 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Code LLMs: Data Mix or Model Merge?
Jan 28, 2026Recent research advocates deploying smaller, specialized code LLMs in agentic frameworks alongside frontier models, sparking interest in efficient strategies for multi-task learning that balance performance, constraints, and costs. We compare two approaches for creating small, multi-task code LLMs: data mixing versus model merging. We conduct extensive experiments across two model families (Qwen Coder and DeepSeek Coder) at two scales (2B and 7B parameters), fine-tuning them for code generation and code summarization tasks. Our evaluation on HumanEval, MBPP, and CodeXGlue benchmarks reveals that model merging achieves the best overall performance at larger scale across model families, retaining 96% of specialized model performance on code generation tasks while maintaining summarization capabilities. Notably, merged models can even surpass individually fine-tuned models, with our best configuration of Qwen Coder 2.5 7B model achieving 92.7% Pass@1 on HumanEval compared to 90.9% for its task-specific fine-tuned equivalent. At a smaller scale we find instead data mixing to be a preferred strategy. We further introduce a weight analysis technique to understand how different tasks affect model parameters and their implications for merging strategies. The results suggest that careful merging and mixing strategies can effectively combine task-specific capabilities without significant performance degradation, making them ideal for resource-constrained deployment scenarios.
PBM-VFL: Vertical Federated Learning with Feature and Sample Privacy
Jan 27, 2025We present Poisson Binomial Mechanism Vertical Federated Learning (PBM-VFL), a communication-efficient Vertical Federated Learning algorithm with Differential Privacy guarantees. PBM-VFL combines Secure Multi-Party Computation with the recently introduced Poisson Binomial Mechanism to protect parties' private datasets during model training. We define the novel concept of feature privacy and analyze end-to-end feature and sample privacy of our algorithm. We compare sample privacy loss in VFL with privacy loss in HFL. We also provide the first theoretical characterization of the relationship between privacy budget, convergence error, and communication cost in differentially-private VFL. Finally, we empirically show that our model performs well with high levels of privacy.
Privacy-Preserving Personalized Federated Prompt Learning for Multimodal Large Language Models
Jan 23, 2025
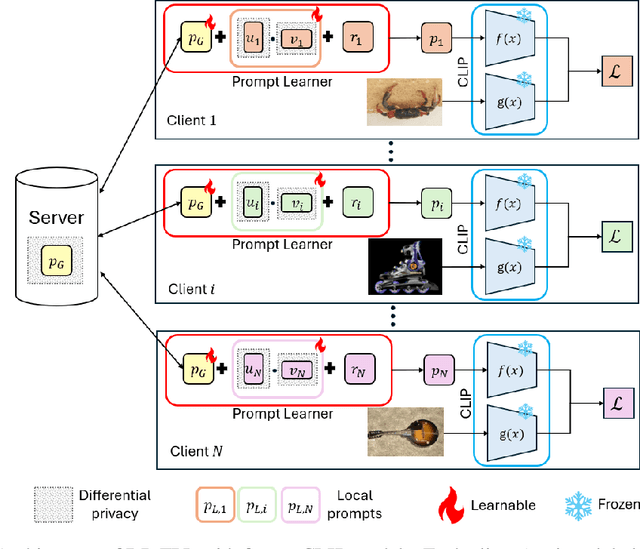
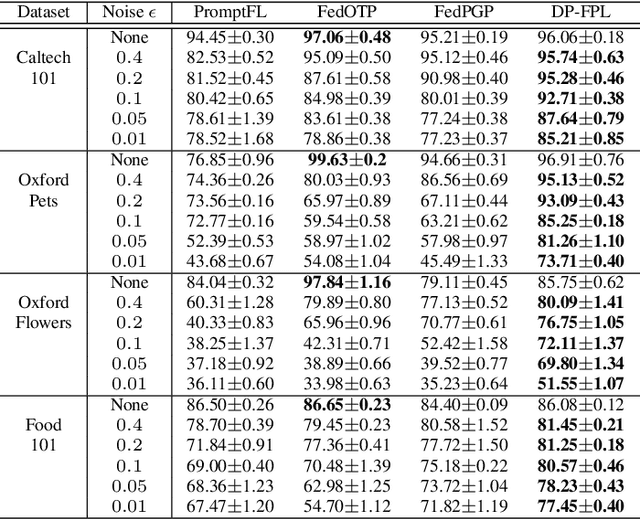

Multimodal Large Language Models (LLMs) are pivotal in revolutionizing customer support and operations by integrating multiple modalities such as text, images, and audio. Federated Prompt Learning (FPL) is a recently proposed approach that combines pre-trained multimodal LLMs such as vision-language models with federated learning to create personalized, privacy-preserving AI systems. However, balancing the competing goals of personalization, generalization, and privacy remains a significant challenge. Over-personalization can lead to overfitting, reducing generalizability, while stringent privacy measures, such as differential privacy, can hinder both personalization and generalization. In this paper, we propose a Differentially Private Federated Prompt Learning (DP-FPL) approach to tackle this challenge by leveraging a low-rank adaptation scheme to capture generalization while maintaining a residual term that preserves expressiveness for personalization. To ensure privacy, we introduce a novel method where we apply local differential privacy to the two low-rank components of the local prompt, and global differential privacy to the global prompt. Our approach mitigates the impact of privacy noise on the model performance while balancing the tradeoff between personalization and generalization. Extensive experiments demonstrate the effectiveness of our approach over other benchmarks.
