 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Over-Personalization with Rule-Guided Knowledge Graph Adaptation for LLM Recommendations
Sep 08, 2025We present a lightweight neuro-symbolic framework to mitigate over-personalization in LLM-based recommender systems by adapting user-side Knowledge Graphs (KGs) at inference time. Instead of retraining models or relying on opaque heuristics, our method restructures a user's Personalized Knowledge Graph (PKG) to suppress feature co-occurrence patterns that reinforce Personalized Information Environments (PIEs), i.e., algorithmically induced filter bubbles that constrain content diversity. These adapted PKGs are used to construct structured prompts that steer the language model toward more diverse, Out-PIE recommendations while preserving topical relevance. We introduce a family of symbolic adaptation strategies, including soft reweighting, hard inversion, and targeted removal of biased triples, and a client-side learning algorithm that optimizes their application per user. Experiments on a recipe recommendation benchmark show that personalized PKG adaptations significantly increase content novelty while maintaining recommendation quality, outperforming global adaptation and naive prompt-based methods.
MetaExplainer: A Framework to Generate Multi-Type User-Centered Explanations for AI Systems
Aug 01, 2025Explanations are crucial for building trustworthy AI systems, but a gap often exists between the explanations provided by models and those needed by users. To address this gap, we introduce MetaExplainer, a neuro-symbolic framework designed to generate user-centered explanations. Our approach employs a three-stage process: first, we decompose user questions into machine-readable formats using state-of-the-art large language models (LLM); second, we delegate the task of generating system recommendations to model explainer methods; and finally, we synthesize natural language explanations that summarize the explainer outputs. Throughout this process, we utilize an Explanation Ontology to guide the language models and explainer methods. By leveraging LLMs and a structured approach to explanation generation, MetaExplainer aims to enhance the interpretability and trustworthiness of AI systems across various applications, providing users with tailored, question-driven explanations that better meet their needs. Comprehensive evaluations of MetaExplainer demonstrate a step towards evaluating and utilizing current state-of-the-art explanation frameworks. Our results show high performance across all stages, with a 59.06% F1-score in question reframing, 70% faithfulness in model explanations, and 67% context-utilization in natural language synthesis. User studies corroborate these findings, highlighting the creativity and comprehensiveness of generated explanations. Tested on the Diabetes (PIMA Indian) tabular dataset, MetaExplainer supports diverse explanation types, including Contrastive, Counterfactual, Rationale, Case-Based, and Data explanations. The framework's versatility and traceability from using ontology to guide LLMs suggest broad applicability beyond the tested scenarios, positioning MetaExplainer as a promising tool for enhancing AI explainability across various domains.
Terminators: Terms of Service Parsing and Auditing Agents
May 16, 2025Terms of Service (ToS) documents are often lengthy and written in complex legal language, making them difficult for users to read and understand. To address this challenge, we propose Terminators, a modular agentic framework that leverages large language models (LLMs) to parse and audit ToS documents. Rather than treating ToS understanding as a black-box summarization problem, Terminators breaks the task down to three interpretable steps: term extraction, verification, and accountability planning. We demonstrate the effectiveness of our method on the OpenAI ToS using GPT-4o, highlighting strategies to minimize hallucinations and maximize auditability. Our results suggest that structured, agent-based LLM workflows can enhance both the usability and enforceability of complex legal documents. By translating opaque terms into actionable, verifiable components, Terminators promotes ethical use of web content by enabling greater transparency, empowering users to understand their digital rights, and supporting automated policy audits for regulatory or civic oversight.
