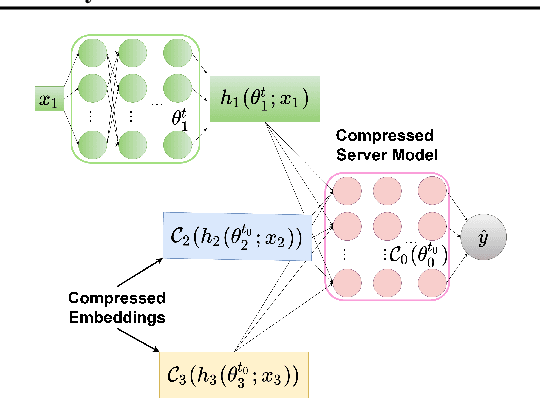
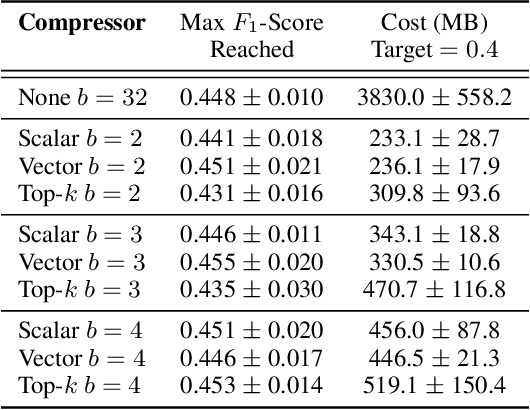
We propose Compressed Vertical Federated Learning (C-VFL) for communication-efficient training on vertically partitioned data. In C-VFL, a server and multiple parties collaboratively train a model on their respective features utilizing several local iterations and sharing compressed intermediate results periodically. Our work provides the first theoretical analysis of the effect message compression has on distributed training over vertically partitioned data. We prove convergence of non-convex objectives at a rate of $O(\frac{1}{\sqrt{T}})$ when the compression error is bounded over the course of training. We provide specific requirements for convergence with common compression techniques, such as quantization and top-$k$ sparsification. Finally, we experimentally show compression can reduce communication by over $90\%$ without a significant decrease in accuracy over VFL without compression.
Cross-Silo Federated Learning for Multi-Tier Networks with Vertical and Horizontal Data Partitioning
Aug 19, 2021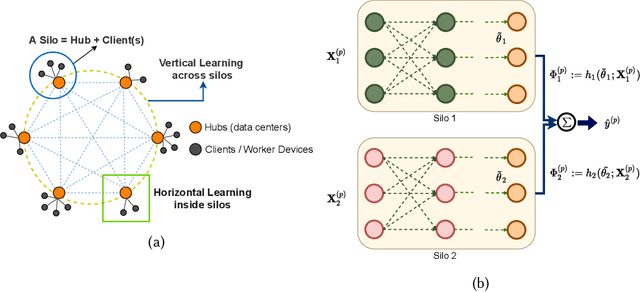
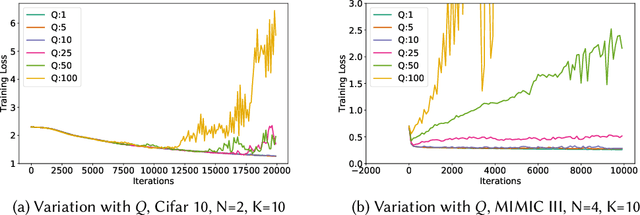
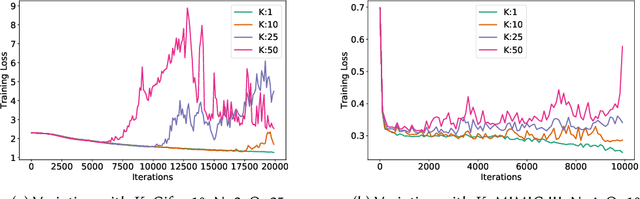
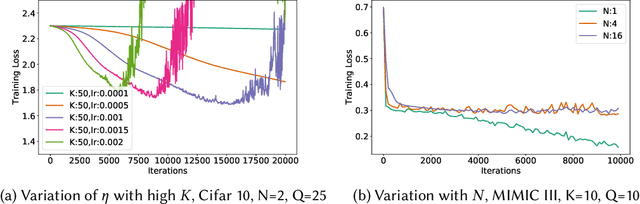
We consider federated learning in tiered communication networks. Our network model consists of a set of silos, each holding a vertical partition of the data. Each silo contains a hub and a set of clients, with the silo's vertical data shard partitioned horizontally across its clients. We propose Tiered Decentralized Coordinate Descent (TDCD), a communication-efficient decentralized training algorithm for such two-tiered networks. To reduce communication overhead, the clients in each silo perform multiple local gradient steps before sharing updates with their hub. Each hub adjusts its coordinates by averaging its workers' updates, and then hubs exchange intermediate updates with one another. We present a theoretical analysis of our algorithm and show the dependence of the convergence rate on the number of vertical partitions, the number of local updates, and the number of clients in each hub. We further validate our approach empirically via simulation-based experiments using a variety of datasets and objectives.
Multi-Tier Federated Learning for Vertically Partitioned Data
Feb 06, 2021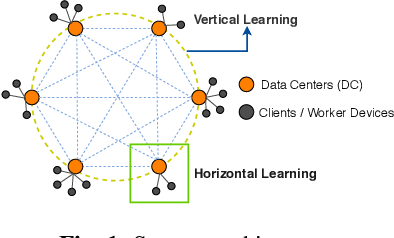
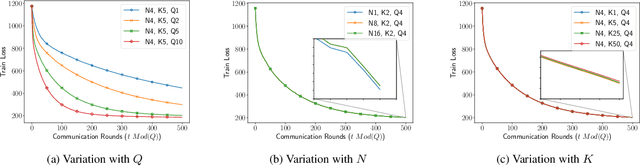
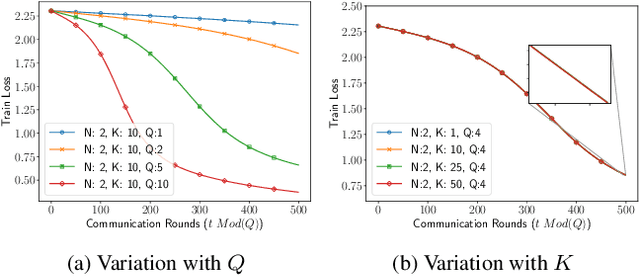
We consider decentralized model training in tiered communication networks. Our network model consists of a set of silos, each holding a vertical partition of the data. Each silo contains a hub and a set of clients, with the silo's vertical data shard partitioned horizontally across its clients. We propose Tiered Decentralized Coordinate Descent (TDCD), a communication-efficient decentralized training algorithm for such two-tiered networks. To reduce communication overhead, the clients in each silo perform multiple local gradient steps before sharing updates with their hub. Each hub adjusts its coordinates by averaging its workers' updates, and then hubs exchange intermediate updates with one another. We present a theoretical analysis of our algorithm and show the dependence of the convergence rate on the number of vertical partitions, the number of local updates, and the number of clients in each hub. We further validate our approach empirically via simulation-based experiments using a variety of datasets and both convex and non-convex objectives.