A Differentially Private Blockchain-Based Approach for Vertical Federated Learning
Jul 09, 2024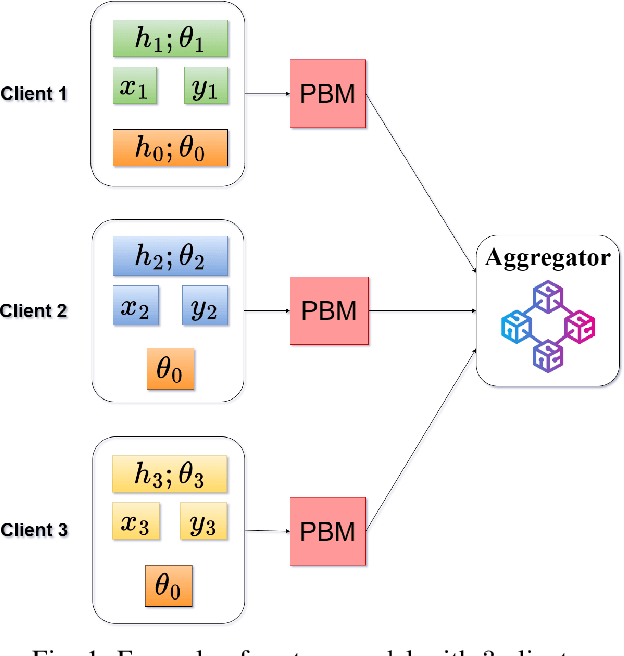
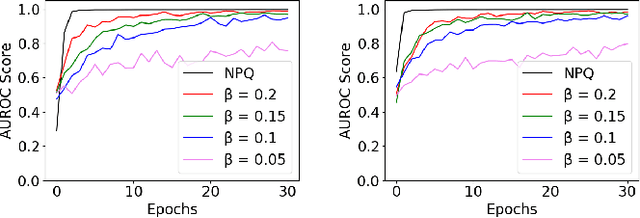
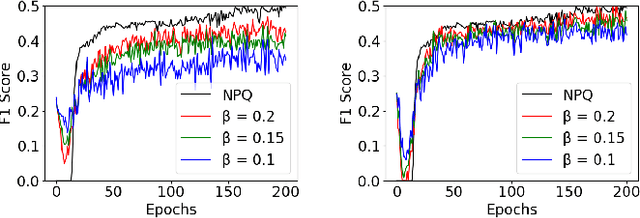
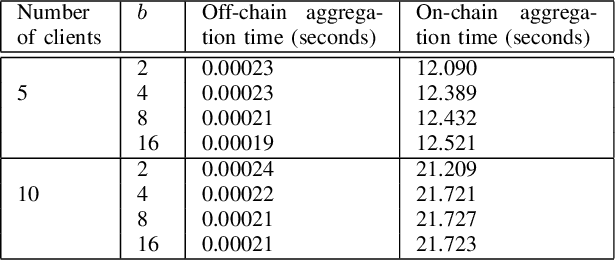
We present the Differentially Private Blockchain-Based Vertical Federal Learning (DP-BBVFL) algorithm that provides verifiability and privacy guarantees for decentralized applications. DP-BBVFL uses a smart contract to aggregate the feature representations, i.e., the embeddings, from clients transparently. We apply local differential privacy to provide privacy for embeddings stored on a blockchain, hence protecting the original data. We provide the first prototype application of differential privacy with blockchain for vertical federated learning. Our experiments with medical data show that DP-BBVFL achieves high accuracy with a tradeoff in training time due to on-chain aggregation. This innovative fusion of differential privacy and blockchain technology in DP-BBVFL could herald a new era of collaborative and trustworthy machine learning applications across several decentralized application domains.