Blockchain-based Framework for Scalable and Incentivized Federated Learning
Feb 20, 2025


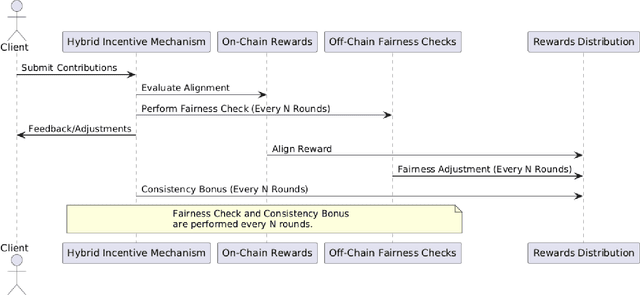
Federated Learning (FL) enables collaborative model training without sharing raw data, preserving privacy while harnessing distributed datasets. However, traditional FL systems often rely on centralized aggregating mechanisms, introducing trust issues, single points of failure, and limited mechanisms for incentivizing meaningful client contributions. These challenges are exacerbated as FL scales to train resource-intensive models, such as large language models (LLMs), requiring scalable, decentralized solutions. This paper presents a blockchain-based FL framework that addresses these limitations by integrating smart contracts and a novel hybrid incentive mechanism. The framework automates critical FL tasks, including client registration, update validation, reward distribution, and maintaining a transparent global state. The hybrid incentive mechanism combines on-chain alignment-based rewards, off-chain fairness checks, and consistency multipliers to ensure fairness, transparency, and sustained engagement. We evaluate the framework through gas cost analysis, demonstrating its feasibility for different scales of federated learning scenarios.
Explainability-Driven Quality Assessment for Rule-Based Systems
Feb 03, 2025This paper introduces an explanation framework designed to enhance the quality of rules in knowledge-based reasoning systems based on dataset-driven insights. The traditional method for rule induction from data typically requires labor-intensive labeling and data-driven learning. This framework provides an alternative and instead allows for the data-driven refinement of existing rules: it generates explanations of rule inferences and leverages human interpretation to refine rules. It leverages four complementary explanation types: trace-based, contextual, contrastive, and counterfactual, providing diverse perspectives for debugging, validating, and ultimately refining rules. By embedding explainability into the reasoning architecture, the framework enables knowledge engineers to address inconsistencies, optimize thresholds, and ensure fairness, transparency, and interpretability in decision-making processes. Its practicality is demonstrated through a use case in finance.
On Learning Representations for Tabular Data Distillation
Jan 23, 2025Dataset distillation generates a small set of information-rich instances from a large dataset, resulting in reduced storage requirements, privacy or copyright risks, and computational costs for downstream modeling, though much of the research has focused on the image data modality. We study tabular data distillation, which brings in novel challenges such as the inherent feature heterogeneity and the common use of non-differentiable learning models (such as decision tree ensembles and nearest-neighbor predictors). To mitigate these challenges, we present $\texttt{TDColER}$, a tabular data distillation framework via column embeddings-based representation learning. To evaluate this framework, we also present a tabular data distillation benchmark, ${{\sf \small TDBench}}$. Based on an elaborate evaluation on ${{\sf \small TDBench}}$, resulting in 226,890 distilled datasets and 548,880 models trained on them, we demonstrate that $\texttt{TDColER}$ is able to boost the distilled data quality of off-the-shelf distillation schemes by 0.5-143% across 7 different tabular learning models.
