 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfect reconstruction of sparse signals using nonconvexity control and one-step RSB message passing
Dec 19, 2025



We consider sparse signal reconstruction via minimization of the smoothly clipped absolute deviation (SCAD) penalty, and develop one-step replica-symmetry-breaking (1RSB) extensions of approximate message passing (AMP), termed 1RSB-AMP. Starting from the 1RSB formulation of belief propagation, we derive explicit update rules of 1RSB-AMP together with the corresponding state evolution (1RSB-SE) equations. A detailed comparison shows that 1RSB-AMP and 1RSB-SE agree remarkably well at the macroscopic level, even in parameter regions where replica-symmetric (RS) AMP, termed RS-AMP, diverges and where the 1RSB description itself is not expected to be thermodynamically exact. Fixed-point analysis of 1RSB-SE reveals a phase diagram consisting of success, failure, and diverging phases, as in the RS case. However, the diverging-region boundary now depends on the Parisi parameter due to the 1RSB ansatz, and we propose a new criterion -- minimizing the size of the diverging region -- rather than the conventional zero-complexity condition, to determine its value. Combining this criterion with the nonconvexity-control (NCC) protocol proposed in a previous RS study improves the algorithmic limit of perfect reconstruction compared with RS-AMP. Numerical solutions of 1RSB-SE and experiments with 1RSB-AMP confirm that this improved limit is achieved in practice, though the gain is modest and remains slightly inferior to the Bayes-optimal threshold. We also report the behavior of thermodynamic quantities -- overlaps, free entropy, complexity, and the non-self-averaging susceptibility -- that characterize the 1RSB phase in this problem.
Analysis of High-dimensional Gaussian Labeled-unlabeled Mixture Model via Message-passing Algorithm
Nov 29, 2024Semi-supervised learning (SSL) is a machine learning methodology that leverages unlabeled data in conjunction with a limited amount of labeled data. Although SSL has been applied in various applications and its effectiveness has been empirically demonstrated, it is still not fully understood when and why SSL performs well. Some existing theoretical studies have attempted to address this issue by modeling classification problems using the so-called Gaussian Mixture Model (GMM). These studies provide notable and insightful interpretations. However, their analyses are focused on specific purposes, and a thorough investigation of the properties of GMM in the context of SSL has been lacking. In this paper, we conduct such a detailed analysis of the properties of the high-dimensional GMM for binary classification in the SSL setting. To this end, we employ the approximate message passing and state evolution methods, which are widely used in high-dimensional settings and originate from statistical mechanics. We deal with two estimation approaches: the Bayesian one and the l2-regularized maximum likelihood estimation (RMLE). We conduct a comprehensive comparison between these two approaches, examining aspects such as the global phase diagram, estimation error for the parameters, and prediction error for the labels. A specific comparison is made between the Bayes-optimal (BO) estimator and RMLE, as the BO setting provides optimal estimation performance and is ideal as a benchmark. Our analysis shows that with appropriate regularizations, RMLE can achieve near-optimal performance in terms of both the estimation error and prediction error, especially when there is a large amount of unlabeled data. These results demonstrate that the l2 regularization term plays an effective role in estimation and prediction in SSL approaches.
Predicting Depression and Anxiety: A Multi-Layer Perceptron for Analyzing the Mental Health Impact of COVID-19
Mar 09, 2024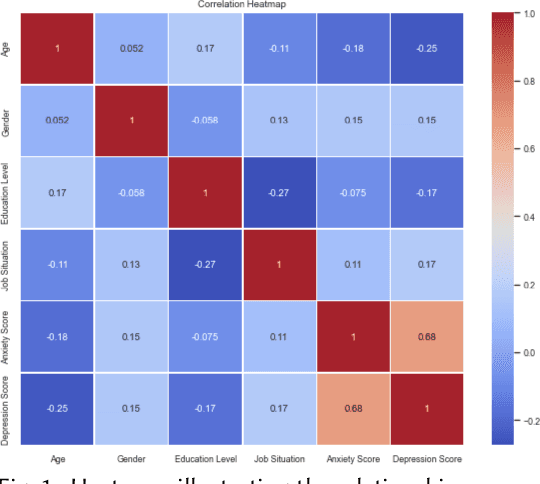



We introduce a multi-layer perceptron (MLP) called the COVID-19 Depression and Anxiety Predictor (CoDAP) to predict mental health trends, particularly anxiety and depression, during the COVID-19 pandemic. Our method utilizes a comprehensive dataset, which tracked mental health symptoms weekly over ten weeks during the initial COVID-19 wave (April to June 2020) in a diverse cohort of U.S. adults. This period, characterized by a surge in mental health symptoms and conditions, offers a critical context for our analysis. Our focus was to extract and analyze patterns of anxiety and depression through a unique lens of qualitative individual attributes using CoDAP. This model not only predicts patterns of anxiety and depression during the pandemic but also unveils key insights into the interplay of demographic factors, behavioral changes, and social determinants of mental health. These findings contribute to a more nuanced understanding of the complexity of mental health issues in times of global health crises, potentially guiding future early interventions.