A Survey of Privacy Threats and Defense in Vertical Federated Learning: From Model Life Cycle Perspective
Feb 06, 2024Vertical Federated Learning (VFL) is a federated learning paradigm where multiple participants, who share the same set of samples but hold different features, jointly train machine learning models. Although VFL enables collaborative machine learning without sharing raw data, it is still susceptible to various privacy threats. In this paper, we conduct the first comprehensive survey of the state-of-the-art in privacy attacks and defenses in VFL. We provide taxonomies for both attacks and defenses, based on their characterizations, and discuss open challenges and future research directions. Specifically, our discussion is structured around the model's life cycle, by delving into the privacy threats encountered during different stages of machine learning and their corresponding countermeasures. This survey not only serves as a resource for the research community but also offers clear guidance and actionable insights for practitioners to safeguard data privacy throughout the model's life cycle.
LESS-VFL: Communication-Efficient Feature Selection for Vertical Federated Learning
May 03, 2023



We propose LESS-VFL, a communication-efficient feature selection method for distributed systems with vertically partitioned data. We consider a system of a server and several parties with local datasets that share a sample ID space but have different feature sets. The parties wish to collaboratively train a model for a prediction task. As part of the training, the parties wish to remove unimportant features in the system to improve generalization, efficiency, and explainability. In LESS-VFL, after a short pre-training period, the server optimizes its part of the global model to determine the relevant outputs from party models. This information is shared with the parties to then allow local feature selection without communication. We analytically prove that LESS-VFL removes spurious features from model training. We provide extensive empirical evidence that LESS-VFL can achieve high accuracy and remove spurious features at a fraction of the communication cost of other feature selection approaches.
Compressed-VFL: Communication-Efficient Learning with Vertically Partitioned Data
Jun 16, 2022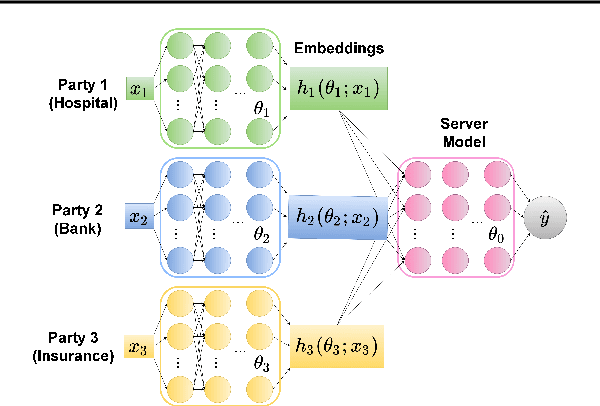

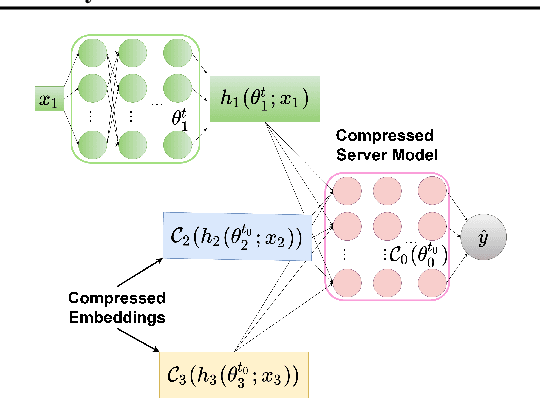
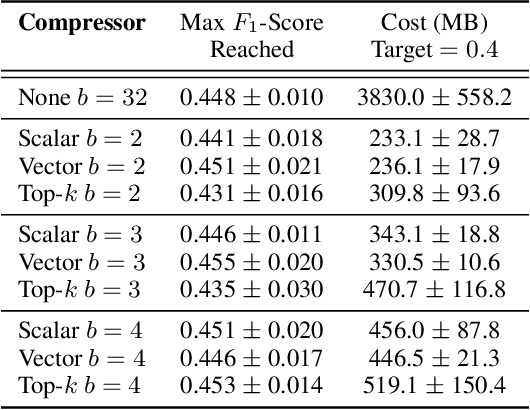
We propose Compressed Vertical Federated Learning (C-VFL) for communication-efficient training on vertically partitioned data. In C-VFL, a server and multiple parties collaboratively train a model on their respective features utilizing several local iterations and sharing compressed intermediate results periodically. Our work provides the first theoretical analysis of the effect message compression has on distributed training over vertically partitioned data. We prove convergence of non-convex objectives at a rate of $O(\frac{1}{\sqrt{T}})$ when the compression error is bounded over the course of training. We provide specific requirements for convergence with common compression techniques, such as quantization and top-$k$ sparsification. Finally, we experimentally show compression can reduce communication by over $90\%$ without a significant decrease in accuracy over VFL without compression.
