 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Diagnostics of Spatial Lexical Bias in Multimodal Large Language Model Spatial Reasoning
Jun 01, 2026Multimodal large language models (MLLMs) remain unreliable on spatial multiple-choice questions, and their failures are often attributed to poorly attended visual information. In this work, we identify a complementary failure mode, spatial lexical bias: adding a spatial relation word to the answer options can attract the model's decision and make the newly added option likely to be selected. Using nine open-weight MLLMs, we show that this phenomenon is widely observed. In particular, models can answer a binary spatial question correctly, yet consistently select an incorrect third spatial option once it is added to the answer set. We isolate such binary-stable but ternary-fragile cases as diagnostic examples and leverage mechanistic interpretability tools, revealing that a substantial part of the failure instead originates on the language side rather than the visual side: visual attention analyses and residual-stream probes show the correct spatial relation remains internally available on these failures, while irrelevant-option controls, activation patching, and sparse component interventions trace the bias to specific LLM-side channels and neurons. Based on this finding, we show that a lightweight LLM-only DPO update on tiny single-object-pair synthetic data mitigates the bias, lifting four-way robust accuracy by up to 100 points on synthetic data, and by 68.0, 32.6, and 20.1 points on broader evaluation datasets WhatsUp, SpatialMQA-Direct, and VSR.
Perfect reconstruction of sparse signals using nonconvexity control and one-step RSB message passing
Dec 19, 2025



We consider sparse signal reconstruction via minimization of the smoothly clipped absolute deviation (SCAD) penalty, and develop one-step replica-symmetry-breaking (1RSB) extensions of approximate message passing (AMP), termed 1RSB-AMP. Starting from the 1RSB formulation of belief propagation, we derive explicit update rules of 1RSB-AMP together with the corresponding state evolution (1RSB-SE) equations. A detailed comparison shows that 1RSB-AMP and 1RSB-SE agree remarkably well at the macroscopic level, even in parameter regions where replica-symmetric (RS) AMP, termed RS-AMP, diverges and where the 1RSB description itself is not expected to be thermodynamically exact. Fixed-point analysis of 1RSB-SE reveals a phase diagram consisting of success, failure, and diverging phases, as in the RS case. However, the diverging-region boundary now depends on the Parisi parameter due to the 1RSB ansatz, and we propose a new criterion -- minimizing the size of the diverging region -- rather than the conventional zero-complexity condition, to determine its value. Combining this criterion with the nonconvexity-control (NCC) protocol proposed in a previous RS study improves the algorithmic limit of perfect reconstruction compared with RS-AMP. Numerical solutions of 1RSB-SE and experiments with 1RSB-AMP confirm that this improved limit is achieved in practice, though the gain is modest and remains slightly inferior to the Bayes-optimal threshold. We also report the behavior of thermodynamic quantities -- overlaps, free entropy, complexity, and the non-self-averaging susceptibility -- that characterize the 1RSB phase in this problem.
Neural Collapse in Cumulative Link Models for Ordinal Regression: An Analysis with Unconstrained Feature Model
Jun 06, 2025A phenomenon known as ''Neural Collapse (NC)'' in deep classification tasks, in which the penultimate-layer features and the final classifiers exhibit an extremely simple geometric structure, has recently attracted considerable attention, with the expectation that it can deepen our understanding of how deep neural networks behave. The Unconstrained Feature Model (UFM) has been proposed to explain NC theoretically, and there emerges a growing body of work that extends NC to tasks other than classification and leverages it for practical applications. In this study, we investigate whether a similar phenomenon arises in deep Ordinal Regression (OR) tasks, via combining the cumulative link model for OR and UFM. We show that a phenomenon we call Ordinal Neural Collapse (ONC) indeed emerges and is characterized by the following three properties: (ONC1) all optimal features in the same class collapse to their within-class mean when regularization is applied; (ONC2) these class means align with the classifier, meaning that they collapse onto a one-dimensional subspace; (ONC3) the optimal latent variables (corresponding to logits or preactivations in classification tasks) are aligned according to the class order, and in particular, in the zero-regularization limit, a highly local and simple geometric relationship emerges between the latent variables and the threshold values. We prove these properties analytically within the UFM framework with fixed threshold values and corroborate them empirically across a variety of datasets. We also discuss how these insights can be leveraged in OR, highlighting the use of fixed thresholds.