A Differentially Private Blockchain-Based Approach for Vertical Federated Learning
Jul 09, 2024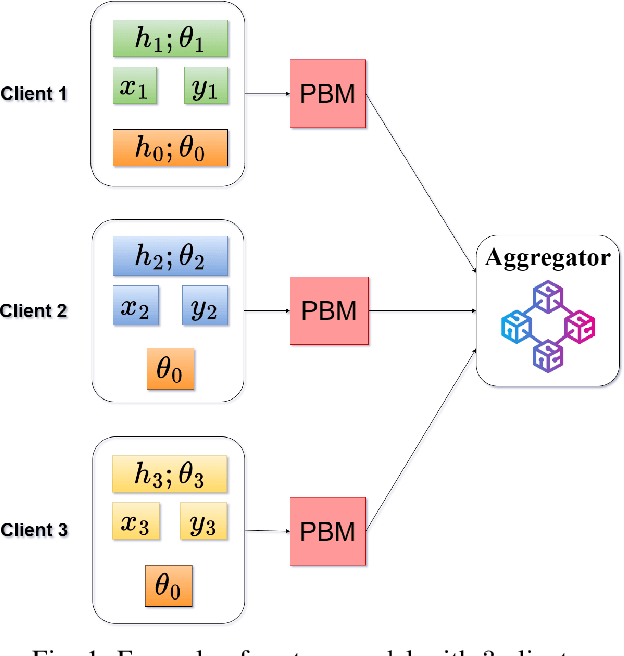
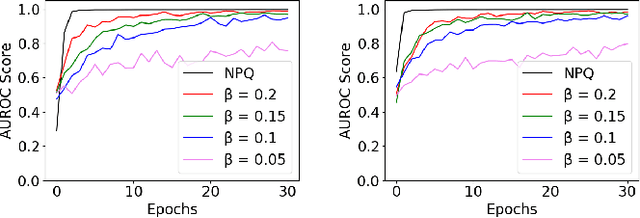
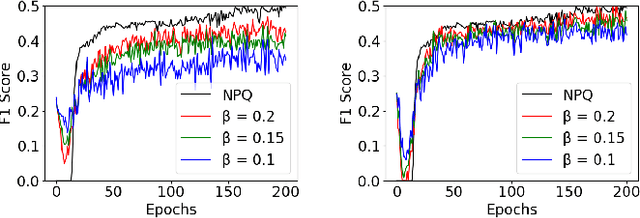
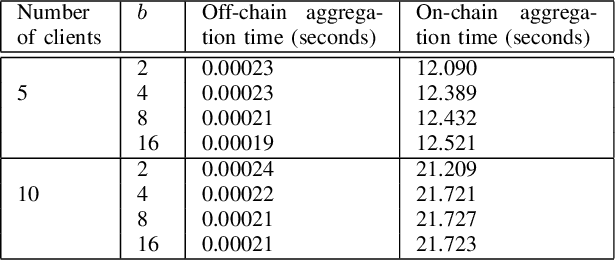
We present the Differentially Private Blockchain-Based Vertical Federal Learning (DP-BBVFL) algorithm that provides verifiability and privacy guarantees for decentralized applications. DP-BBVFL uses a smart contract to aggregate the feature representations, i.e., the embeddings, from clients transparently. We apply local differential privacy to provide privacy for embeddings stored on a blockchain, hence protecting the original data. We provide the first prototype application of differential privacy with blockchain for vertical federated learning. Our experiments with medical data show that DP-BBVFL achieves high accuracy with a tradeoff in training time due to on-chain aggregation. This innovative fusion of differential privacy and blockchain technology in DP-BBVFL could herald a new era of collaborative and trustworthy machine learning applications across several decentralized application domains.
Using Large Language Models for Generating Smart Contracts for Health Insurance from Textual Policies
Jul 09, 2024

We explore using Large Language Models (LLMs) to generate application code that automates health insurance processes from text-based policies. We target blockchain-based smart contracts as they offer immutability, verifiability, scalability, and a trustless setting: any number of parties can use the smart contracts, and they need not have previously established trust relationships with each other. Our methodology generates outputs at increasing levels of technical detail: (1) textual summaries, (2) declarative decision logic, and (3) smart contract code with unit tests. We ascertain LLMs are good at the task (1), and the structured output is useful to validate tasks (2) and (3). Declarative languages (task 2) are often used to formalize healthcare policies, but their execution on blockchain is non-trivial. Hence, task (3) attempts to directly automate the process using smart contracts. To assess the LLM output, we propose completeness, soundness, clarity, syntax, and functioning code as metrics. Our evaluation employs three health insurance policies (scenarios) with increasing difficulty from Medicare's official booklet. Our evaluation uses GPT-3.5 Turbo, GPT-3.5 Turbo 16K, GPT-4, GPT-4 Turbo and CodeLLaMA. Our findings confirm that LLMs perform quite well in generating textual summaries. Although outputs from tasks (2)-(3) are useful starting points, they require human oversight: in multiple cases, even "runnable" code will not yield sound results; the popularity of the target language affects the output quality; and more complex scenarios still seem a bridge too far. Nevertheless, our experiments demonstrate the promise of LLMs for translating textual process descriptions into smart contracts.