Cross-Silo Federated Learning for Multi-Tier Networks with Vertical and Horizontal Data Partitioning
Aug 19, 2021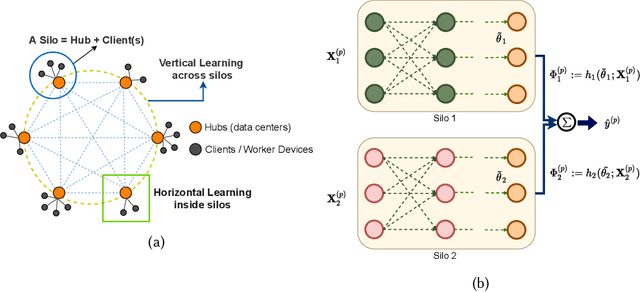
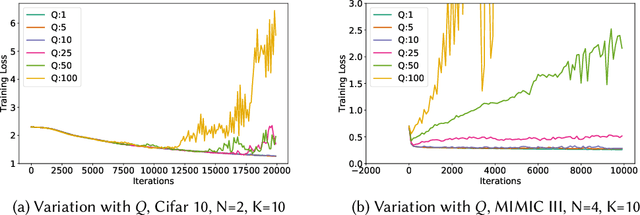
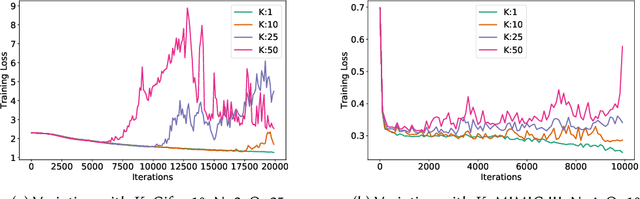
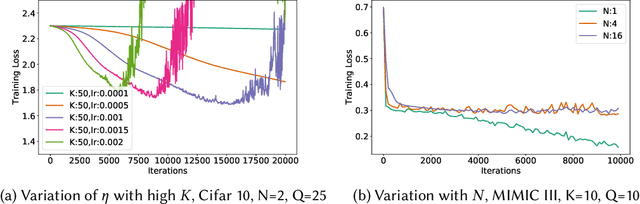
We consider federated learning in tiered communication networks. Our network model consists of a set of silos, each holding a vertical partition of the data. Each silo contains a hub and a set of clients, with the silo's vertical data shard partitioned horizontally across its clients. We propose Tiered Decentralized Coordinate Descent (TDCD), a communication-efficient decentralized training algorithm for such two-tiered networks. To reduce communication overhead, the clients in each silo perform multiple local gradient steps before sharing updates with their hub. Each hub adjusts its coordinates by averaging its workers' updates, and then hubs exchange intermediate updates with one another. We present a theoretical analysis of our algorithm and show the dependence of the convergence rate on the number of vertical partitions, the number of local updates, and the number of clients in each hub. We further validate our approach empirically via simulation-based experiments using a variety of datasets and objectives.