Analysis of High-dimensional Gaussian Labeled-unlabeled Mixture Model via Message-passing Algorithm
Nov 29, 2024Semi-supervised learning (SSL) is a machine learning methodology that leverages unlabeled data in conjunction with a limited amount of labeled data. Although SSL has been applied in various applications and its effectiveness has been empirically demonstrated, it is still not fully understood when and why SSL performs well. Some existing theoretical studies have attempted to address this issue by modeling classification problems using the so-called Gaussian Mixture Model (GMM). These studies provide notable and insightful interpretations. However, their analyses are focused on specific purposes, and a thorough investigation of the properties of GMM in the context of SSL has been lacking. In this paper, we conduct such a detailed analysis of the properties of the high-dimensional GMM for binary classification in the SSL setting. To this end, we employ the approximate message passing and state evolution methods, which are widely used in high-dimensional settings and originate from statistical mechanics. We deal with two estimation approaches: the Bayesian one and the l2-regularized maximum likelihood estimation (RMLE). We conduct a comprehensive comparison between these two approaches, examining aspects such as the global phase diagram, estimation error for the parameters, and prediction error for the labels. A specific comparison is made between the Bayes-optimal (BO) estimator and RMLE, as the BO setting provides optimal estimation performance and is ideal as a benchmark. Our analysis shows that with appropriate regularizations, RMLE can achieve near-optimal performance in terms of both the estimation error and prediction error, especially when there is a large amount of unlabeled data. These results demonstrate that the l2 regularization term plays an effective role in estimation and prediction in SSL approaches.
Transfer Learning in $\ell_1$ Regularized Regression: Hyperparameter Selection Strategy based on Sharp Asymptotic Analysis
Sep 26, 2024Transfer learning techniques aim to leverage information from multiple related datasets to enhance prediction quality against a target dataset. Such methods have been adopted in the context of high-dimensional sparse regression, and some Lasso-based algorithms have been invented: Trans-Lasso and Pretraining Lasso are such examples. These algorithms require the statistician to select hyperparameters that control the extent and type of information transfer from related datasets. However, selection strategies for these hyperparameters, as well as the impact of these choices on the algorithm's performance, have been largely unexplored. To address this, we conduct a thorough, precise study of the algorithm in a high-dimensional setting via an asymptotic analysis using the replica method. Our approach reveals a surprisingly simple behavior of the algorithm: Ignoring one of the two types of information transferred to the fine-tuning stage has little effect on generalization performance, implying that efforts for hyperparameter selection can be significantly reduced. Our theoretical findings are also empirically supported by real-world applications on the IMDb dataset.
When resampling/reweighting improves feature learning in imbalanced classification?: A toy-model study
Sep 09, 2024



A toy model of binary classification is studied with the aim of clarifying the class-wise resampling/reweighting effect on the feature learning performance under the presence of class imbalance. In the analysis, a high-dimensional limit of the feature is taken while keeping the dataset size ratio against the feature dimension finite and the non-rigorous replica method from statistical mechanics is employed. The result shows that there exists a case in which the no resampling/reweighting situation gives the best feature learning performance irrespectively of the choice of losses or classifiers, supporting recent findings in Cao et al. (2019); Kang et al. (2019). It is also revealed that the key of the result is the symmetry of the loss and the problem setting. Inspired by this, we propose a further simplified model exhibiting the same property for the multiclass setting. These clarify when the class-wise resampling/reweighting becomes effective in imbalanced classification.