Predicting Depression and Anxiety: A Multi-Layer Perceptron for Analyzing the Mental Health Impact of COVID-19
Mar 09, 2024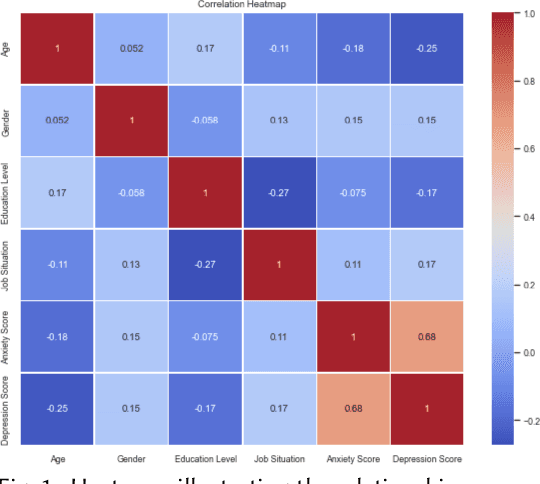



We introduce a multi-layer perceptron (MLP) called the COVID-19 Depression and Anxiety Predictor (CoDAP) to predict mental health trends, particularly anxiety and depression, during the COVID-19 pandemic. Our method utilizes a comprehensive dataset, which tracked mental health symptoms weekly over ten weeks during the initial COVID-19 wave (April to June 2020) in a diverse cohort of U.S. adults. This period, characterized by a surge in mental health symptoms and conditions, offers a critical context for our analysis. Our focus was to extract and analyze patterns of anxiety and depression through a unique lens of qualitative individual attributes using CoDAP. This model not only predicts patterns of anxiety and depression during the pandemic but also unveils key insights into the interplay of demographic factors, behavioral changes, and social determinants of mental health. These findings contribute to a more nuanced understanding of the complexity of mental health issues in times of global health crises, potentially guiding future early interventions.
Trust, Accountability, and Autonomy in Knowledge Graph-based AI for Self-determination
Oct 31, 2023Knowledge Graphs (KGs) have emerged as fundamental platforms for powering intelligent decision-making and a wide range of Artificial Intelligence (AI) services across major corporations such as Google, Walmart, and AirBnb. KGs complement Machine Learning (ML) algorithms by providing data context and semantics, thereby enabling further inference and question-answering capabilities. The integration of KGs with neuronal learning (e.g., Large Language Models (LLMs)) is currently a topic of active research, commonly named neuro-symbolic AI. Despite the numerous benefits that can be accomplished with KG-based AI, its growing ubiquity within online services may result in the loss of self-determination for citizens as a fundamental societal issue. The more we rely on these technologies, which are often centralised, the less citizens will be able to determine their own destinies. To counter this threat, AI regulation, such as the European Union (EU) AI Act, is being proposed in certain regions. The regulation sets what technologists need to do, leading to questions concerning: How can the output of AI systems be trusted? What is needed to ensure that the data fuelling and the inner workings of these artefacts are transparent? How can AI be made accountable for its decision-making? This paper conceptualises the foundational topics and research pillars to support KG-based AI for self-determination. Drawing upon this conceptual framework, challenges and opportunities for citizen self-determination are illustrated and analysed in a real-world scenario. As a result, we propose a research agenda aimed at accomplishing the recommended objectives.