Multi-Tier Federated Learning for Vertically Partitioned Data
Feb 06, 2021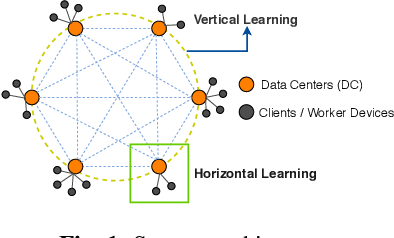
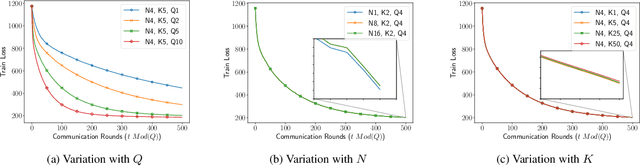
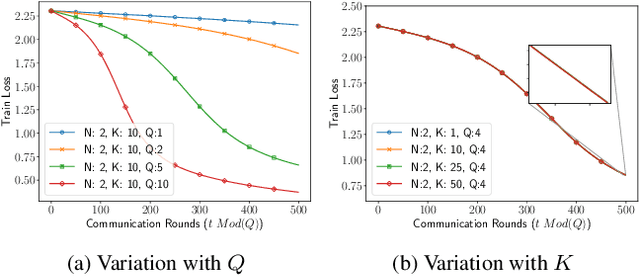
We consider decentralized model training in tiered communication networks. Our network model consists of a set of silos, each holding a vertical partition of the data. Each silo contains a hub and a set of clients, with the silo's vertical data shard partitioned horizontally across its clients. We propose Tiered Decentralized Coordinate Descent (TDCD), a communication-efficient decentralized training algorithm for such two-tiered networks. To reduce communication overhead, the clients in each silo perform multiple local gradient steps before sharing updates with their hub. Each hub adjusts its coordinates by averaging its workers' updates, and then hubs exchange intermediate updates with one another. We present a theoretical analysis of our algorithm and show the dependence of the convergence rate on the number of vertical partitions, the number of local updates, and the number of clients in each hub. We further validate our approach empirically via simulation-based experiments using a variety of datasets and both convex and non-convex objectives.
Multi-Level Local SGD for Heterogeneous Hierarchical Networks
Jul 27, 2020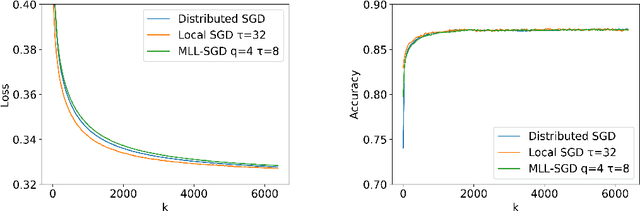
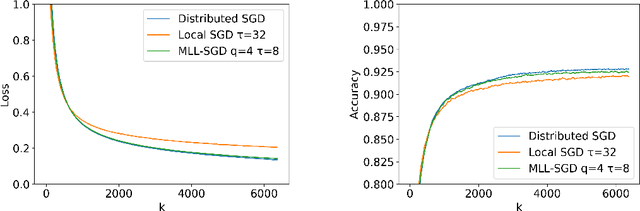
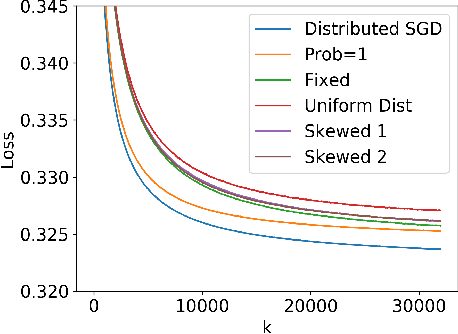
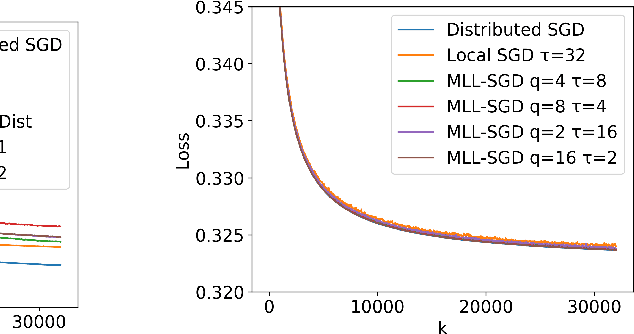
We propose Multi-Level Local SGD, a distributed gradient method for learning a smooth, non-convex objective in a heterogeneous multi-level network. Our network model consists of a set of disjoint sub-networks, with a single hub and multiple worker nodes; further, worker nodes may have different operating rates. The hubs exchange information with one another via a connected, but not necessarily complete communication network. In our algorithm, sub-networks execute a distributed SGD algorithm, using a hub-and-spoke paradigm, and the hubs periodically average their models with neighboring hubs. We first provide a unified mathematical framework that describes the Multi-Level Local SGD algorithm. We then present a theoretical analysis of the algorithm; our analysis shows the dependence of the convergence error on the worker node heterogeneity, hub network topology, and the number of local, sub-network, and global iterations. We back up our theoretical results via simulation-based experiments using both convex and non-convex objectives.