On Model Selection Consistency of Lasso for High-Dimensional Ising Models on Tree-like Graphs
Oct 16, 2021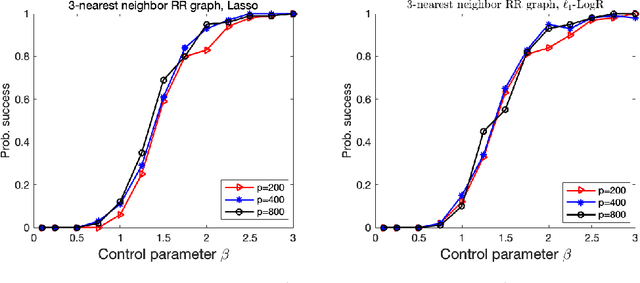

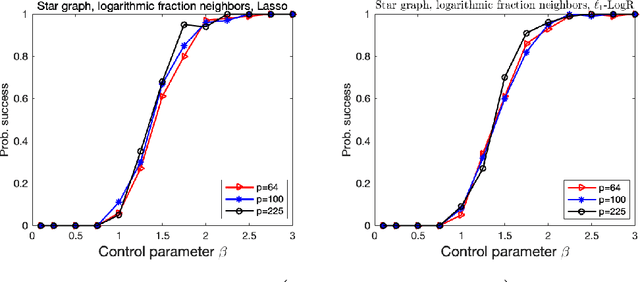
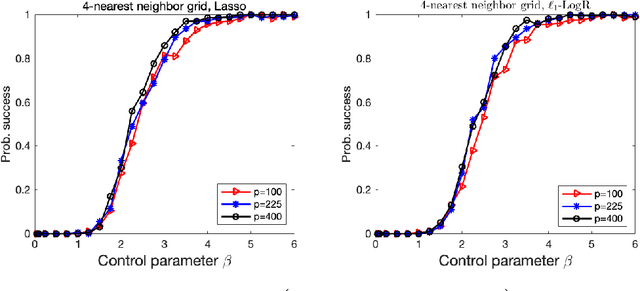
We consider the problem of high-dimensional Ising model selection using neighborhood-based least absolute shrinkage and selection operator (Lasso). It is rigorously proved that under some mild coherence conditions on the population covariance matrix of the Ising model, consistent model selection can be achieved with sample sizes $n=\Omega{(d^3\log{p})}$ for any tree-like graph in the paramagnetic phase, where $p$ is the number of variables and $d$ is the maximum node degree. When the same conditions are imposed directly on the sample covariance matrices, it is shown that a reduced sample size $n=\Omega{(d^2\log{p})}$ suffices. The obtained sufficient conditions for consistent model selection with Lasso are the same in the scaling of the sample complexity as that of $\ell_1$-regularized logistic regression. Given the popularity and efficiency of Lasso, our rigorous analysis provides a theoretical backing for its practical use in Ising model selection.
Ising Model Selection Using $\ell_{1}$-Regularized Linear Regression
Feb 08, 2021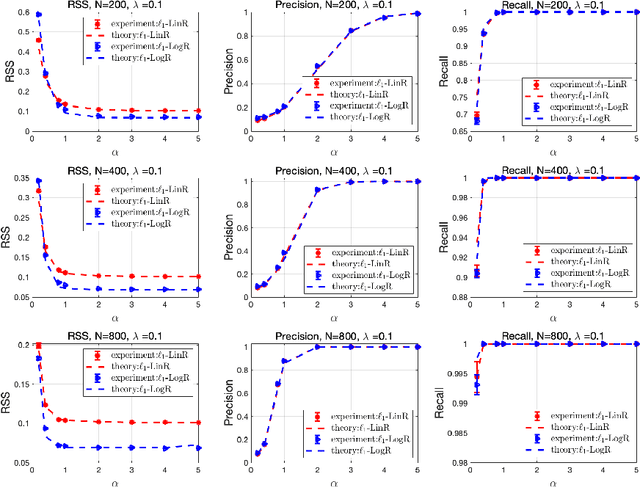

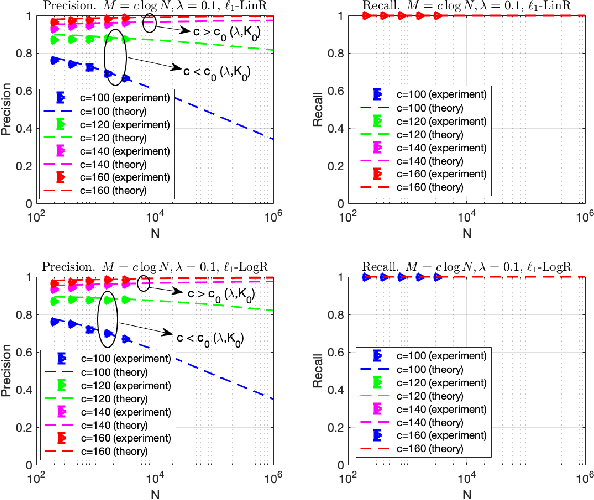
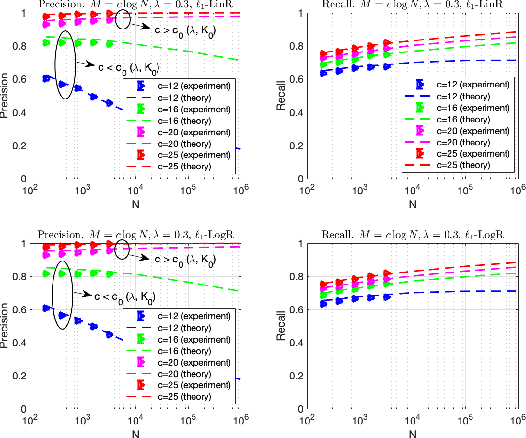
We theoretically investigate the performance of $\ell_{1}$-regularized linear regression ($\ell_1$-LinR) for the problem of Ising model selection using the replica method from statistical mechanics. The regular random graph is considered under paramagnetic assumption. Our results show that despite model misspecification, the $\ell_1$-LinR estimator can successfully recover the graph structure of the Ising model with $N$ variables using $M=\mathcal{O}\left(\log N\right)$ samples, which is of the same order as that of $\ell_{1}$-regularized logistic regression. Moreover, we provide a computationally efficient method to accurately predict the non-asymptotic performance of the $\ell_1$-LinR estimator with moderate $M$ and $N$. Simulations show an excellent agreement between theoretical predictions and experimental results, which supports our findings.
Perfect Reconstruction of Sparse Signals via Greedy Monte-Carlo Search
Aug 24, 2020
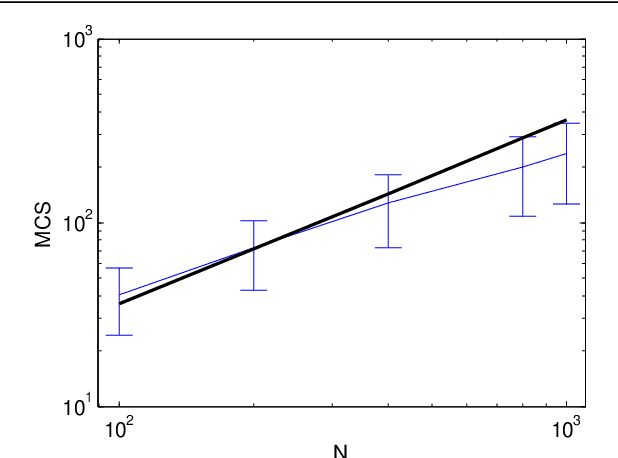


We propose a Monte-Carlo-based method for reconstructing sparse signals in the formulation of sparse linear regression in a high-dimensional setting. The basic idea of this algorithm is to explicitly select variables or covariates to represent a given data vector or responses and accept randomly generated updates of that selection if and only if the energy or cost function decreases. This algorithm is called the greedy Monte-Carlo (GMC) search algorithm. Its performance is examined via numerical experiments, which suggests that in the noiseless case, GMC can achieve perfect reconstruction in undersampling situations of a reasonable level: it can outperform the $\ell_1$ relaxation but does not reach the algorithmic limit of MC-based methods theoretically clarified by an earlier analysis. Additionally, an experiment on a real-world dataset supports the practicality of GMC.
Structure Learning in Inverse Ising Problems Using $\ell_2$-Regularized Linear Estimator
Aug 19, 2020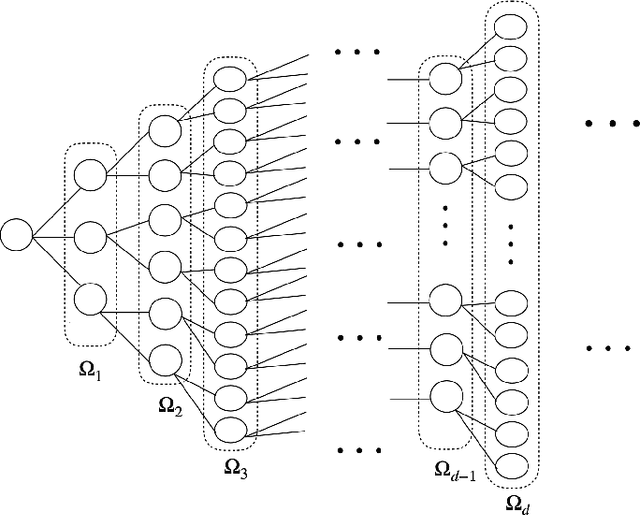
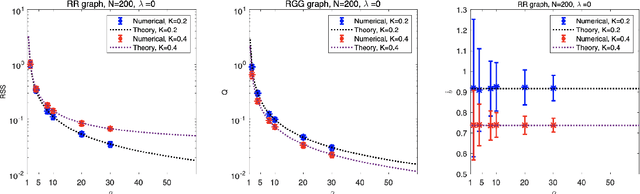
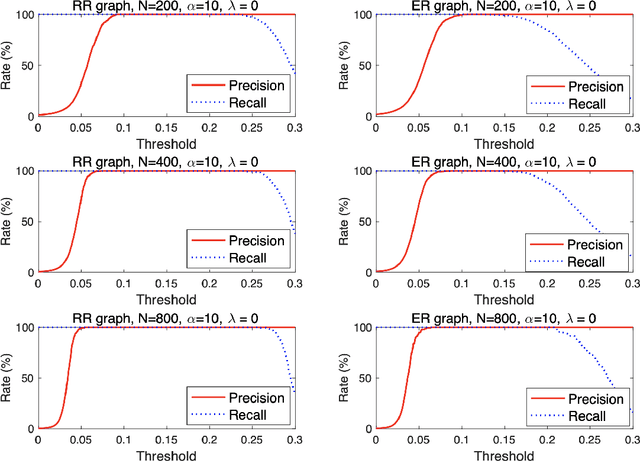
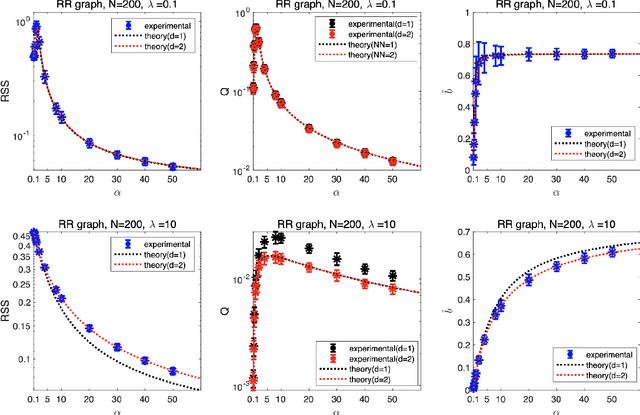
Inferring interaction parameters from observed data is a ubiquitous requirement in various fields of science and engineering. Recent studies have shown that the pseudolikelihood (PL) method is highly effective in meeting this requirement even though the maximum likelihood method is computationally intractable when used directly. To the best of our knowledge, most existing studies assume that the postulated model used in the inference stage covers the true model that generates the data. However, such an assumption does not necessarily hold in practical situations. From this perspective, we discuss the utility of the PL method in model mismatch cases. Specifically, we examine the inference performance of the PL method when $\ell_2$-regularized (ridge) linear regression is applied to data generated from sparse Boltzmann machines of Ising spins using methods of statistical mechanics. Our analysis indicates that despite the model mismatch, one can perfectly identify the network topology using naive linear regression without regularization when the dataset size $M$ is greater than the number of Ising spins, $N$. Further, even when $M < N$, perfect identification is possible using a two-stage estimator with much better quantitative performance compared to naive usage of the PL method. Results of extensive numerical experiments support our findings.